超越ImageNet預訓練,Meta AI提SplitMask,小數據集自監督預訓練

目前,計算機視覺神經網絡被大量參數化:它們通常有數千萬或數億個參數,這是它們成功利用大型圖像集合 (如 ImageNet) 的關鍵。然而,這些高容量模型往往會在小型(包含數十萬張圖像)甚至中型數據集上過度擬合。因此,有研究者指出在 2014 年:學習 CNN 的過程相當于估計模型數百萬個參數,這需要大量的帶標注的數據。
當今應對數據匱乏問題的主流學習范式是,即先在大型數據集(如 Imagenet )上對模型進行預訓練,之后基于特定的任務以較少的數據集微調模型。這一訓練過程通常優于從頭開始訓練(例如,從頭隨機初始化參數)。
這種學習范式在許多任務中取得了 SOTA 性能,例如檢測、分割、動作識別等。盡管這種方法取得了成功,但我們很難將這種大規模標簽數據集提供的好處與預訓練范式的局限性區分開來。除此以外,在一個數據集上預訓練模型并在另一個數據集上對其進行微調會引入差異。
來自 Meta AI 等機構的研究者,考慮了一個僅利用目標任務數據的自監督預訓練場景。所用數據集包括如 Stanford Cars、Sketch 或 COCO,它們的數量級小于 Imagenet。
該研究表明,本文介紹的去噪自編碼器(如 BEiT 或其變體),對預訓練數據的類型和大小更具有魯棒性。與來自 ImageNet 預訓練相比,該研究獲得了具有競爭力的性能。在 COCO 上,當僅使用 COCO 圖像進行預訓練時,在檢測和實例分割任務上,性能超過了監督 ImageNet 預訓練。

論文地址:https://arxiv.org/pdf/2112.10740.pdf
論文介紹
