













用于激光雷達點云自監(jiān)督預訓練SOTA!
本文經(jīng)自動駕駛之心公眾號授權(quán)轉(zhuǎn)載,轉(zhuǎn)載請聯(lián)系出處。

論文思路:
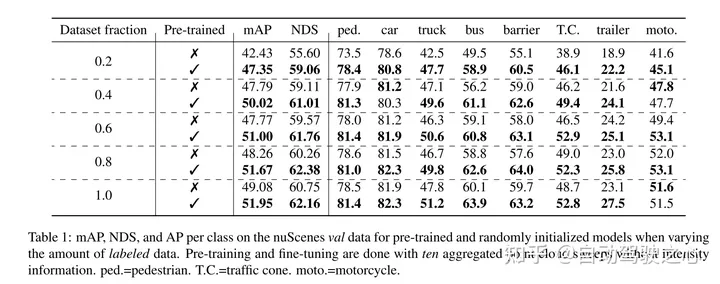
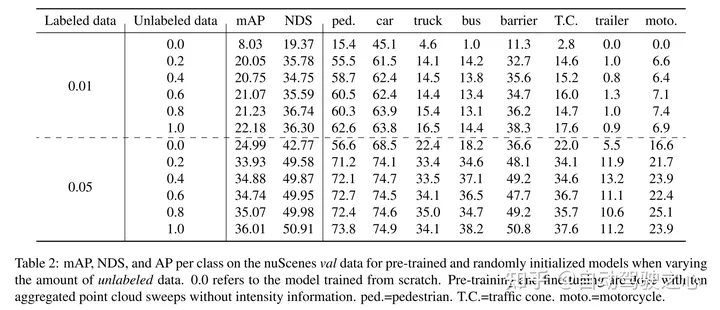
masked autoencoding已經(jīng)成為文本、圖像和最近的點云的Transformer模型的一個成功的預訓練范例。原始的汽車數(shù)據(jù)集適合進行自監(jiān)督的預訓練,因為與3D目標檢測(OD)等任務的標注相比,它們的收集成本通常較低。然而,針對點云的masked autoencoders的開發(fā)僅僅集中在合成和室內(nèi)數(shù)據(jù)上。因此,現(xiàn)有的方法已經(jīng)將它們的表示和模型定制為小而稠密的點云,具有均勻的點密度。在這項工作中,本文研究了在汽車設置中對點云進行的masked autoencoding,這些點云是稀疏的,并且在同一場景中,點云的密度在不同的物體之間可以有很大的變化。為此,本文提出了Voxel-MAE,這是一種為體素表示而設計的簡單的masked autoencoding預訓練方案。本文對基于Transformer三維目標檢測器的主干進行了預訓練,以重建masked體素并區(qū)分空體素和非空體素。本文的方法提高了具有挑戰(zhàn)性的nuScenes數(shù)據(jù)集上1.75 mAP和1.05 NDS的3D OD性能。此外,本文表明,通過使用Voxel-MAE進行預訓練,本文只需要40%的帶注釋數(shù)據(jù)就可以超過隨機初始化的等效數(shù)據(jù)。
