AI看圖說話首超人類!微軟認(rèn)知AI團(tuán)隊(duì)提出視覺詞表預(yù)訓(xùn)練超越Transformer
能看圖會(huì)說話的AI,表現(xiàn)還超過了人類?最近,Azure悄然上線了一個(gè)新的人工智能服務(wù),能精準(zhǔn)的說出圖片中的內(nèi)容。而背后的視覺詞表技術(shù),更是超越了基于Transformer的前輩們,拿到nocaps挑戰(zhàn)賽冠軍。
有沒有發(fā)現(xiàn),搜索出來的圖片有時(shí)相關(guān)性很差?
現(xiàn)在很多搜索引擎都是基于圖片的文本標(biāo)簽,但是我們的世界每天產(chǎn)生不計(jì)其數(shù)的照片,很多都沒有標(biāo)記直接傳到了網(wǎng)上,給圖片搜索帶來了很多混亂。
如果系統(tǒng)能自動(dòng)給圖片加上精準(zhǔn)的描述,圖像搜索的效率將大為提高。
看圖說話的AI:基于模板和Transformer都不盡如人意
看圖說話(或者叫圖像描述),近年來受到了很多關(guān)注,它可以自動(dòng)生成圖片描述。但是目前無論是學(xué)術(shù)界還是工業(yè)界,做的效果都差強(qiáng)人意。
看圖說話系統(tǒng)一方面需要計(jì)算機(jī)視覺進(jìn)行圖像的識(shí)別,另一方面需要自然語言來描述識(shí)別到的物體。帶標(biāo)簽的圖片可以針對(duì)性訓(xùn)練,那如果出現(xiàn)了從未標(biāo)注的新物體,系統(tǒng)是不是就失效了?
這個(gè)問題困擾了人們很久,即描述清楚一個(gè)新出現(xiàn)的東西。
人工智能領(lǐng)域驗(yàn)證一個(gè)模型的好壞,通常會(huì)用一個(gè)基準(zhǔn)測試。比如NLP方向會(huì)用GLUE、SuperGLUE等,圖像識(shí)別會(huì)用ImageNet等。
為了測試模型能否在沒有訓(xùn)練數(shù)據(jù)的情況下完成看圖說話,nocaps應(yīng)運(yùn)而生。nocaps可以衡量模型能否準(zhǔn)確描述未出現(xiàn)過的物體。
傳統(tǒng)的看圖說話方法主要有兩種:一種是模板生成,一種是基于 Transformer 的圖像文本交互預(yù)訓(xùn)練。

模板生成方法,在簡單場景下可以使用,但無法捕捉深層次的圖像文本關(guān)系,而基于Transformer的模型又需要海量的標(biāo)注數(shù)據(jù),所以不適合nocaps。
為解決這些問題,微軟認(rèn)知服務(wù)團(tuán)隊(duì)的研究人員提出了一種名為視覺詞表預(yù)訓(xùn)練(Visual Vocabulary Pre-training,簡稱VIVO)的解決方案。
無需配對(duì)圖文數(shù)據(jù),VIVO看圖說話奪冠nocaps首次超越人類
VIVO可以在沒有文本標(biāo)簽的數(shù)據(jù)上進(jìn)行文本和圖像的多模態(tài)預(yù)訓(xùn)練,擺脫了對(duì)配對(duì)圖文數(shù)據(jù)的依賴,可以直接利用ImageNet等數(shù)據(jù)集的類別標(biāo)簽。借助VIVO,模型可以學(xué)習(xí)到物體的視覺外表和語義之間的關(guān)系,建立視覺詞表。
