機器學習中樣本不平衡,怎么辦?

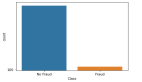
在銀行要判斷一個"新客戶是否會違約",通常不違約的人VS違約的人會是99:1的比例,真正違約的人 其實是非常少的。這種分類狀況下,即便模型什么也不做,全把所有人都當成不會違約的人,正確率也能有99%, 這使得模型評估指標變得毫無意義,根本無法達到我們的"要識別出會違約的人"的建模目的。
像這樣樣本不均衡等例子在生活中隨處可見。通常出現在異常檢測、客戶流失、罕見時間分析、發生低頻率事件等場景,具體如垃圾郵件等識別,信用卡征信問題、欺詐交易檢測、工廠中不良品檢測等。
在處理諸如此類的樣本不均衡的任務中,使用常規方法并不能達到實際業務需求,正確且盡可能多捕獲少數類樣本。因為樣本不均衡會使得分類模型存在很嚴重的偏向性。
本文中,介紹了在機器學習中樣本不平衡處理策略及常用方法和工具。
樣本不平衡分類
數據集中各個類別的樣本數量極不均衡,從數據規模上可分為:
- 大數據分布不均衡。整體數據規模大,小樣本類的占比較少,但小樣本也覆蓋了大部分或全部特征。
- 小數據分布不均衡。整體數據規模小,少數樣本比例的分類數量也少,導致特征分布嚴重不均衡。
樣本分布不均衡在于不同類別間的樣本比例差異,導致很難從樣本中提取規律。一般超過10倍就需要引起注意,20倍就一定要處理了。
樣本不平衡處理策略
擴大數據集
樣本不平衡時,可以增加包含一定比例小類樣本數據以擴大數據集,更多的數據往往戰勝更好的算法。因為機器學習是使用現有的數據多整個數據的分布進行估計,因此更多的數據往往能夠得到更多的分布信息,以及更好分布估計。
但有時在增加小類樣本數據的同時,也增加了大類數據,并不能顯著解決樣本不平衡問題。此時可以通過對大類樣本數據進行欠采樣,以放棄部分大類數據來解決。
重新選擇評價指標
準確度在類別均衡的分類任務中并不能有效地評價分類器模型,造成模型失效,甚至會誤導業務,造成較大損失。
最典型的評價指標即混淆矩陣Confusion Matrix:使用一個表格對分類器所預測的類別與其真實的類別的樣本統計,分別為:TP、FN、FP、TN。包括精確度Precision、召回率Recall、F1得分F1-Score等。
重采樣數據集
使用采樣sampling策略該減輕數據的不平衡程度。主要有兩種方法
- 對小類的數據樣本進行采樣來增加小類的數據樣本個數,即過采樣over-sampling
- 對大類的數據樣本進行采樣來減少該類數據樣本的個數,即欠采樣under-sampling
采樣算法往往很容易實現,并且其運行速度快,并且效果也不錯。在使用采樣策略時,可以考慮:
- 對大類下的樣本 (超過1萬, 十萬甚至更多) 進行欠采樣,即刪除部分樣本
- 對小類下的樣本 (不足1為甚至更少) 進行過采樣,即添加部分樣本的副本
- 嘗試隨機采樣與非隨機采樣兩種采樣方法
- 對各類別嘗試不同的采樣比例
- 同時使用過采樣與欠采樣
產生人工數據樣本
一種簡單的方法,對該類下的所有樣本的每個屬性特征的取值空間中隨機選取一個值以組成新的樣本,即屬性值隨機采樣。可以使用基于經驗對屬性值進行隨機采樣而構造新的人工樣本,或使用類似樸素貝葉斯方法假設各屬性之間互相獨立進行采樣,這樣便可得到更多的數據,但是無法保證屬性之前的線性關系(如果本身是存在的)。
有一個系統的構造人工數據樣本的方法SMOTE (Synthetic Minority Over-sampling Technique)。SMOTE是一種過采樣算法,它構造新的小類樣本而不是產生小類中已有的樣本的副本,即該算法構造的數據是新樣本,原數據集中不存在的。
該基于距離度量選擇小類別下兩個或者更多的相似樣本,然后選擇其中一個樣本,并隨機選擇一定數量的鄰居樣本對選擇的那個樣本的一個屬性增加噪聲,每次處理一個屬性。這樣就構造了更多的新生數據。
嘗試不同的分類算法
對待每一個機器學習任務都使用自己喜歡而熟悉的算法,相信很多人都會感同身受。但對待不同任務需要根據任務本身特點選用不同等算法,尤其對樣本不均衡等分類任務。應該使用不同的算法對其進行比較,因為不同的算法使用于不同的任務與數據。
決策樹往往在類別不均衡數據上表現不錯。它使用基于類變量的劃分規則去創建分類樹,因此可以強制地將不同類別的樣本分開。
對模型進行懲罰
你可以使用相同的分類算法,但是使用一個不同的角度,比如你的分類任務是識別那些小類,那么可以對分類器的小類樣本數據增加權值,降低大類樣本的權值,從而使得分類器將重點集中在小類樣本身上。
一個具體做法就是,在訓練分類器時,若分類器將小類樣本分錯時額外增加分類器一個小類樣本分錯代價,這個額外的代價可以使得分類器更加"關心"小類樣本。如penalized-SVM和penalized-LDA算法。
嘗試一個新的角度理解問題
我們可以從不同于分類的角度去解決數據不均衡性問題,我們可以把那些小類的樣本作為異常點outliers,因此該問題便轉化為異常點檢測anomaly detection與變化趨勢檢測問題change detection。
異常點檢測即是對那些罕見事件進行識別。如通過機器的部件的振動識別機器故障,又如通過系統調用序列識別惡意程序。這些事件相對于正常情況是很少見的。
變化趨勢檢測類似于異常點檢測,不同在于其通過檢測不尋常的變化趨勢來識別。如通過觀察用戶模式或銀行交易來檢測用戶行為的不尋常改變。
將小類樣本作為異常點這種思維的轉變,可以幫助考慮新的方法去分離或分類樣本。這兩種方法從不同的角度去思考,讓你嘗試新的方法去解決問題。
嘗試創新
仔細對你的問題進行分析與挖掘,是否可以將你的問題劃分成多個更小的問題,而這些小問題更容易解決。
處理樣本不平衡方法
通過抽樣
過采樣
又稱上采樣(over-sampling)通過增加分類中少數類樣本的數量來實現樣本不均衡。比較流行的算法有
The Synthetic Minority OverSampling Technique (SMOTE) 算法。
SMOTE: 對于少數類樣本a, 隨機選擇一個最近鄰的樣本b, 然后從a與b的連線上隨機選取一個點c作為新的少數類樣本。
語法:
imblearn.over_sampling.SMOTE(
sampling_strategy='auto',
random_state=None,
k_neighbors=5,
n_jobs=1)
舉例:
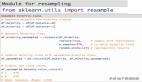
from collections import Counter
from sklearn.datasets import make_classification
from imblearn.over_sampling import SMOTE
# doctest: +NORMALIZE_WHITESPACE
X, y = make_classification(
n_classes=2,
class_sep=2,
weights=[0.1, 0.9],
n_informative=3,
n_redundant=1, flip_y=0,
n_features=20,
n_clusters_per_class=1,
n_samples=1000,
random_state=10)
print('Original dataset shape %s'
% Counter(y))
Original dataset shape Counter
({1: 900, 0: 100})
smote = SMOTE(random_state=42)
X_res, y_res = smote.fit_resample(X, y)
print('Resampled dataset shape %s'
% Counter(y_res))
Resampled dataset shape Counter
({0: 900, 1: 900})

SMOTE 變體 borderlineSMOTE、SVMSMOTE
相對于基本的SMOTE算法, 關注的是所有的少數類樣本, 這些情況可能會導致產生次優的決策函數, 因此SMOTE就產生了一些變體: 這些方法關注在最優化決策函數邊界的一些少數類樣本, 然后在最近鄰類的相反方向生成樣本。
這兩種類型的SMOTE使用的是危險樣本來生成新的樣本數據。
- borderlineSMOTE(kind='borderline-1')最近鄰中的隨機樣本b與該少數類樣本a來自于不同的類。
- borderlineSMOTE(kind='borderline-2')隨機樣本b可以是屬于任何一個類的樣本。
- SVMSMOTE()使用支持向量機分類器產生支持向量然后再生成新的少數類樣本。
少數類的樣本分為三類:
- 噪音樣本noise, 該少數類的所有最近鄰樣本都來自于不同于樣本a的其他類別。
- 危險樣本in danger, 至少一半的最近鄰樣本來自于同一類(不同于a的類別)。
- 安全樣本safe, 所有的最近鄰樣本都來自于同一個類。
語法:
imblearn.over_sampling.BorderlineSMOTE(sampling_strategy='auto',
random_state=None,
k_neighbors=5,
n_jobs=1, m_neighbors=10,
kind='borderline-1')
imblearn.over_sampling.SVMSMOTE(
sampling_strategy='auto',
random_state=None,
k_neighbors=5, n_jobs=1,
m_neighbors=10,
svm_estimator=None,
out_step=0.5)
Adaptive Synthetic (ADASYN)自適應合成上采樣
ADASYN: 關注的是在那些基于K最近鄰分類器被錯誤分類的原始樣本附近生成新的少數類樣本。
語法:
imblearn.over_sampling.ADASYN(
sampling_strategy='auto',
random_state=None,
n_neighbors=5, n_jobs=1,
ratio=None)
舉例:
from collections import Counter
from sklearn.datasets import make_classification
from imblearn.over_sampling import ADASYN
# doctest: +NORMALIZE_WHITESPACE
X, y = make_classification(
n_classes=2,
class_sep=2,
weights=[0.1, 0.9],
n_informative=3,
n_redundant=1,
flip_y=0,
n_features=20,
n_clusters_per_class=1,
n_samples=1000,
random_state=10)
print('Original dataset shape %s'
% Counter(y))
Original dataset shape Counter
({1: 900, 0: 100})
ada = ADASYN(random_state=42)
X_res, y_res = ada.fit_resample(X, y)
print('Resampled dataset shape %s'
% Counter(y_res))
Resampled dataset shape Counter
({0: 904, 1: 900})
RandomOverSampler隨機采樣增加新樣本
例:跟之前類似,此處及后面均簡化列出。
from imblearn.over_sampling import RandomOverSampler
ros = RandomOverSampler(andom_state=0)
X_resampled, y_resampled = ros.fit_resample(X, y)
隨機對欠表達樣本進行采樣,該算法允許對heterogeneous data(異構數據)進行采樣(例如含有一些字符串)。通過對原少數樣本的重復取樣進行上采樣。
欠采樣
又稱下采樣(under-sampling)通過減少分類中多數類樣本的數量來實現樣本不均衡。
RandomUnderSampler直接隨機選取刪除法
RandomUnderSampler函數是一種快速并十分簡單的方式來平衡各個類別的數據----隨機選取數據的子集。
語法:
from imblearn.under_sampling import RandomUnderSample
model_undersample = RandomUnderSample()
x_undersample_resampled, y_undersample_resampled = model_undersample.fit_sample(X,y)
- 注意1: 當設置replacement=True時, 采用bootstrap。
- 注意2: 允許非結構化數據,例如數據中含字符串。
- 注意3: 默認參數的時候, 采用的是不重復采樣。
NearMiss 基于NN啟發式算法
NearMiss函數則添加了一些啟發式heuristic的規則來選擇樣本, 通過設定version參數來實現三種啟發式的規則。
from imblearn.under_sampling import NearMiss
nm1 = NearMiss(version=1)
X_resampled_num1, y_resampled = nm1.fit_resample(X, y)
- version=1:選取正例樣本中與N個最近鄰負樣本平均距離最小的樣本。
- version=2:選取正例樣本中與N個最遠鄰負樣本平均距離最小的樣本。
- version=3:2-steps 算法----首先對于每個負類樣本, 保留它們的M近鄰正樣本。然后那些到N個近鄰樣本平均距離最大的正樣本將被選擇。