終于把機器學習中的類別不平衡搞懂了!!
今天給大家分享機器學習中的一個關鍵概念,類別不平衡。

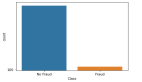
類別不平衡指的是在分類問題中,不同類別的數據樣本數量相差懸殊的情況。
在機器學習和深度學習的應用中,類別不平衡是一個常見的問題,尤其是在一些實際場景中,某些類別的數據相對較少,而其他類別的數據較多。例如,在醫療診斷中,患病的樣本可能遠遠少于健康的樣本,或者在欺詐檢測中,欺詐交易的數量通常少于正常交易。
類別不平衡的問題會導致分類器在訓練過程中傾向于預測數量較多的類別,而忽視數量較少的類別,進而影響分類結果的準確性和泛化能力。

類別不平衡的影響
- 模型偏向多數類
大多數機器學習算法(如邏輯回歸、決策樹、SVM等)往往會傾向于預測樣本數目較多的類別,因為這可以最小化整體的錯誤率。
這樣,模型可能會忽略少數類的樣本,從而影響模型的泛化能力和對少數類的識別能力。 - 評價指標失真
在類別不平衡的數據集上,準確率(accuracy)通常不是一個有效的評估指標。即使模型完全忽略少數類,仍然可能獲得較高的準確率(因為多數類的預測正確率較高)。因此,需要使用其他評價指標(如精確率、召回率、F1值、ROC-AUC等)來全面評估模型性能。 - 忽略少數類
對于一些特定任務,少數類可能非常重要,例如在疾病診斷、欺詐檢測等場景中,少數類(如病人或欺詐交易)通常是更為關注的對象。忽略少數類會導致任務無法實現預期效果。
處理類別不平衡的常見方法
過采樣
過采樣是通過增加少數類樣本的數量,使得少數類和多數類的樣本數量達到平衡。
常用的過采樣方法有以下幾種:
隨機過采樣
通過簡單地復制少數類樣本,來增加少數類的數量。
優缺點
- 優點:實現簡單,能快速增加少數類樣本。
- 缺點:復制樣本可能導致過擬合,因為模型可能會多次看到相同的樣本,無法學到新知識。
from imblearn.over_sampling import RandomOverSampler
from sklearn.datasets import make_classification
from collections import Counter
# 創建一個不平衡的數據集
X, y = make_classification(n_samples=1000, n_features=20, n_classes=2,
weights=[0.1, 0.9], random_state=42)
print(f"原始數據集的類別分布: {Counter(y)}")
# 使用隨機過采樣進行數據平衡
ros = RandomOverSampler(random_state=42)
X_resampled, y_resampled = ros.fit_resample(X, y)
print(f"過采樣后的類別分布: {Counter(y_resampled)}")SMOTE
SMOTE 是最常用的過采樣技術,它通過在少數類樣本之間進行插值,生成新的合成樣本。
原理
SMOTE 通過在特征空間中選擇一個少數類樣本及其最近鄰樣本,然后在它們之間進行插值來創建新的樣本。
這些新合成的樣本是對現有樣本的一種變換,能夠增加少數類的多樣性。
- 隨機選擇一個少數類樣本。
- 尋找其 k 個最近鄰居。
- 通過在選定的實例和隨機選擇的鄰居之間進行插值來生成合成實例。

優缺點
- 優點:通過合成樣本,增強了數據的多樣性,并且減少了過擬合的風險。
- 缺點:生成的合成樣本可能不具有代表性,尤其在特征空間復雜時。
from imblearn.over_sampling import SMOTE
from sklearn.datasets import make_classification
from collections import Counter
# 創建一個不平衡的數據集
X, y = make_classification(n_samples=1000, n_features=20, n_classes=2,
weights=[0.1, 0.9], random_state=42)
print(f"原始數據集的類別分布: {Counter(y)}")
# 使用 SMOTE 進行數據平衡
smote = SMOTE(random_state=42)
X_resampled, y_resampled = smote.fit_resample(X, y)
print(f"SMOTE過采樣后的類別分布: {Counter(y_resampled)}")ADASYN
ADASYN 是對 SMOTE 的改進,旨在通過更多地生成那些分類器難以區分的少數類樣本來增強數據集。
它的基本思想是:在那些靠近決策邊界的少數類樣本生成更多的合成樣本,減少生成容易分類的樣本。
優點
比 SMOTE 更加關注決策邊界附近的難分類樣本,可以提升模型在這些區域的表現。
from imblearn.over_sampling import ADASYN
from sklearn.datasets import make_classification
from collections import Counter
# 創建一個不平衡的數據集
X, y = make_classification(n_samples=1000, n_features=20, n_classes=2,
weights=[0.1, 0.9], random_state=42)
print(f"原始數據集的類別分布: {Counter(y)}")
# 使用 ADASYN 進行數據平衡
adasyn = ADASYN(random_state=42)
X_resampled, y_resampled = adasyn.fit_resample(X, y)
print(f"ADASYN過采樣后的類別分布: {Counter(y_resampled)}")欠采樣
欠采樣是通過減少多數類樣本的數量,來平衡類別之間的樣本比例。
常見的欠采樣方法有:
隨機欠采樣
通過隨機刪除多數類樣本,來減少多數類樣本的數量。
優缺點
優點:能夠顯著減少訓練數據的規模,降低計算開銷。
缺點:丟失了大量的多數類信息,可能導致欠擬合,特別是在多數類樣本本身數量龐大的情況下。
from imblearn.under_sampling import RandomUnderSampler
from sklearn.datasets import make_classification
from collections import Counter
# 創建一個不平衡的數據集
X, y = make_classification(n_samples=1000, n_features=20, n_classes=2,
weights=[0.1, 0.9], random_state=42)
print(f"原始數據集的類別分布: {Counter(y)}")
# 使用隨機欠采樣進行數據平衡
rus = RandomUnderSampler(random_state=42)
X_resampled, y_resampled = rus.fit_resample(X, y)
print(f"欠采樣后的類別分布: {Counter(y_resampled)}")Tomek Links
Tomek Links 是一種欠采樣方法,通過識別邊界上的實例對(即少數類樣本和多數類樣本非常接近的樣本對),并刪除那些多數類樣本。這有助于清除數據集中的噪聲,并提升分類效果。

優缺點
- 優點:有助于消除噪聲樣本,并清晰定義決策邊界。
- 缺點:可能會刪除一些重要的多數類樣本,影響數據的完整性。
from imblearn.under_sampling import TomekLinks
from sklearn.datasets import make_classification
from collections import Counter
# 創建一個不平衡的數據集
X, y = make_classification(n_samples=1000, n_features=20, n_classes=2,
weights=[0.1, 0.9], random_state=42)
print(f"原始數據集的類別分布: {Counter(y)}")
# 使用 Tomek Links 進行欠采樣
tomek = TomekLinks()
X_resampled, y_resampled = tomek.fit_resample(X, y)
print(f"Tomek Links處理后的類別分布: {Counter(y_resampled)}")