機(jī)器學(xué)習(xí)中如何處理不平衡數(shù)據(jù)?
假設(shè)老板讓你創(chuàng)建一個(gè)模型——基于可用的各種測量手段來預(yù)測產(chǎn)品是否有缺陷。你使用自己喜歡的分類器在數(shù)據(jù)上進(jìn)行訓(xùn)練后,準(zhǔn)確率達(dá)到了 96.2%!
你的老板很驚訝,決定不再測試直接使用你的模型。幾個(gè)星期后,他進(jìn)入你的辦公室,拍桌子告訴你你的模型完全沒用,一個(gè)有缺陷的產(chǎn)品都沒發(fā)現(xiàn)。
經(jīng)過一番調(diào)查,你發(fā)現(xiàn)盡管你們公司的產(chǎn)品中大約有 3.8%的存在缺陷,但你的模型卻總是回答「沒有缺陷」,也因此準(zhǔn)確率達(dá)到 96.2%。你之所以獲得這種「naive」的結(jié)果,原因很可能是你使用的訓(xùn)練數(shù)據(jù)是不平衡數(shù)據(jù)集。
本文將介紹解決不平衡數(shù)據(jù)分類問題的多種方法。
首先我們將概述檢測」naive behaviour」的不同評估指標(biāo);然后討論重新處理數(shù)據(jù)集的多種方法,并展示這些方法可能會(huì)產(chǎn)生的誤導(dǎo);***,我們將證明重新處理數(shù)據(jù)集大多數(shù)情況下是繼續(xù)建模的***方式。
注:帶(∞)符號(hào)的章節(jié)包含較多數(shù)學(xué)細(xì)節(jié),可以跳過,不影響對本文的整體理解。此外,本文大部分內(nèi)容考慮兩個(gè)類的分類問題,但推理可以很容易地?cái)U(kuò)展到多類別的情況。
一、檢測「naive behaviour」
我們先來看幾種評估分類器的方法,以確保檢測出「naive behaviour」。如前所述,準(zhǔn)確率雖然是一個(gè)重要且不可忽視的指標(biāo),但卻可能產(chǎn)生誤導(dǎo),因此應(yīng)當(dāng)謹(jǐn)慎使用,***與其他指標(biāo)一起使用。我們先看看還有哪些指標(biāo)。
1. 混淆矩陣、精度、召回率和 F1
在處理分類問題時(shí),一個(gè)很好且很簡單的指標(biāo)是混淆矩陣(confusion matrix)。該指標(biāo)可以很好地概述模型的運(yùn)行情況。因此,它是任何分類模型評估的一個(gè)很好的起點(diǎn)。下圖總結(jié)了從混淆矩陣中可以導(dǎo)出的大部分指標(biāo):
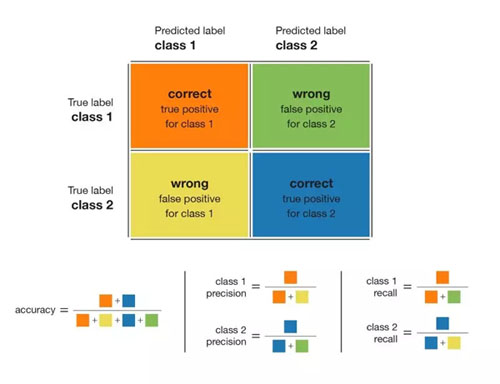
混淆矩陣以及可從中導(dǎo)出的指標(biāo)
讓我們簡單解釋一下:所謂準(zhǔn)確率(accuracy)就是正確預(yù)測的數(shù)量除以預(yù)測總數(shù);類別精度(precision)表示當(dāng)模型判斷一個(gè)點(diǎn)屬于該類的情況下,判斷結(jié)果的可信程度。類別召回率(recall)表示模型能夠檢測到該類的比率。類別的 F1 分?jǐn)?shù)是精度和召回率的調(diào)和平均值(F1 = 2×precision×recall / (precision + recall)),F(xiàn)1 能夠?qū)⒁粋€(gè)類的精度和召回率結(jié)合在同一個(gè)指標(biāo)當(dāng)中。
對于一個(gè)給定類,精度和召回率的不同組合如下:
- 高精度+高召回率:模型能夠很好地檢測該類;