這個(gè)視覺詞表是啥呢?其實(shí)就是一個(gè)圖像和文本的聯(lián)合特征空間,在這個(gè)特征空間中,語義相近的詞會(huì)聚類到一起,如金毛和牧羊犬,手風(fēng)琴和樂器等。
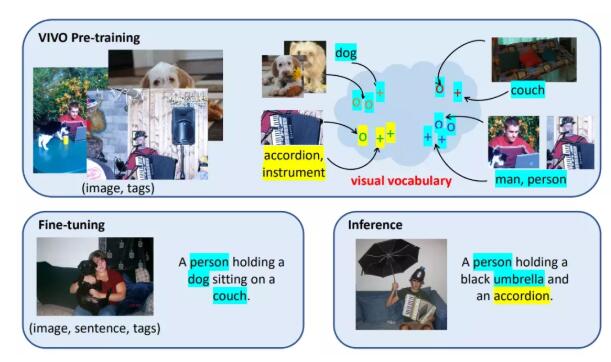
預(yù)訓(xùn)練建好詞表后,模型只需在有少量共同物體的配對(duì)圖文的數(shù)據(jù)上進(jìn)行微調(diào),模型就能自動(dòng)生成通用的模板語句,使用時(shí),即使出現(xiàn)沒見過的詞,也能從容應(yīng)對(duì),相當(dāng)于把圖片和描述的各部分解耦了。
所以VIVO既能利用預(yù)訓(xùn)練強(qiáng)大的物體識(shí)別能力,也能夠利用模板的通用性,從而應(yīng)對(duì)新出現(xiàn)的物體。
Azure AI 認(rèn)知服務(wù)首席技術(shù)官黃學(xué)東解釋說,視覺詞表的預(yù)訓(xùn)練類似于讓孩子們先用一本圖畫書來閱讀,這本圖畫書將單個(gè)單詞與圖像聯(lián)系起來,比如一個(gè)蘋果的圖片下面有個(gè)單詞apple,一只貓的圖片下面有個(gè)單詞cat。
視覺詞表的預(yù)訓(xùn)練本質(zhì)上就是訓(xùn)練系統(tǒng)完成這種動(dòng)作記憶。
目前,VIVO 在 nocaps 挑戰(zhàn)中取得了 SOTA效果,并首次超越人類表現(xiàn)。
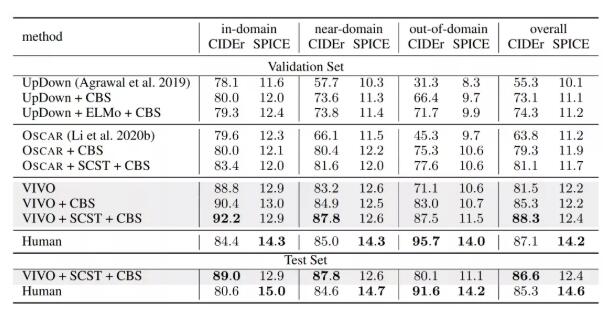
VIVO取得成功可不僅僅是挑戰(zhàn)賽的SOTA,目前已經(jīng)有了實(shí)際應(yīng)用。
看圖說話SOTA已上線,AI不能一直處于灰色的迭代
據(jù)世界衛(wèi)生組織統(tǒng)計(jì),各年齡段視力受損的人數(shù)估計(jì)有2.85億人,其中3900萬人是盲人。
實(shí)力受損的用戶想要獲取圖片和視頻中的信息,就要依靠自動(dòng)生成的圖片描述或字幕(或者進(jìn)一步轉(zhuǎn)化為語音),他們非常相信這些自動(dòng)生成的描述,不管字幕是否有意義。
「理想情況下,每個(gè)人都應(yīng)該在文檔、網(wǎng)絡(luò)、社交媒體中給圖片添加描述,因?yàn)檫@樣可以讓盲人訪問內(nèi)容并參與對(duì)話。」但是,這很不現(xiàn)實(shí),很多圖片都沒有對(duì)應(yīng)的文本。
Azure AI 認(rèn)知服務(wù)公司首席技術(shù)官黃學(xué)東說: 「看圖說話是計(jì)算機(jī)視覺的核心能力之一,可以提供廣泛的服務(wù)」。
現(xiàn)在VIVO看圖說話的能力已經(jīng)集成到了Azure AI中,任何人都可以將它集成到自己的視覺AI應(yīng)用中。
黃學(xué)東認(rèn)為, 把VIVO的突破帶到 Azure 上,為更廣泛的客戶群服務(wù),不僅是研究上的突破,更重要的是將這一突破轉(zhuǎn)化為 Azure 上的產(chǎn)品所花費(fèi)的時(shí)間。
