













終于把深度學習中的模型壓縮搞懂了!
作者:程序員小寒
在深度學習中,模型壓縮是減少模型大小、降低計算復雜度,同時盡可能保持模型性能的一類技術。它在移動端、嵌入式設備和邊緣計算等資源受限的環境中尤其重要。
今天給大家分享幾種常見的模型壓縮技術。

在深度學習中,模型壓縮是減少模型大小、降低計算復雜度,同時盡可能保持模型性能的一類技術。它在移動端、嵌入式設備和邊緣計算等資源受限的環境中尤其重要。
修剪
修剪是通過去除神經網絡中某些不重要的連接或神經元來減少模型的規模和計算需求。
修剪的目標是去除那些對網絡性能影響較小的參數,從而達到減少模型復雜度的效果。
常見修剪策略
- 權重修剪
通過移除那些對網絡輸出貢獻較小的權重來減少模型的大小。
這些權重可以通過設定一個閾值來判定:低于某個閾值的權重會被剪掉。 - 神經元修剪
修剪掉整個神經元或通道,這樣的修剪方法可以進一步減少計算量,尤其是對于卷積神經網絡(CNN)來說,移除不重要的特征圖通道會顯著降低計算復雜度。
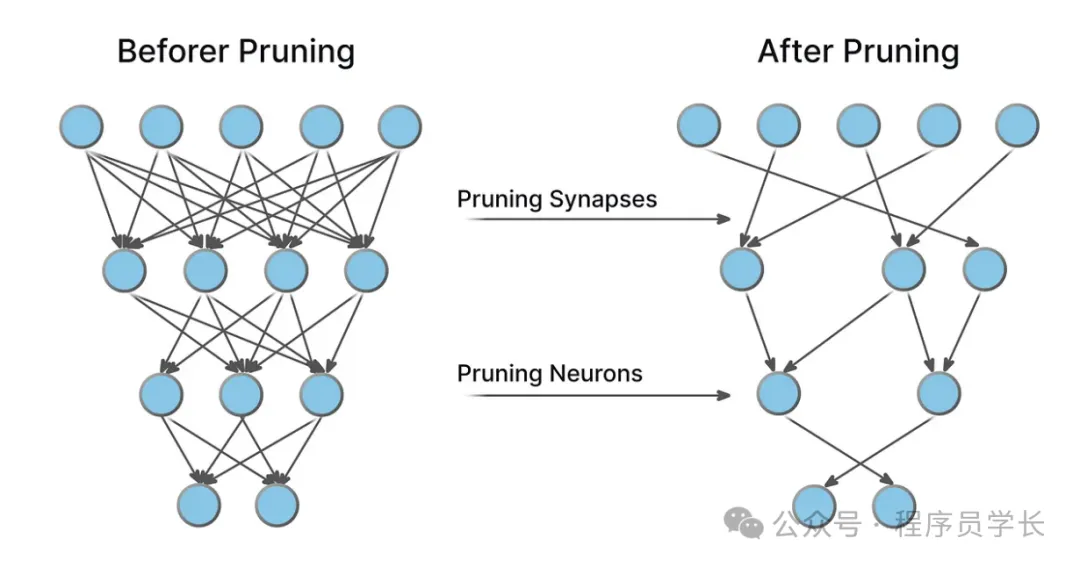
修剪的步驟通常是:
- 訓練原始模型
- 計算每個權重的重要性或每個神經元的激活度
- 去除不重要的權重或神經元
- 重新訓練,以恢復性能損失
優缺點
- 優點:減小模型尺寸,降低計算負擔,提升推理速度,尤其適合硬件加速。
- 缺點:修剪過度可能導致模型性能下降。需要精心設計修剪方案,以在壓縮和性能之間找到平衡。
import torch
import torch.nn as nn
import torch.nn.utils.prune as prune
# 定義一個簡單的神經網絡
class SimpleNet(nn.Module):
def __init__(self):
super(SimpleNet, self).__init__()
self.fc1 = nn.Linear(10, 10)
self.fc2 = nn.Linear(10, 2)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = self.fc2(x)
return x
# 創建網絡和輸入數據
model = SimpleNet()
input_data = torch.randn(1, 10)
# 修剪fc1層的20%的權重
prune.random_unstructured(model.fc1, name="weight", amount=0.2)
# 打印fc1層的權重,觀察被修剪掉的權重
print(model.fc1.weight)量化
量化是將浮點數表示的參數(如權重和激活)轉換為低精度數值表示(如整數)。
量化通常將模型從 32 位浮動點數轉換為更低精度的數據類型,如16位、8位或更低,這樣可以減少存儲需求和加速推理過程。
- 權重量化
將模型中的浮點數權重轉換為低精度整數。例如,將32位浮點數權重映射到8位整數,這樣就能大幅減少模型的存儲需求。 - 激活量化
對于激活值(神經網絡各層的輸出),也可以應用類似的量化策略。
常見的量化類型
- 后訓練量化:在模型訓練完成后進行量化,適用于已經訓練好的模型。
- 量化感知訓練:在訓練過程中加入量化過程,從而使得模型能夠適應低精度的計算。
量化不僅減小了模型大小,還可能加速模型的推理過程,尤其是在支持低精度計算的硬件上(如TPU、GPU等)。
優缺點
- 優點:大幅減少模型的存儲需求,加速推理過程。尤其在嵌入式設備和移動端設備上具有顯著的優勢。
- 缺點:量化可能導致一定的精度損失
import torch
import torch.nn as nn
import torch.quantization
# 定義一個簡單的模型
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.fc1 = nn.Linear(28 * 28, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = self.fc2(x)
return x
# 初始化模型
model = SimpleModel()
# 轉換模型為量化版本
model.eval() # 切換到評估模式
quantized_model = torch.quantization.quantize_dynamic(