- 高精度+低召回率:模型不能很好地檢測該類,但是在它檢測到這個(gè)類時(shí),判斷結(jié)果是高度可信的;
- 低精度+高召回率:模型能夠很好地檢測該類,但檢測結(jié)果中也包含其他類的點(diǎn);
- 低精度+低召回率:模型不能很好地檢測該類。
我們舉個(gè)例子,如下圖所示,我們有 10000 個(gè)產(chǎn)品的混淆矩陣:
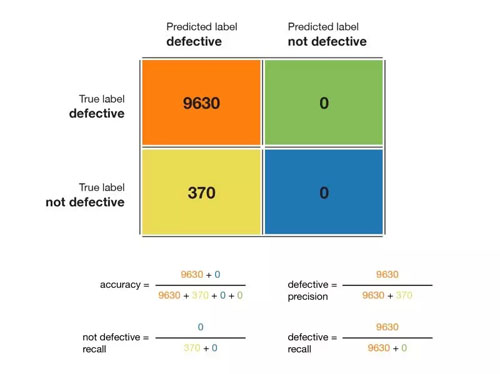
文章開頭示例的混淆矩陣。注意「not defective」精度不可計(jì)算。
根據(jù)上圖,準(zhǔn)確率為 96.2%,無缺陷類的精度為 96.2%,有缺陷類的精度不可計(jì)算;無缺陷類的召回率為 1.0(這很好,所有無缺陷的產(chǎn)品都會(huì)被檢測出來),有缺陷類的召回率是 0(這很糟糕,沒有檢測到有缺陷的產(chǎn)品)。因此我們可以得出結(jié)論,這個(gè)模型對有缺陷類是不友好的。有缺陷產(chǎn)品的 F1 分?jǐn)?shù)不可計(jì)算,無缺陷產(chǎn)品的 F1 分?jǐn)?shù)是 0.981。在這個(gè)例子中,如果我們查看了混淆矩陣,就會(huì)重新考慮我們的模型或目標(biāo),也就不會(huì)有前面的那種無用模型了。
2. ROC 和 AUROC
另外一個(gè)有趣的指標(biāo)是ROC 曲線(Receiver Operating Characteristic),其定義和給定類相關(guān)(下文用 C 表示類別)。
假設(shè)對于給定點(diǎn) x,我們的模型輸出該點(diǎn)屬于類別 C 的概率為:P(C | x)。基于這個(gè)概率,我們定義一個(gè)決策規(guī)則,即當(dāng)且僅當(dāng) P(C | x)≥T 時(shí),x 屬于類別 C,其中 T 是定義決策規(guī)則的給定閾值。如果 T = 1,則僅當(dāng)模型 100%可信時(shí),才將該點(diǎn)標(biāo)注為類別 C。如果 T = 0,則每個(gè)點(diǎn)都標(biāo)注為類別 C。
閾值 T 從 0 到 1 之間的每個(gè)值都會(huì)生成一個(gè)點(diǎn) (false positive, true positive),ROC 曲線就是當(dāng) T 從 1 變化到 0 所產(chǎn)生點(diǎn)的集合所描述的曲線。該曲線從點(diǎn) (0,0) 開始,在點(diǎn) (1,1) 處結(jié)束,且單調(diào)增加。好模型的 ROC 曲線會(huì)快速從 0 增加到 1(這意味著必須犧牲一點(diǎn)精度才能獲得高召回率)。
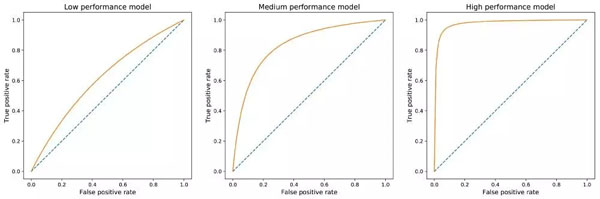
有效性不同的模型的 ROC 曲線圖示。左側(cè)模型必須犧牲很多精度才能獲得高召回率;右側(cè)模型非常有效,可以在保持高精度的同時(shí)達(dá)到高召回率。
基于 ROC 曲線,我們可以構(gòu)建另一個(gè)更容易使用的指標(biāo)來評估模型:AUROC(Area Under the ROC),即 ROC 曲線下面積。可以看出,AUROC 在***情況下將趨近于 1.0,而在最壞情況下降趨向于 0.5。同樣,一個(gè)好的 AUROC 分?jǐn)?shù)意味著我們評估的模型并沒有為獲得某個(gè)類(通常是少數(shù)類)的高召回率而犧牲很多精度。
二、究竟出了什么問題?