主要貢獻:
本文提出了Voxel-MAE(一種在體素化的點云上部署MAE-style的自監(jiān)督預訓練的方法),并在大型汽車點云數(shù)據(jù)集nuScenes上對其進行了評估。本文的方法是第一個使用汽車點云Transformer主干的自監(jiān)督預訓練方案。
本文針對體素表示定制本文的方法,并使用一組獨特的重建任務來捕捉體素化點云的特征。
本文證明了本文的方法數(shù)據(jù)高效,并且減少了對帶注釋數(shù)據(jù)的需求。通過預訓練,當只使用40%的帶注釋的數(shù)據(jù)時,本文的性能優(yōu)于全監(jiān)督的數(shù)據(jù)。
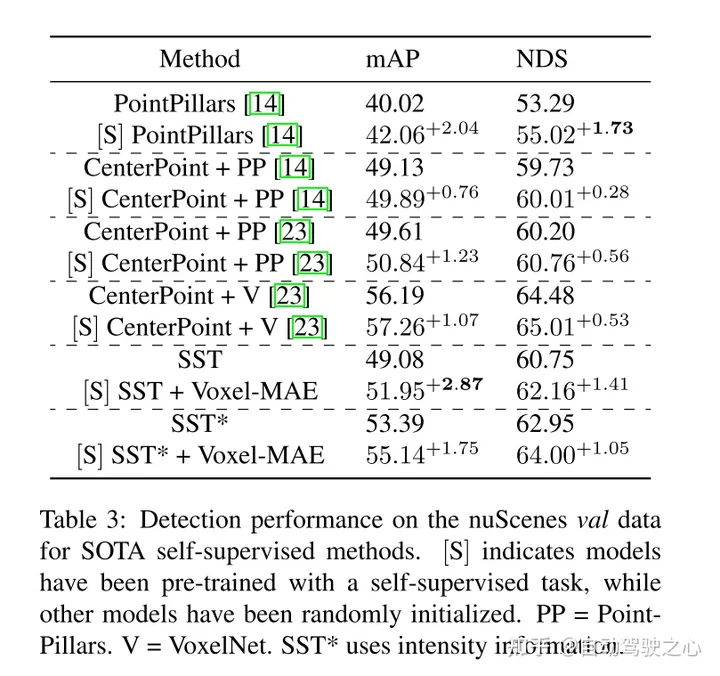
此外,本文發(fā)現(xiàn)Voxel-MAE在mAP中將基于Transformer檢測器的性能提高了1.75個百分點,在NDS中將其性能提高了1.05個百分點,與現(xiàn)有的自監(jiān)督方法相比,其性能提高了2倍。
網(wǎng)絡設計:
這項工作的目的是將MAE-style的預訓練擴展到體素化的點云。核心思想仍然是使用編碼器從對輸入的部分觀察中創(chuàng)建豐富的潛在表示,然后使用解碼器重構(gòu)原始輸入,如圖2所示。經(jīng)過預訓練后,編碼器被用作3D目標檢測器的主干。但是,由于圖像和點云之間的基本差異,需要對Voxel-MAE的有效訓練進行一些修改。
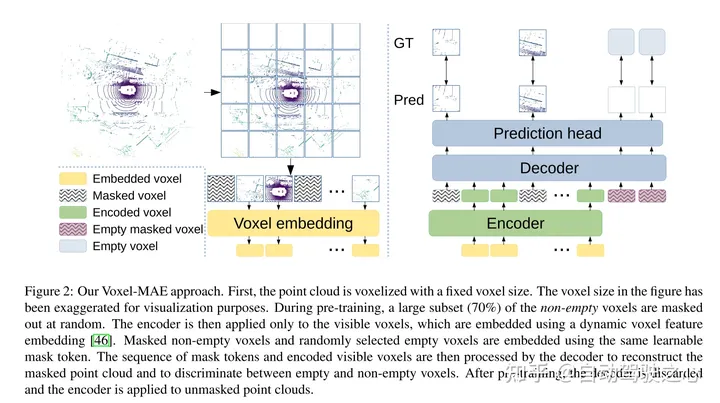
