UniPAD:自動駕駛通用預訓練范式來了!
本文經自動駕駛之心公眾號授權轉載,轉載請聯系出處。
UNIPAD:自動駕駛通用預訓練范式
原標題:UNIPAD: A UNIVERSAL PRE-TRAINING PARADIGM FOR AUTONOMOUS DRIVING
論文鏈接:https://arxiv.org/pdf/2310.08370.pdf
代碼鏈接:https://github.com/Nightmare-n/UniPAD
作者單位:上海人工智能實驗室 浙江大學 香港大學 中國科學技術大學 悉尼大學 Zhejiang Lab

論文思路:
在自動駕駛的背景下,有效特征學習的重要性得到了廣泛認可。雖然傳統的 3D 自監督預訓練方法已經取得了廣泛的成功,但大多數方法都遵循最初為 2D 圖像設計的想法。本文提出了 UniPAD,一種應用 3D 體積可微渲染(3D volumetric differentiable rendering)的新型自監督學習范式。UniPAD 隱式編碼 3D 空間,有助于重建連續的 3D 形狀結構及其 2D 投影的復雜外觀特征。本文方法的靈活性使得能夠無縫集成到 2D 和 3D 框架中,從而能夠更全面地理解場景。本文通過對各種下游 3D 任務進行廣泛的實驗來證明 UniPAD 的可行性和有效性。本文的方法將基于激光雷達、攝像機和激光雷達-攝像機的基線分別顯著提高了 9.1、7.7 和 6.9 NDS。值得注意的是,本文的預訓練 pipeline 在 nuScenes 驗證集上實現了 3D 目標檢測的 73.2 NDS 和 3D 語義分割的 79.4 mIoU,與之前的方法相比,實現了最先進的結果。