本文研究了圖像的數量及其性質如何影響自監督模型的質量。在這個初步分析中,該研究將 BEiT 和 SplitMask(在第 4 節中的變體)分別作為去噪自編碼器和聯合嵌入方法 DINO(Facebook 發布的非監督學習) 的代表。
SplitMask 是一種基于視覺 transformer 的去噪自動編碼器變體,方法概述如圖 4 所示:
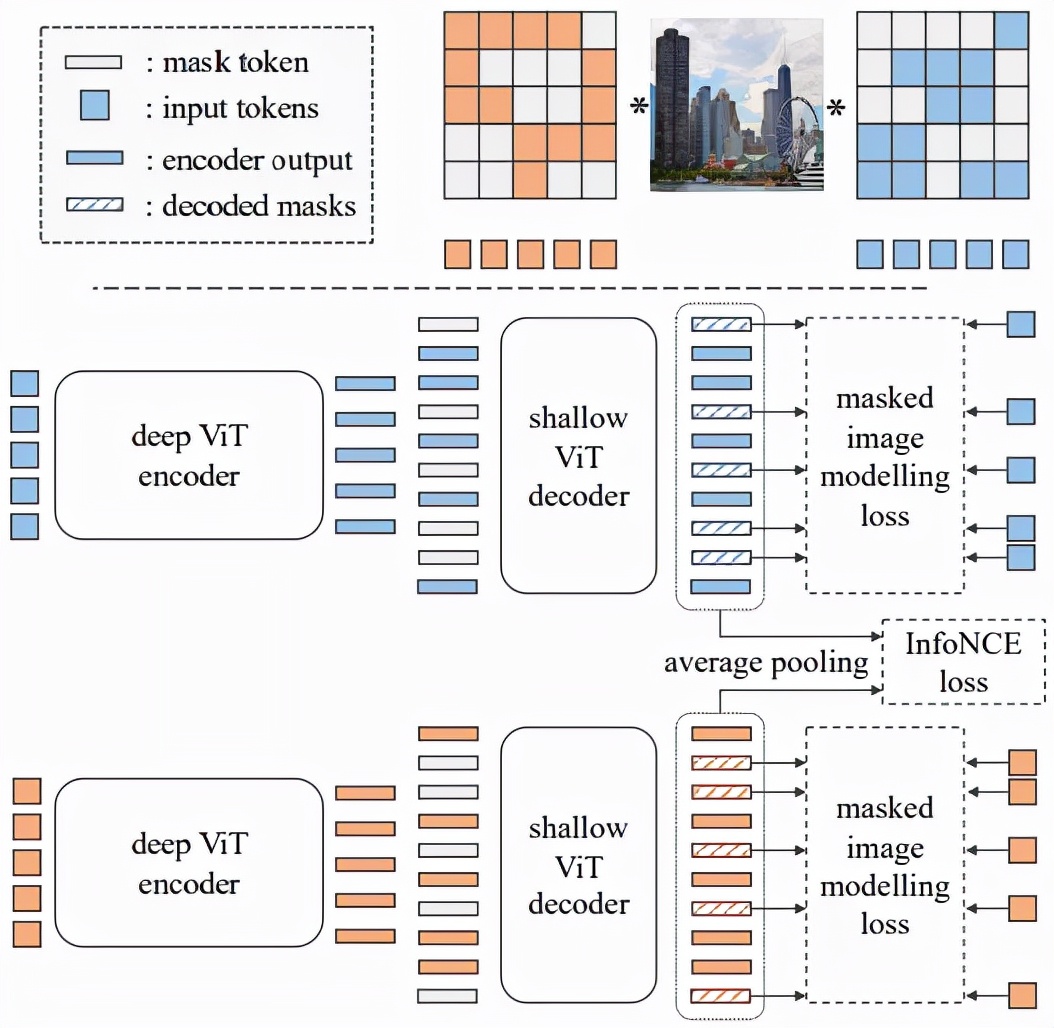
SplitMask 架構
SplitMask
SplitMask 基于三個步驟完成:分解(split)、修復(inpaint)和匹配。與標準視覺 transformer 一樣,圖像首先被分解為 16×16 的 patch,之后 patch 又被分成兩個不相交的子集 A 和 B。接下來,研究者使用子集 A 的 patch 表示和淺層解碼器,來修復子集 B 的 patch,反之亦然。最后,通過對每個分支對應的解碼器輸出的 patch 表示進行平均池化,得到全局圖像描述符。之后研究者嘗試將從子集 A 獲得的圖像全局描述符與從子集 B 獲得的圖像全局描述符相匹配。
編碼器 - 解碼器架構
SplitMask 實現 pipeline 依賴于編碼器 - 解碼器架構。模型的編碼器是一個標準的視覺 transformer,具有絕對位置嵌入。與 BEiT 方法相反,該編碼器不處理掩碼 token(masked tokens)表示,而只處理觀察到的 token 。因此,圖像被劃分為線性嵌入 patch,并將位置嵌入添加到這些表示中。這些表示分為兩個子集 A 和 B,由標準 transformer 層獨立處理。
全局對比損失