基于VIVO的小程序Seeing AI在蘋果應(yīng)用商店已經(jīng)可以使用了,Azure也已經(jīng)上線了免費(fèi)API,供盲人或者視障人士免費(fèi)使用。如果再加上Azure的翻譯服務(wù),看圖說話可以支持80多種語言。
的確,有太多的實(shí)驗(yàn)室SOTA技術(shù)倒在了灰色的不斷迭代中,沒能完成它最初的使命。
看圖說話只是認(rèn)知智能的一小步,受古登堡印刷機(jī)啟發(fā)開創(chuàng)新魔法
近年來,微軟一直在尋求超越現(xiàn)有技術(shù)的人工智能。
作為 Azure 認(rèn)知服務(wù)的首席技術(shù)官,黃學(xué)東所在的團(tuán)隊(duì)一直在探索,如何更全面、更人性化地來學(xué)習(xí)和理解這個(gè)世界。
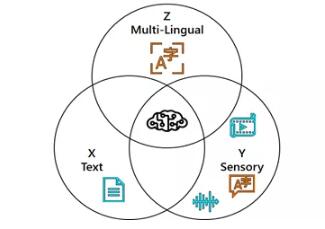
他認(rèn)為要想獲得更好的認(rèn)知能力,三個(gè)要素至關(guān)重要,單語言文本(X)、音頻或視覺等感覺信號(hào)(Y)和多語言(Z)。
在這三者的交匯處,有一種新魔法ーー XYZ-Code,可以創(chuàng)造出更強(qiáng)大的人工智能,能夠更好地聽、說、看和理解人類。
「我們相信 XYZ-Code正在實(shí)現(xiàn)我們的長期愿景: 跨領(lǐng)域、跨模式和跨語言學(xué)習(xí)。我們的目標(biāo)是建立預(yù)先訓(xùn)練好的模型,這些模型可以學(xué)習(xí)大范圍的下游人工智能任務(wù)的表示,就像今天人類所做的那樣。」
黃學(xué)東團(tuán)隊(duì)從德國發(fā)明家約翰內(nèi)斯·古登堡那里獲得靈感,他在1440年發(fā)明了印刷機(jī),使人類能夠快速、大量地分享知識(shí)。作為歷史上最重要的發(fā)明之一,古登堡的印刷機(jī)徹底改變了社會(huì)進(jìn)化的方式。

古登堡和他發(fā)明的印刷機(jī)
在今天的數(shù)字時(shí)代,認(rèn)知智能的愿景也是開發(fā)一種能夠像人一樣學(xué)習(xí)和推理的技術(shù),對(duì)各種情況和意圖做出精準(zhǔn)推斷,進(jìn)而做出合理的決策。
在過去的五年里,我們已經(jīng)在人工智能的很多領(lǐng)域?qū)崿F(xiàn)了人類的平等地位,包括語音識(shí)別對(duì)話、機(jī)器翻譯、問答對(duì)話、機(jī)器閱讀理解和看圖說話。
這五個(gè)突破讓我們更有信心實(shí)現(xiàn)人工智能的飛躍,XYZ-Code將成為多感官和多語言學(xué)習(xí)的重要組成部分,最終讓人工智能更像人類。
正如古登堡的印刷機(jī)革命性地改變了通信的過程,認(rèn)知智能將幫助我們實(shí)現(xiàn)人工智能的偉大復(fù)興。
看圖說話體驗(yàn)鏈接:
https://apps.apple.com/us/app/seeing-ai/id999062298