圖2:本文的Voxel-MAE方法。首先,用固定的體素大小對點云進行體素化。圖中的體素大小已被夸大,以實現(xiàn)可視化的目的。在訓練前,很大一部分(70%)的非空體素被隨機mask掉了。然后,編碼器只應用于可見體素,使用嵌入[46]的動態(tài)體素特征嵌入這些體素。masked非空體素和隨機選擇的空體素使用相同的可學習mask tokens嵌入。然后,解碼器對mask tokens序列和編碼的可見體素序列進行處理,以重構(gòu)masked點云并區(qū)分空體素和非空體素。在預訓練之后,丟棄解碼器,并將編碼器應用于unmasked點云。

圖1:MAE(左)將圖像劃分為固定大小的不重疊的patches。現(xiàn)有的masked點建模方法(中)通過使用最遠點采樣和k近鄰創(chuàng)建固定數(shù)量的點云patches。本文的方法(右)使用非重疊體素和動態(tài)數(shù)量的點。
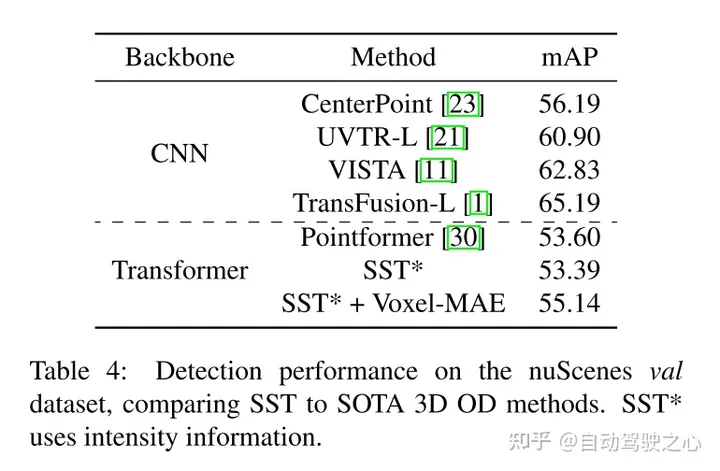
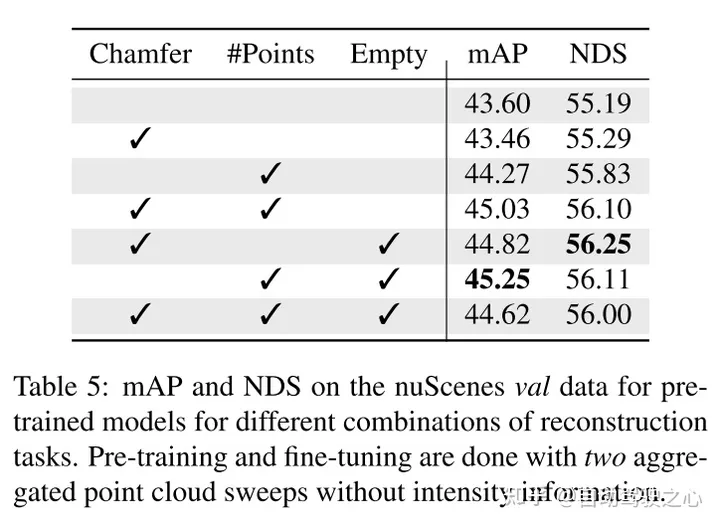
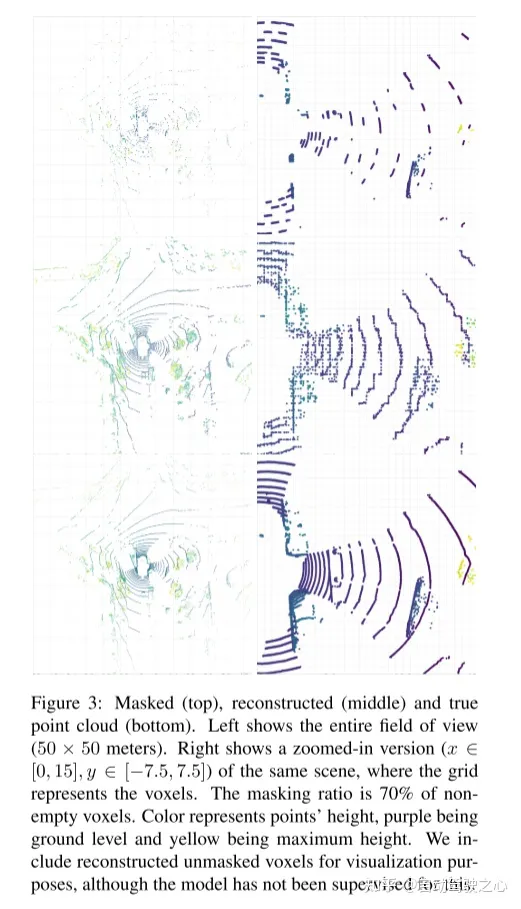
實驗結(jié)果:
引用:
Hess G, Jaxing J, Svensson E, et al. Masked autoencoder for self-supervised pre-training on lidar point clouds[C]//Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 2023: 350-359.


