主要貢獻:
據本文所知,本文是第一個探索一種新穎的 3D 可微渲染(3D differentiable rendering)方法,用于自動駕駛背景下的自監督學習。
該方法的靈活性使其易于擴展到2D backbone的預訓練。通過新穎的采樣策略,本文的方法在有效性和效率上都表現出了優越性。
本文在 nuScenes 數據集上進行了全面的實驗,其中本文的方法超越了六種預訓練策略的性能。包含七個 backbones 和兩個感知任務的實驗為本文方法的有效性提供了令人信服的證據。
網絡設計:
本文提出了一種專為有效 3D 表示學習而定制的新穎的預訓練范式,它不僅避免了復雜的正/負樣本分配,而且還隱式提供了連續的監督信號來學習 3D 形狀結構。如圖 2 所示,整個框架將 masked點云作為輸入,旨在通過 3D 可微神經渲染在投影的 2D 深度圖像上重建缺失的幾何形狀。具體來說,當提供masked LiDAR 點云時,本文的方法采用 3D 編碼器來提取分層特征。然后,通過體素化將 3D 特征轉換到體素空間。本文進一步應用可微分體積渲染方法來重建完整的幾何表示。本文方法的靈活性有助于其與預訓練 2D backbone的無縫集成。多視圖圖像特征通過 lift-split-shoot (LSS) 構建 3D volume(Philion & Fidler,2020)。為了保持訓練階段的效率,本文提出了一種專為自動駕駛應用設計的節省內存的光線采樣(ray sampling)策略,其可以大大降低訓練成本和內存消耗。與傳統方法相比,新穎的采樣策略顯著提高了準確性。
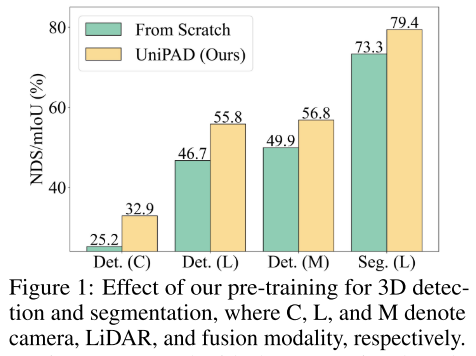