model, {nn.Linear}, dtype=torch.qint8
)
# 查看量化后的模型
print(quantized_model)蒸餾
蒸餾是一種將大型、復雜模型的知識遷移到較小模型中的技術。
通常,蒸餾的過程是訓練一個小模型(學生模型)以模仿一個較大的、預先訓練好的模型(教師模型)的行為。
小模型通過學習教師模型的預測概率分布來獲取知識,而不僅僅是傳統的標簽信息。
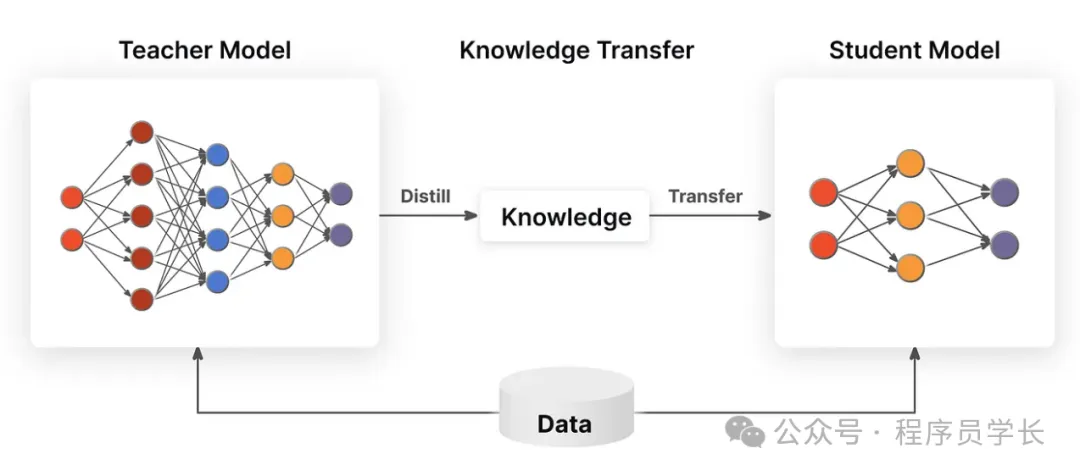
蒸餾的主要思想是:
- 教師模型輸出的類別概率包含了更多的“軟信息”,這些信息能夠幫助學生模型更好地學習一些復雜的模式。
- 學生模型通過與教師模型輸出的“軟標簽”進行學習,能夠在不完全依賴硬標簽的情況下獲取更多的信息,進而提高其性能。
蒸餾的步驟通常是:
- 訓練教師模型
首先,訓練一個大型且高性能的教師模型,這通常是一個深度神經網絡。 - 訓練學生模型
然后,訓練一個較小的學生模型,目標是通過最小化學生模型與教師模型在相同輸入上的輸出差異來進行訓練。學生模型不僅學習硬標簽(真實標簽),還學習教師模型的“軟標簽”。
通過蒸餾,學生模型可以獲得教師模型中蘊含的豐富知識,尤其是在教師模型能夠捕獲的復雜特征和模式方面,從而在保持較小規模的同時接近或達到教師模型的性能。
優缺點
- 優點:蒸餾可以顯著提高小型模型的性能,使其在壓縮后依然保持接近教師模型的精度,尤其在大型模型壓縮時表現出色。
- 缺點:蒸餾的一個挑戰是教師模型的選擇和訓練需要耗費大量的計算資源和時間。此外,蒸餾的效果可能會受到學生模型的限制,對于某些任務,學生模型的性能可能不容易達到教師模型的水平。
import torch
import torch.nn as nn
import torch.optim as optim
# 創建一個簡單的教師模型和學生模型
class TeacherNet(nn.Module):
def __init__(self):
super(TeacherNet, self).__init__()
self.fc = nn.Linear(10, 10)
def forward(self, x):
return self.fc(x)
class StudentNet(nn.Module):
def __init__(self):
super(StudentNet, self).__init__()
self.fc = nn.Linear(10, 10)
def forward(self, x):
return self.fc(x)
# 創建模型實例
teacher = TeacherNet()
student = StudentNet()
# 使用教師模型生成“軟標簽”
def distillation_loss(student_outputs, teacher_outputs, temperature=2.0):
# 使用溫度縮放進行蒸餾損失計算
loss = nn.KLDivLoss()(nn.functional.log_softmax(student_outputs / temperature, dim=1),
nn.functional.softmax(teacher_outputs / temperature, dim=1)) * (temperature ** 2)
return loss
# 簡單的訓練循環
optimizer = optim.SGD(student.parameters(), lr=0.1)
# 模擬訓練過程
for epoch in range(100):
# 輸入數據
inputs = torch.randn(32, 10) # 假設批次大小是32,輸入維度是10
teacher_outputs = teacher(inputs)
# 學生模型的輸出
student_outputs = student(inputs)
# 計算損失
loss = distillation_loss(student_outputs, teacher_outputs)
# 反向傳播
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 10 == 0:
print(f"Epoch [{epoch}/100], Loss: {loss.item()}")責任編輯:華軒
來源:
程序員學長






