1. 不平衡案例
在解決問題之前,我們要更好地理解問題。為此我們考慮一個(gè)非常簡單的例子。假設(shè)我們有兩個(gè)類:C0 和 C1,其中 C0 的點(diǎn)遵循均值為 0、方差為 4 的一維高斯分布;C1 的點(diǎn)遵循均值為 2 、方差為 1 的一維高斯分布。假設(shè)數(shù)據(jù)集中 90% 的點(diǎn)來自 C0,其余 10% 來自 C1。下圖是包含 50 個(gè)點(diǎn)的數(shù)據(jù)集按照上述假設(shè)的理論分布情況:
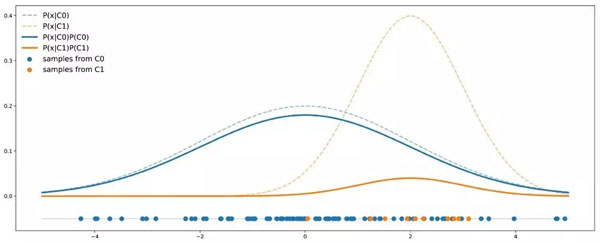
不平衡案例圖示。虛線表示每個(gè)類的概率密度,實(shí)線加入了對數(shù)據(jù)比例的考量。
在這個(gè)例子中,我們可以看到 C0 的曲線總是在 C1 曲線之上,因此對于任意給定點(diǎn),它出自 C0 類的概率總是大于出自 C1 類的概率。用貝葉斯公式來表示,即:
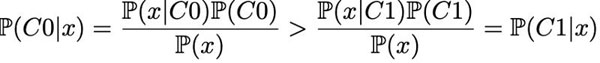
在這里我們可以清楚地看到先驗(yàn)概率的影響,以及它如何導(dǎo)致一個(gè)類比另一個(gè)類更容易發(fā)生的情況。這就意味著,即使從理論層面來看,只有當(dāng)分類器每次判斷結(jié)果都是 C0 時(shí)準(zhǔn)確率才會(huì)***。所以假如分類器的目標(biāo)就是獲得***準(zhǔn)確率,那么我們根本就不用訓(xùn)練,直接全部判為 C0 即可。
2. 關(guān)于可分離性
在前面的例子中,我們可以觀察到兩個(gè)類似乎不能很好地分離開(彼此相距不遠(yuǎn))。但是,數(shù)據(jù)不平衡不代表兩個(gè)類無法很好地分離。例如,我們?nèi)约僭O(shè)數(shù)據(jù)集中 C0、C1 的比例分別為 90% 和 10%;但 C0 遵循均值為 0 、方差為 4 的一維高斯分布、C1 遵循均值為 10 、方差為 1 的一維高斯分布。如下圖所示:

在這個(gè)例子中,如果均值差別足夠大,即使不平衡類也可以分離開來。
在這里我們看到,與前一種情況相反,C0 曲線并不總是高于 C1 曲線,因此有些點(diǎn)出自 C1 類的概率就會(huì)高于出自 C0 的概率。在這種情況下,兩個(gè)類分離得足夠開,足以補(bǔ)償不平衡,分類器不一定總是得到 C0 的結(jié)果。
3. 理論最小誤差概率(∞)
我們應(yīng)當(dāng)明白這一點(diǎn),分類器具有理論意義上的最小誤差概率。對于本文所討論的單特征二分類分類器,用圖表來看的話,理論最小誤差概率是由兩條曲線最小值下的面積給出的:
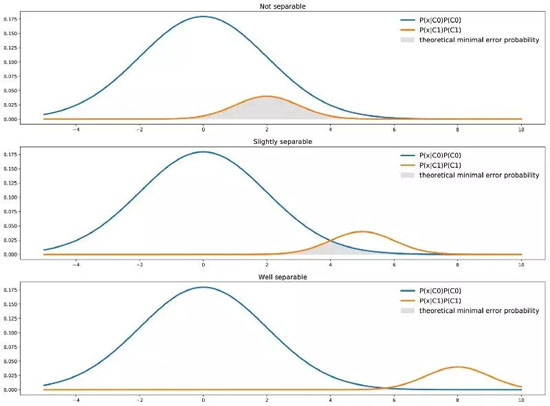
兩個(gè)類在不同分離度下的理論最小誤差
我們可以用公式的形式來表示。實(shí)際上,從理論的角度來看,***的分類器將從兩個(gè)類中選擇點(diǎn) x 最有可能屬于的類。這自然就意味著對于給定的點(diǎn) x,***的理論誤差概率由這兩個(gè)類可能性較小的一個(gè)給出,即
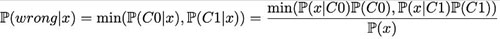
然后我們可以對全體進(jìn)行積分,得到總誤差概率:
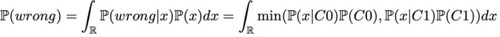
即上圖中兩條曲線最小值下區(qū)域的面積。
三、重新處理數(shù)據(jù)集并不總是解決方案
面對不平衡數(shù)據(jù)集,我們的***個(gè)反應(yīng)可能會(huì)認(rèn)為這個(gè)數(shù)據(jù)沒有代表現(xiàn)實(shí)。如果這是正確的,也就是說,實(shí)際數(shù)據(jù)應(yīng)該是(或幾乎是)平衡的,但由于我們采集數(shù)據(jù)時(shí)的方法問題造成數(shù)據(jù)存在比例偏差。因此我們必須嘗試收集更具代表性的數(shù)據(jù)。
在接下來的兩個(gè)小節(jié)里,我們將簡單介紹一些常用于解決不平衡類以及處理數(shù)據(jù)集本身的方法,特別是我們將討論欠采樣(undersampling)、過采樣(oversampling)、生成合成數(shù)據(jù)的風(fēng)險(xiǎn)及好處。
1. 欠采樣、過采樣和生成合成數(shù)據(jù)
這三種方法通常在訓(xùn)練分類器之前使用以平衡數(shù)據(jù)集。簡單來說:
- 欠采樣:從樣本較多的類中再抽取,僅保留這些樣本點(diǎn)的一部分;
- 過采樣:復(fù)制少數(shù)類中的一些點(diǎn),以增加其基數(shù);
- 生成合成數(shù)據(jù):從少數(shù)類創(chuàng)建新的合成點(diǎn),以增加其基數(shù)。
所有這些方法目的只有一個(gè):重新平衡(部分或全部)數(shù)據(jù)集。但是我們應(yīng)該重新平衡數(shù)據(jù)集來獲得數(shù)據(jù)量相同的兩個(gè)類嗎?或者樣本較多的類應(yīng)該保持***的代表性嗎?如果是這樣,我們應(yīng)以什么樣的比例來重新平衡呢?