圖 1:本文對 3D 檢測和分割進行預訓練的效果,其中 C、L 和 M 分別表示攝像機、LiDAR 和融合模態。
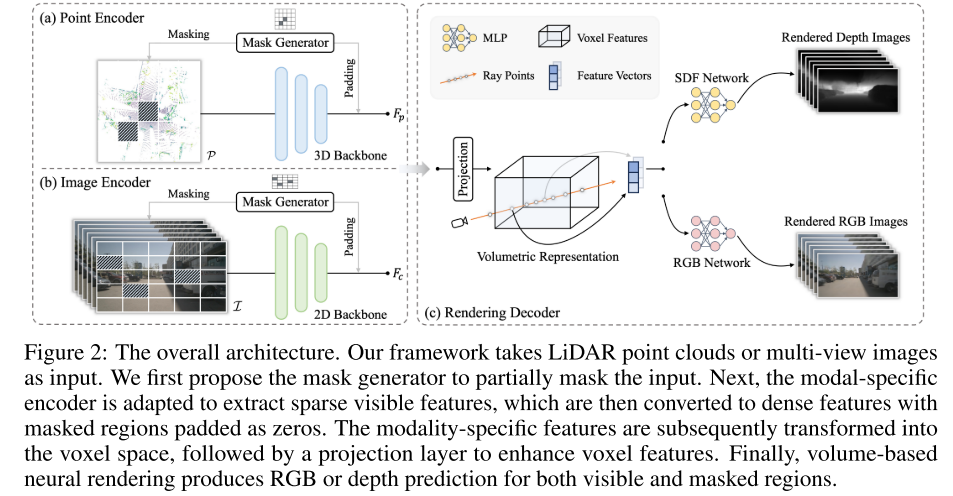
圖 2:整體架構。
本文的框架采用 LiDAR 點云或多視圖圖像作為輸入。本文首先提出 mask 生成器來部分 mask 輸入。接下來,特定于模態的編碼器適用于提取稀疏可見特征,然后將其轉換為密集特征,其中 mask 區域填充為零。隨后將特定于模態的特征轉換到體素空間,然后是投影層以增強體素特征。最后,基于體積的神經渲染為可見區域和 mask 區域生成 RGB 或深度預測。
實驗結果:


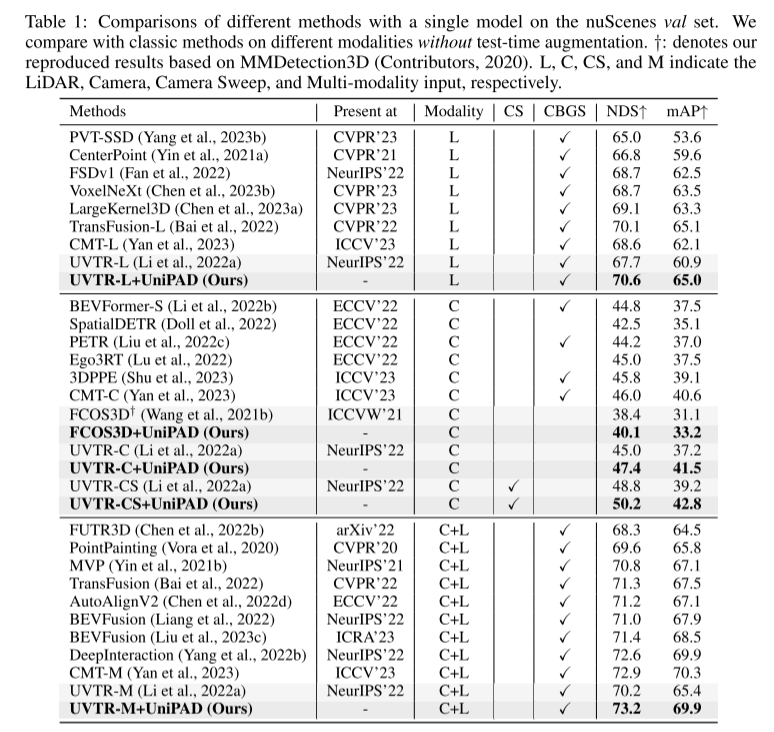

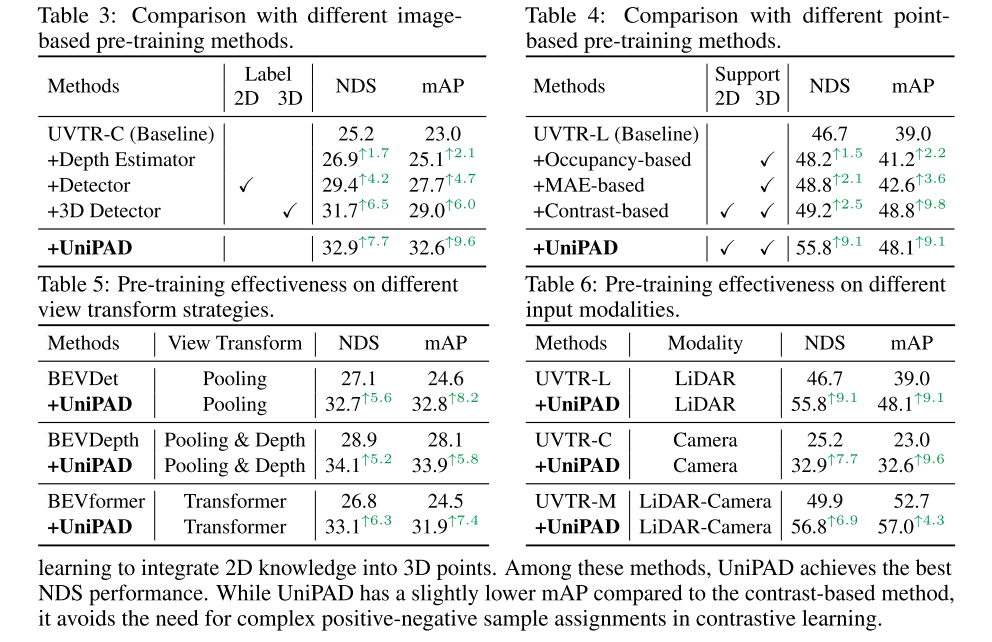
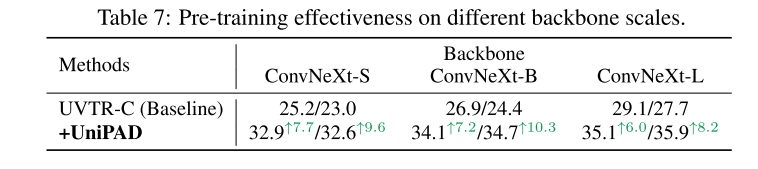
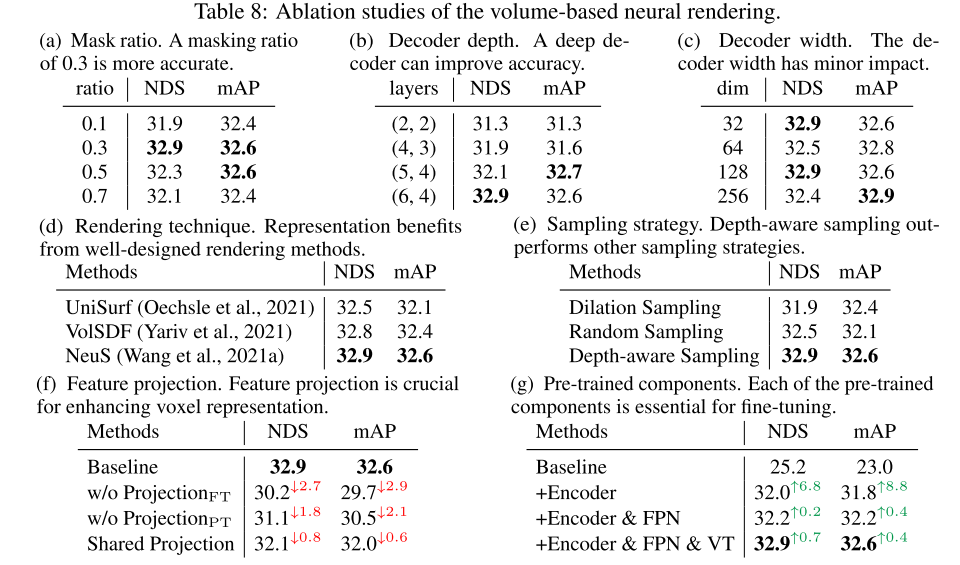
引用:
Yang, H., Zhang, S., Huang, D., Wu, X., Zhu, H., He, T., Tang, S., Zhao, H., Qiu, Q., Lin, B., He, X., & Ouyang, W. (2023). UniPAD: A Universal Pre-training Paradigm for Autonomous Driving. ArXiv. /abs/2310.08370

原文鏈接:https://mp.weixin.qq.com/s/ep_al_G-ejQycgG4Jq0nTQ