除了在 patch 級別計算 MIM 損失之外,該研究還在圖像級別使用對比損失。為此,該研究對解碼器的所有輸出表示應用平均池化操作。每個圖像獲得兩個表示 x_a 和 x_b,對應于觀察到的 patch 子集 A 和 B。InfoNCE 損失 [59] 應用于這些表示:
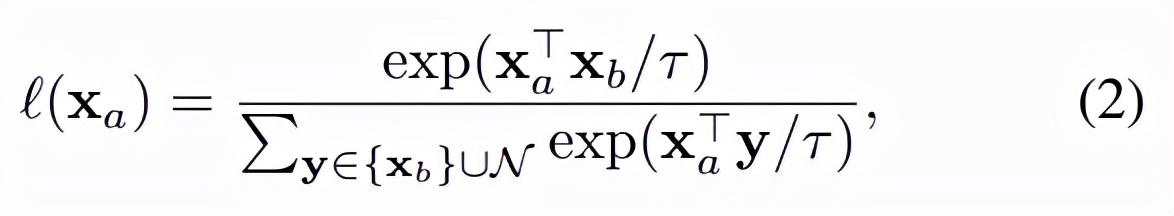
實驗
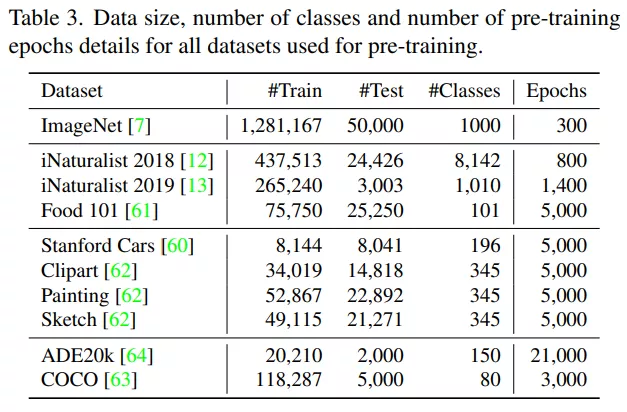
首先,實驗研究了計算機視覺模型在各種數據集上的預訓練和微調,詳見表 3,表中列出了數據集名稱、訓練和測試數據分布等信息。
預測任務
首先,該研究使用 Mask R-CNN pipeline [8] 在 COCO 目標檢測和實例分割數據集上對 SplitMask 進行評估,表 4 為評估結果。
由結果可得,在相同的 BEiT 模型上,單獨在 COCO 數據集上預訓練的模型與在 ImageNet 上預訓練模型相比,前者下游任務性能更好。例如,當使用基于 ViT 的主干時,在 COCO 上而不是 ImageNet 上進行預訓練會可使 box AP 提升 +0.4。
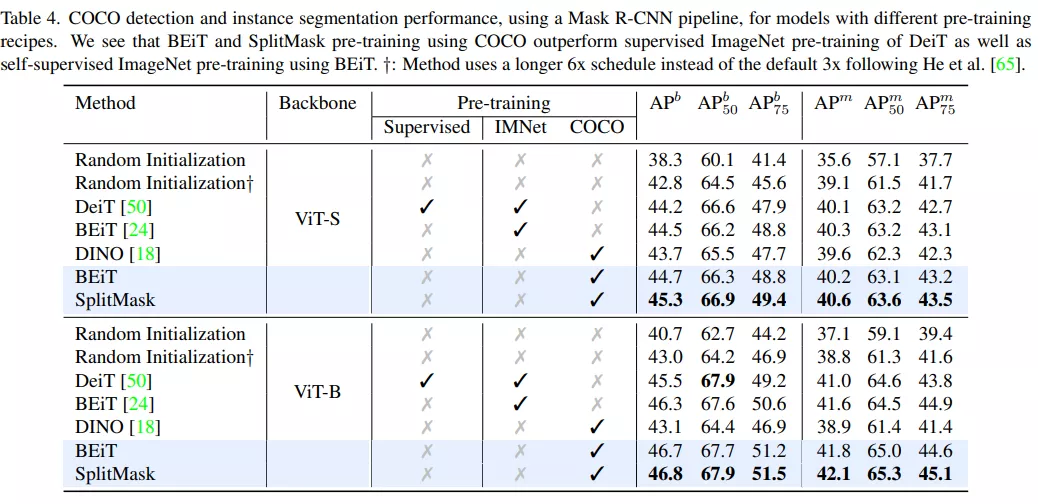
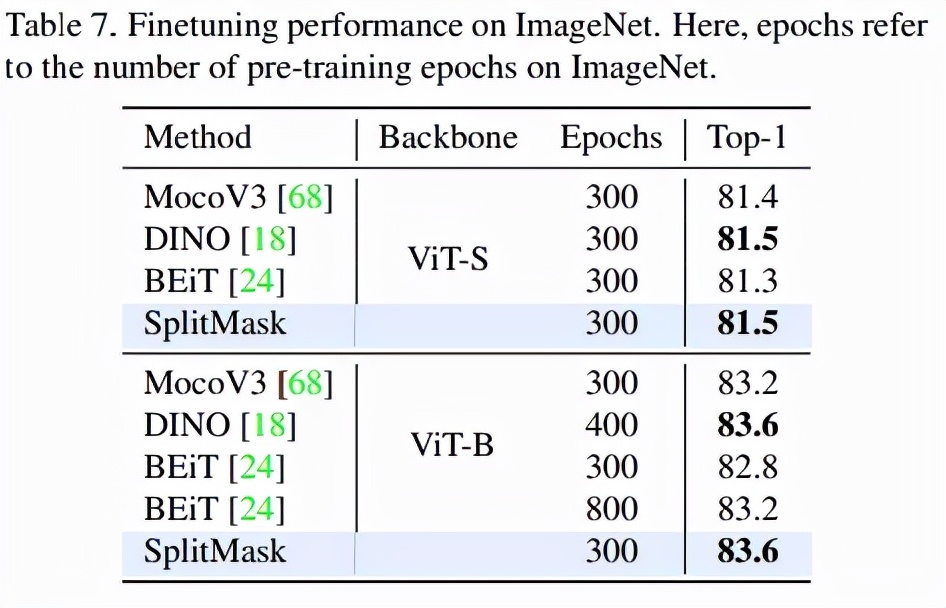
表 6 為數字分類數據集實證評估結果:
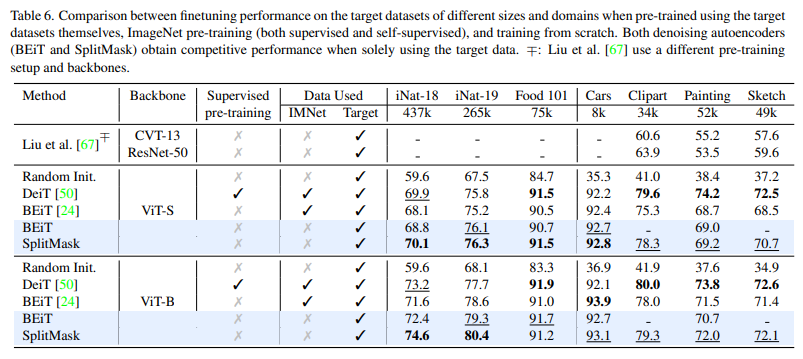
表 7 展示了 SplitMask 方法使用 ViT-S 和 ViT-B 主干以及 300 個 epoch 的預訓練與其他最近的基于 Transformer 的自監督學習方法相比的性能: