終于把機器學習中的特征選擇搞懂了!!
特征選擇是機器學習中的一個重要過程,通過選擇與目標變量最相關的特征,剔除冗余或無關的特征,從而提高模型的性能、減少訓練時間,并降低過擬合的風險。

常見的特征選擇方法有:過濾方法、包裝方法和嵌入方法
過濾方法
過濾方法是一種基于統計特性和獨立于模型的特征選擇技術。
它通過計算特征與目標變量之間的相關性或其他統計指標來評估特征的重要性。
特點
- 獨立于模型:不依賴具體的機器學習算法。
- 計算效率高:通常基于統計指標,計算開銷較小。
常見方法
1.單變量統計方法
- 相關系數:計算特征與目標變量之間的相關性(如皮爾遜相關系數)。
- 卡方檢驗:用于分類變量和目標變量之間的獨立性檢驗。
- 方差分析(ANOVA):評估連續特征和分類目標變量之間的相關性。
2.基于評分的特征排序
- 信息增益:基于信息論,衡量特征對目標變量的信息貢獻。
- 互信息:量化兩個變量之間的統計依賴性。
- 方差閾值:通過篩選低方差特征進行降維。
3.基于統計檢驗的篩選
- t檢驗:比較兩個分布的均值,常用于分類問題。
- F檢驗:比較多個組別之間的均值差異。
優缺點
優點
- 簡單快速,適合大數據集。
- 不依賴特定的模型,通用性強。
缺點
- 忽略特征之間的交互作用。
- 可能選擇對目標變量無顯著意義的特征。
過濾方法示例
通過 SelectKBest 使用卡方檢驗來篩選特征。
import pandas as pd
from sklearn.feature_selection import VarianceThreshold, SelectKBest, chi2
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
# 加載數據
data = load_iris()
X = pd.DataFrame(data.data, columns=data.feature_names)
y = data.target
# 卡方檢驗
selector_chi2 = SelectKBest(score_func=chi2, k=2)
X_chi2_filtered = selector_chi2.fit_transform(X, y)
# 可視化特征重要性(卡方分數)
chi2_scores = selector_chi2.scores_
plt.bar(data.feature_names, chi2_scores)
plt.title("Chi-Squared Feature Importance")
plt.ylabel("Chi2 Score")
plt.show()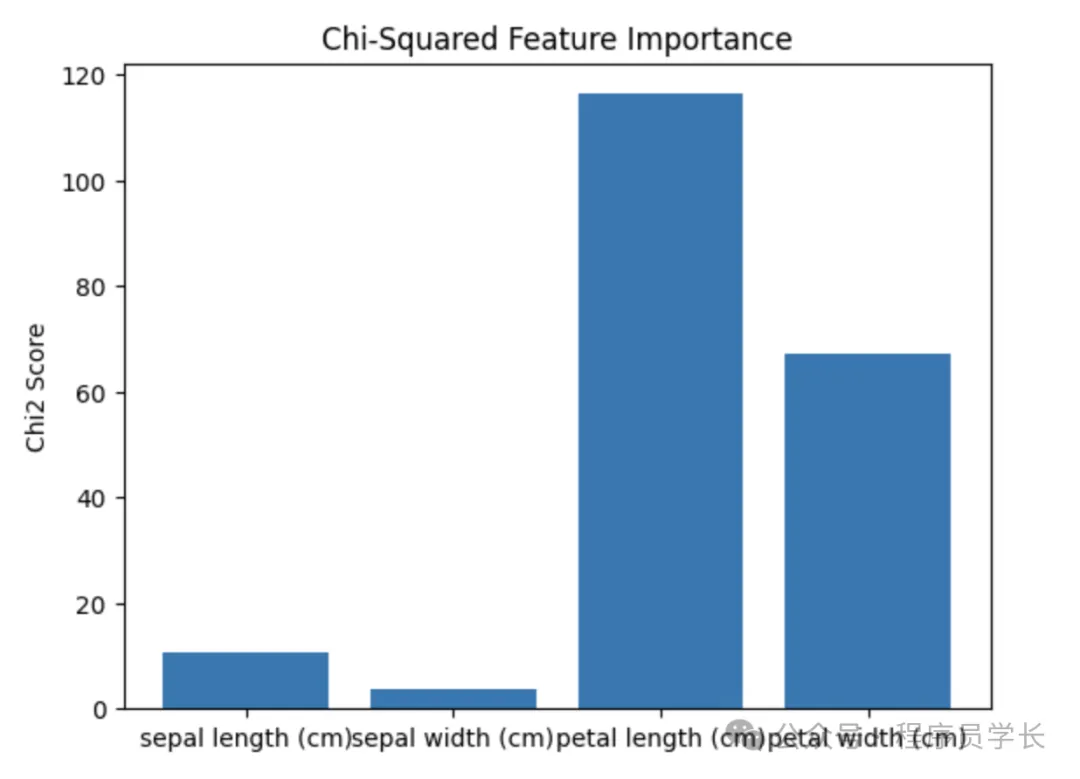
包裝方法
包裝方法將特征選擇過程嵌入模型訓練中,根據模型性能評估特征集的優劣。
它通過搜索最優特征子集來提高模型性能。
特點
- 依賴于模型:通過訓練和評估模型來選擇特征。
- 能夠捕捉特征之間的交互作用:評估子集時考慮了特征間的協同效應。
常見方法
1.遞歸特征消除(RFE)
基于模型權重遞歸地移除特征。
例如,訓練一個模型(如線性回歸或SVM),根據特征重要性刪除影響最小的特征。
2.前向選擇(Forward Selection)
從空特征集開始,逐步加入使模型性能提高最多的特征。
3.后向消除(Backward Elimination)
從全特征集開始,逐步移除對模型性能影響最小的特征。
4.嵌套交叉驗證
在特征選擇和模型評估過程中防止過擬合。
優缺點
優點
- 考慮特征之間的交互作用。
- 能找到與特定模型高度匹配的特征子集。
缺點
- 計算開銷大,尤其在大數據集上。
- 依賴于所選的學習算法,通用性差。
包裝方法示例
通過遞歸特征消除(RFE)與邏輯回歸結合篩選特征。
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.linear_model import LogisticRegression
from sklearn.feature_selection import RFE
import matplotlib.pyplot as plt
# 建立邏輯回歸模型
log_reg = LogisticRegression(max_iter=200, random_state=42)
# 使用遞歸特征消除(RFE)
rfe = RFE(estimator=log_reg, n_features_to_select=2) # 設置保留2個特征
rfe.fit(X, y)
# 輸出被選中的特征
selected_features = X.columns[rfe.support_]
print("Selected Features:", list(selected_features))
# 可視化特征排名
feature_ranking = rfe.ranking_
plt.bar(X.columns, feature_ranking)
plt.title("RFE Feature Ranking")
plt.xlabel("Features")
plt.ylabel("Ranking (Lower is Better)")
plt.xticks(rotatinotallow=45)
plt.show()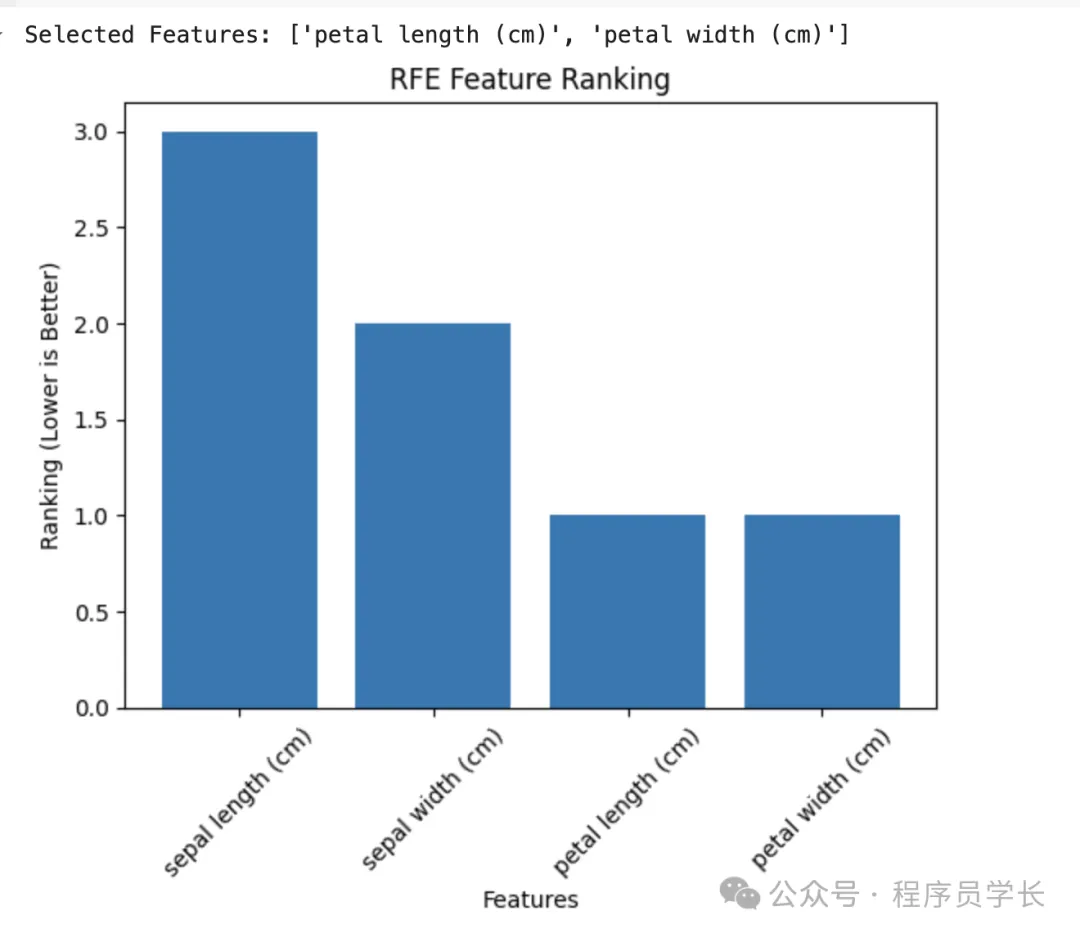
嵌入方法
嵌入方法將特征選擇與模型訓練過程結合,在模型訓練的同時完成特征選擇。
它通過內置的正則化或特征重要性指標評估特征。
特點
- 依賴于模型:模型自帶的特征權重或正則化機制決定特征選擇。
- 計算效率較高:避免了包裝方法中多次訓練模型的開銷。
常見方法
1.正則化方法
使用 L1正則化(Lasso)將部分特征的權重收縮為零,從而實現特征選擇,適用于高維稀疏數據。
2.基于樹模型的特征重要性
決策樹及其衍生算法(如隨機森林、XGBoost、LightGBM)可以計算每個特征的重要性得分。
特征重要性可以根據信息增益、基尼指數或分裂增益來衡量。
3.基于系數的重要性評估
對于線性模型,可以直接使用權重系數評估特征的重要性。
4.深度學習中的注意力機制
注意力機制可以用來動態調整特征的重要性。
優缺點
優點
- 計算效率高。
- 綜合了特征選擇與模型優化的過程。
缺點
- 依賴特定模型,缺乏靈活性。
- 不適用于所有類型的數據或任務。
嵌入方法示例
通過 Lasso 回歸篩選特征(L1 正則化)。
from sklearn.linear_model import Lasso
from sklearn.ensemble import RandomForestClassifier
# 使用 Lasso 回歸
lasso = Lasso(alpha=0.1)
lasso.fit(X, y)
lasso_coeff = lasso.coef_
# 可視化特征重要性
plt.bar(data.feature_names, abs(lasso_coeff))
plt.title("Lasso Coefficients")
plt.ylabel("Coefficient Value")
plt.show()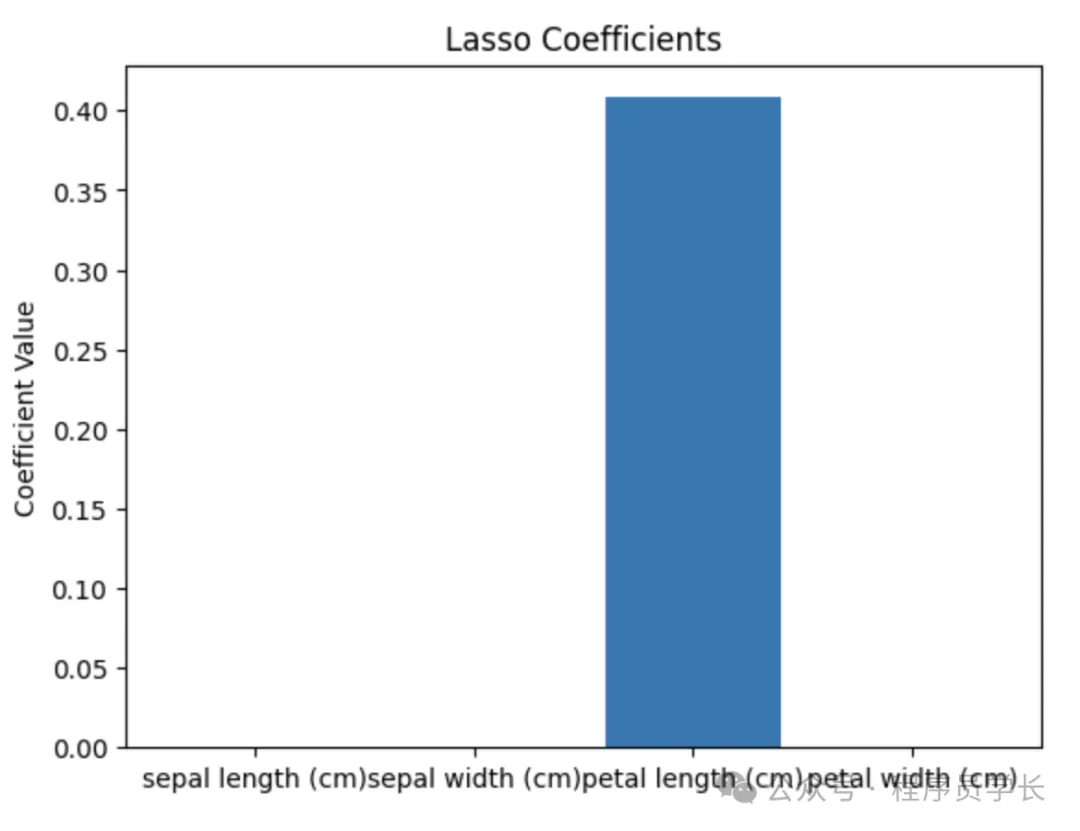
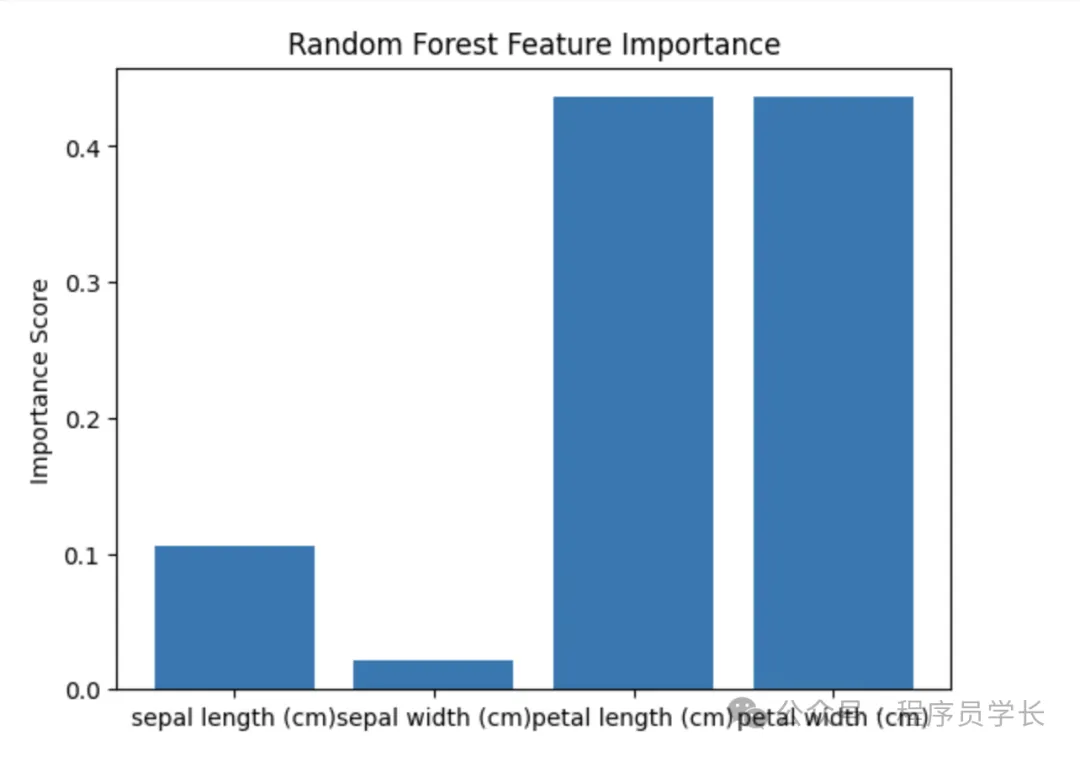
通過隨機森林評估特征重要性。
# 使用隨機森林
rf = RandomForestClassifier(random_state=42)
rf.fit(X, y)
rf_importance = rf.feature_importances_
plt.bar(data.feature_names, rf_importance)
plt.title("Random Forest Feature Importance")
plt.ylabel("Importance Score")
plt.show()