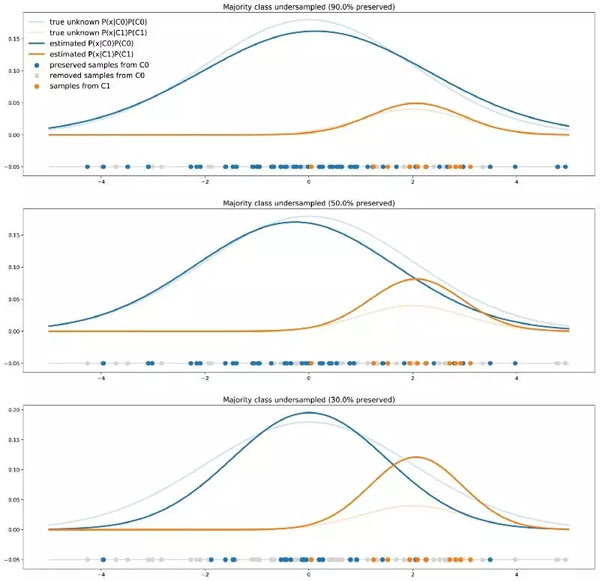
不同程度的多數(shù)類欠采樣對模型決策的影響
當(dāng)使用重采樣方法(例如從 C0 獲得的數(shù)據(jù)多于從 C1 獲得的數(shù)據(jù))時(shí),我們在訓(xùn)練過程向分類器顯示了兩個(gè)類的錯(cuò)誤比例。以這種方式學(xué)得的分類器在未來實(shí)際測試數(shù)據(jù)上得到的準(zhǔn)確率甚至比在未改變數(shù)據(jù)集上訓(xùn)練的分類器準(zhǔn)確率還低。實(shí)際上,類的真實(shí)比例對于分類新的點(diǎn)非常重要,而這一信息在重新采樣數(shù)據(jù)集時(shí)被丟失了。
因此,即使不完全拒絕這些方法,我們也應(yīng)當(dāng)謹(jǐn)慎使用它們:有目的地選擇新的比例可以導(dǎo)出一些相關(guān)的方法(下節(jié)將會(huì)講),但如果沒有進(jìn)一步考慮問題的實(shí)質(zhì)而只是將類進(jìn)行重新平衡,那么這個(gè)過程可能毫無意義。總結(jié)來講,當(dāng)我們采用重采樣的方法修改數(shù)據(jù)集時(shí),我們正在改變事實(shí),因此需要小心并記住這對分類器輸出結(jié)果意味著什么。
2. 添加額外特征
重采樣數(shù)據(jù)集(修改類比例)是好是壞取決于分類器的目的。如果兩個(gè)類是不平衡、不可分離的,且我們的目標(biāo)是獲得***準(zhǔn)確率,那么我們獲得的分類器只會(huì)將數(shù)據(jù)點(diǎn)分到一個(gè)類中;不過這不是問題,而只是一個(gè)事實(shí):針對這些變量,已經(jīng)沒有其他更好的選擇了。
除了重采樣外,我們還可以在數(shù)據(jù)集中添加一個(gè)或多個(gè)其他特征,使數(shù)據(jù)集更加豐富,這樣我們可能獲得更好的準(zhǔn)確率結(jié)果。回到剛才的例子(兩個(gè)類無法很好地分離開來),我們附加一個(gè)新的特征幫助分離兩個(gè)類,如下圖所示:
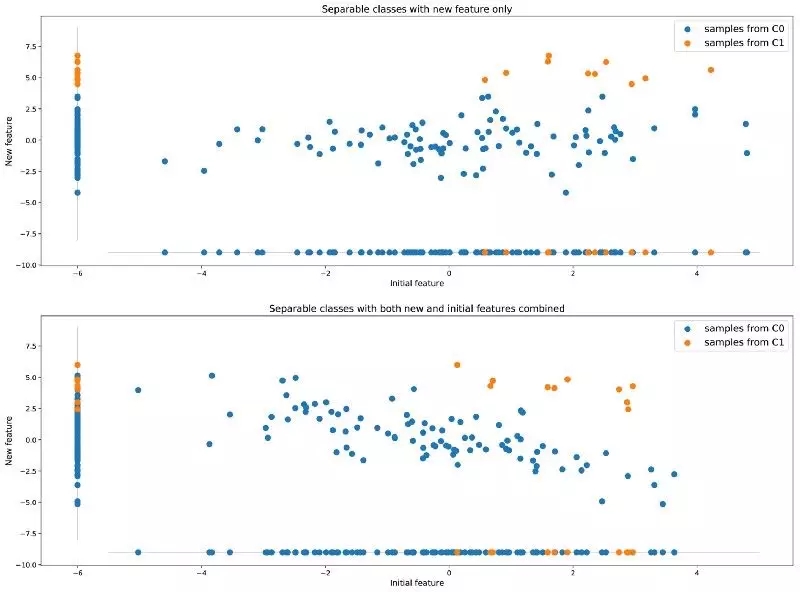
尋找附加特征可以將原本不能分離的類分離開
與前一小節(jié)提到的重采樣的方法相比,這種方法會(huì)使用更多來自現(xiàn)實(shí)的信息豐富數(shù)據(jù),而不是改變數(shù)據(jù)的現(xiàn)實(shí)性。
四、重新解決問題更好
到目前為止,結(jié)論似乎令人失望:如果要求數(shù)據(jù)集代表真實(shí)數(shù)據(jù)而我們又無法獲得任何額外特征,這時(shí)候如果我們以***準(zhǔn)確率來評判分類器,那么我們得到的就是一個(gè)「naive behaviour」(判斷結(jié)果總是同一個(gè)類),這時(shí)候我們只好將之作為事實(shí)來接受。
但如果我們對這樣的結(jié)果不滿意呢?這就意味著,事實(shí)上我們的問題并沒有得到很好的表示(否則我們應(yīng)當(dāng)可以接受模型結(jié)果),因此我們應(yīng)該重新解決我們的問題,從而獲得期望結(jié)果。我們來看一個(gè)例子。
1. 基于成本的分類
結(jié)果不好的根本原因在于目標(biāo)函數(shù)沒有得到很好的定義。截至此時(shí),我們一直假設(shè)分類器具備高準(zhǔn)確率,同時(shí)假設(shè)兩類錯(cuò)誤(「假陽性」和「假陰性」)具有相同的成本(cost)。在我們的例子中,這意味著真實(shí)標(biāo)簽為 C1、預(yù)測結(jié)果為 C0 與真實(shí)標(biāo)簽為 C0、預(yù)測結(jié)果為 C1 一樣糟糕,錯(cuò)誤是對稱的。然而實(shí)際情況往往不是這樣。
讓我們考慮本文***個(gè)例子,關(guān)于有缺陷(C1)和無缺陷(C0)產(chǎn)品。可以想象,對公司而言,沒有檢測到有缺陷的產(chǎn)品的代價(jià)遠(yuǎn)遠(yuǎn)大于將無缺陷的產(chǎn)品標(biāo)注為有缺陷產(chǎn)品(如客戶服務(wù)成本、法律審判成本等)。因此在真實(shí)案例中,錯(cuò)誤的代價(jià)是不對稱的。
我們再更具體地考慮,假設(shè):
- 當(dāng)真實(shí)標(biāo)簽為 C1 而預(yù)測為 C0 時(shí)的成本為 P01
- 當(dāng)真實(shí)標(biāo)簽為 C0 而預(yù)測為 C1 時(shí)的成本為 P10
- 其中 P01 和 P10 滿足:0
接下來,我們可以重新定義目標(biāo)函數(shù):不再以***準(zhǔn)確率為目標(biāo),而是尋找較低的預(yù)測成本。
2. 理論最小成本 (∞)
從理論的角度來看,我們并不想最小化前文定義的誤差概率,而是最小化期望預(yù)測成本:

其中 C(.) 定義分類器函數(shù)。因此,如果我們想要最小化期望預(yù)測成本,理論***分類器 C(.) 最小化
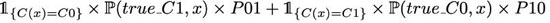
或者等價(jià)地,除以 x 的密度,C(.) 最小化
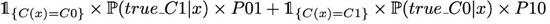
有了這個(gè)目標(biāo)函數(shù),從理論的角度來看,***的分類器應(yīng)該是這樣的:

注意:當(dāng)成本相等時(shí),我們就恢復(fù)了「經(jīng)典」分類器的表達(dá)式(只考慮準(zhǔn)確率)。
3. 概率閾值
在分類器中考慮成本的***種可行方法是在訓(xùn)練后進(jìn)行,也即按照基本的方法訓(xùn)練分類器,輸出如下概率:
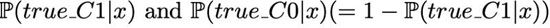
這里沒有考慮任何成本。然后,如果滿足下述條件
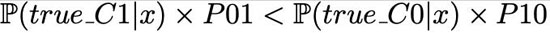
則預(yù)測類為 C0,否則為 C1。
這里,只要輸出給定點(diǎn)的每個(gè)類的概率,使用哪個(gè)分類器并不重要。在我們的例子中,我們可以在數(shù)據(jù)上擬合貝葉斯分類器,然后對獲得的概率重新加權(quán),根據(jù)成本誤差來調(diào)整分類器。
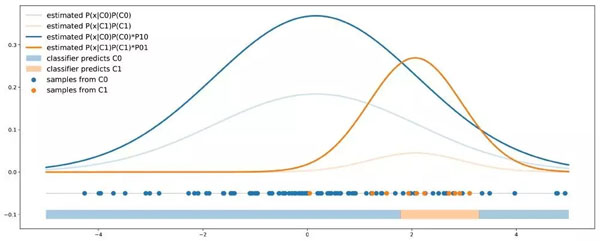
概率閾值方法:輸出概率被重新加權(quán),使得在最終決策規(guī)則中考慮成本。
4. 類重新加權(quán)
類重新加權(quán)(class reweight),即在分類器訓(xùn)練期間直接考慮成本誤差的不對稱性,這使每個(gè)類的輸出概率都嵌入成本誤差信息。然后這個(gè)概率將用于定義具有 0.5 閾值的分類規(guī)則。
對于某些模型(例如神經(jīng)網(wǎng)絡(luò)分類器),我們可以在訓(xùn)練期間通過調(diào)整目標(biāo)函數(shù)來考慮成本。我們?nèi)匀幌M诸惼鬏敵?/p>
但是這次的訓(xùn)練將使以下的成本函數(shù)最小化

對于一些其他模型(例如貝葉斯分類器),我們可以使用重采樣方法來偏置類的比例,以便在類比例內(nèi)輸入成本誤差信息。如果考慮成本 P01 和 P10(如 P01> P10),我們可以:
- 對少數(shù)類按照 P01 / P10 的比例進(jìn)行過采樣(少數(shù)類的基數(shù)乘以 P01 / P10);
- 對多數(shù)類按照 P10/P01 的比例進(jìn)行欠采樣(多數(shù)類的基數(shù)乘以 P10/P01)。
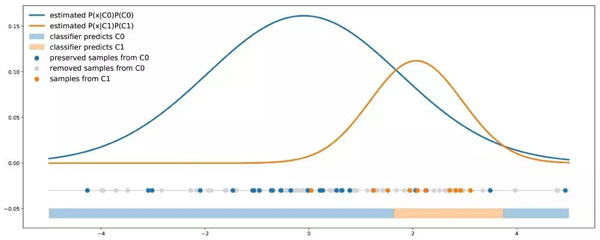
類重新加權(quán)方法:多數(shù)類按比例進(jìn)行欠采樣,這樣可以直接在類比例中引入成本信息。
五、總結(jié)
這篇文章的核心思想是:
- 當(dāng)我們使用機(jī)器學(xué)習(xí)算法時(shí),必須謹(jǐn)慎選擇模型的評估指標(biāo):我們必須使用那些能夠幫助更好了解模型在實(shí)現(xiàn)目標(biāo)方面的表現(xiàn)的指標(biāo);
- 在處理不平衡數(shù)據(jù)集時(shí),如果類與給定變量不能很好地分離,且我們的目標(biāo)是獲得***準(zhǔn)確率,那么得到的分類器可能只是預(yù)測結(jié)果為多數(shù)類的樸素分類器;
- 可以使用重采樣方法,但必須仔細(xì)考慮:這不應(yīng)該作為獨(dú)立的解決方案使用,而是必須與問題相結(jié)合以實(shí)現(xiàn)特定的目標(biāo);
- 重新處理問題本身通常是解決不平衡類問題的***方法:分類器和決策規(guī)則必須根據(jù)目標(biāo)進(jìn)行設(shè)置。
我們應(yīng)該注意,本文并未討論到所有技術(shù),如常用于批量訓(xùn)練分類器的「分層抽樣」技術(shù)。當(dāng)面對不平衡類問題時(shí),這種技術(shù)(通過消除批次內(nèi)的比例差異)可使訓(xùn)練過程更加穩(wěn)定。
***,我需要強(qiáng)調(diào)這篇文章的主要關(guān)鍵詞是「目標(biāo)」。準(zhǔn)確把握目標(biāo)將有助于克服不平衡數(shù)據(jù)集問題,并確保獲得***結(jié)果。準(zhǔn)確地定義目標(biāo)是萬事之首,是創(chuàng)建機(jī)器學(xué)習(xí)模型所需選擇的起點(diǎn)。
原文鏈接:
https://towardsdatascience.com/handling-imbalanced-datasets-in-machine-learning-7a0e84220f28
【本文是51CTO專欄機(jī)構(gòu)“機(jī)器之心”的原創(chuàng)譯文,微信公眾號(hào)“機(jī)器之心( id: almosthuman2014)”】