高真實(shí)感、全局一致、外觀精細(xì),面向模糊目標(biāo)的NeRF方案出爐
模糊復(fù)雜目標(biāo)的高真實(shí)感建模和渲染對于許多沉浸式 VR/AR 應(yīng)用至關(guān)重要,其中物體的亮度與顏色和視圖強(qiáng)相關(guān)。在本文中,來自上海科技大學(xué)的研究者提出了一種使用卷積神經(jīng)渲染器為模糊目標(biāo)生成不透明輻射場的新方案,這是首個將顯式不透明監(jiān)督和卷積機(jī)制結(jié)合到神經(jīng)輻射場框架中以實(shí)現(xiàn)高質(zhì)量外觀的方案,并以任意新視角生成全局一致的 alpha 蒙版。
具體而言,該研究提出了一種有效的采樣策略以及攝像機(jī)光線和圖像平面,從而能夠進(jìn)行有效的輻射場采樣,并以 patch-wise 的方式學(xué)習(xí)。同時,該研究還提出了一種新型的體積特征集成方案,該方案會生成 per-patch 混合特征嵌入,以重建視圖一致的精細(xì)外觀和不透明輸出。
此外,該研究進(jìn)一步采用 patch-wise 對抗訓(xùn)練方案,以在自監(jiān)督框架中同時保留高頻外觀和不透明細(xì)節(jié)。該研究還提出了一種高效的多視圖圖像捕獲系統(tǒng),以捕獲挑戰(zhàn)性模糊目標(biāo)的高質(zhì)量色彩和 alpha 圖。在現(xiàn)有數(shù)據(jù)集和新的含有挑戰(zhàn)性模糊目標(biāo)的數(shù)據(jù)集上進(jìn)行的大量實(shí)驗(yàn)表明,該研究提出的新方法可以對多種模糊目標(biāo)實(shí)現(xiàn)高真實(shí)感、全局一致、外觀精細(xì)的不透明自由視角渲染。

論文地址:https://arxiv.org/abs/2104.01772
該研究的主要貢獻(xiàn)包括:
- 提出了一種新型卷積神經(jīng)輻射場生成方案,用于重建高頻和新視圖中模糊目標(biāo)的全局一致的外觀和不透明度,并顯著超越了此前的 SOTA 性能;
- 為了啟用卷積機(jī)制,該研究提出了高效的采樣策略,混合特征融合以及用于 patch-wise 輻射場學(xué)習(xí)的自監(jiān)督對抗訓(xùn)練方案;
- 提出了一種高效的多視圖系統(tǒng),以捕獲顏色和 alpha 圖,以應(yīng)對具有挑戰(zhàn)性的模糊目標(biāo),該研究的捕獲數(shù)據(jù)集可用于激發(fā)進(jìn)一步的研究。
方法框架
研究者在論文中詳細(xì)介紹了新提出的卷積神經(jīng)不透明輻射場(convolutional neural opacity radiance field, ConvNeRF)。該模型基于捕獲系統(tǒng)的 RGBA 輸入,能夠在新視圖中實(shí)現(xiàn)高真實(shí)感、全局一致的外觀和不透明渲染,如下圖所示:
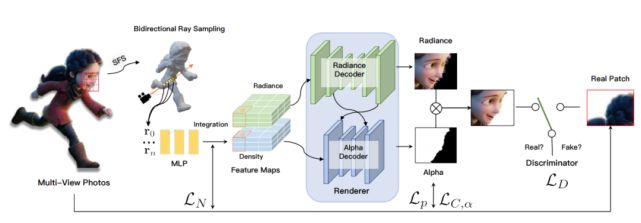
端到端 ConvNeRF pipeline 概覽
給定多視圖 RGBA 圖像,研究者使用 SFS(Shape-From-Silhouette)來為高效射線采樣推斷代理幾何。對于體積空間中的每個樣本點(diǎn),位置和方向都會饋入到一個基于多層感知機(jī)(MLP)的特征預(yù)測網(wǎng)絡(luò),以在全局水平上表征對象。然后,研究者將附近的射線合并為局部特征 patch,并使用卷積體渲染器將其解碼為 RGB 和蒙版。他們在最終輸出上使用對抗訓(xùn)練策略,以促成精細(xì)的表面細(xì)節(jié)。在 reference 階段,該方法一次渲染整個圖像,而不是渲染每個 patch。
該方法的主要思想是使用空間卷積機(jī)制對不透明信息進(jìn)行顯式編碼,以改進(jìn)神經(jīng)輻射場方法(NeRF),對高頻細(xì)節(jié)進(jìn)行建模。受 NeRF 啟發(fā),研究者采用了類似的隱式神經(jīng)輻射場來表征使用多層感知器的場景,以及沿投射射線方向預(yù)測密度和顏色值的體融合(volumetric integration)。
不同的是,ConvNeRF 通過空間卷積設(shè)計(jì)進(jìn)一步顯式編碼不透明度,以顯著改進(jìn)神經(jīng)輻射場重建。為此,研究者首先提出一種高效的采樣策略,不僅利用沿?cái)z像機(jī)光線的先驗(yàn)固有輪廓,還要編碼整個圖像平面上的空間信息。接著采用一種全局幾何表征法將 3D 位置映射成高級輻射特征,并通過一種新型體融合方案生成 per-patch 混合特征嵌入,這樣一來分別對外觀和不透明度的特征進(jìn)行建模,從而以 patch-wise 的方式進(jìn)行更高效的輻射場學(xué)習(xí)。
最后,研究者使用一個輕量級的 U-Net 來將特征 patch 解碼為視圖一致的外觀和不透明度輸出,并進(jìn)一步采用了一種 patch-wise 對抗訓(xùn)練方案,以在自監(jiān)督框架中保留高頻外觀和不透明度細(xì)節(jié)。
捕獲系統(tǒng)
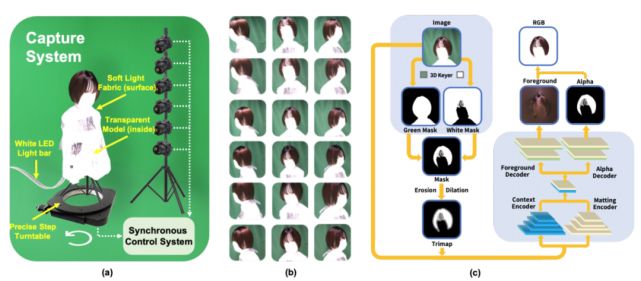
該研究用到的捕獲系統(tǒng)(capture system)能夠生成高質(zhì)量的多視圖 RGBA 圖像,用于對具有挑戰(zhàn)性的模糊目標(biāo)進(jìn)行顯式不透明度建模。
如下捕獲系統(tǒng)概覽圖所示,該方法的 pipeline 配備了易于使用的捕獲設(shè)備以及穩(wěn)定的校驗(yàn)和自動摳圖方法。
實(shí)驗(yàn)結(jié)果
該研究在多種毛茸茸物體上評估了 ConvNeRF。定量和定性評估實(shí)驗(yàn)的結(jié)果表明:與之前的工作相比,該方法可以更好地保留高保真外觀細(xì)節(jié),并在任意新視圖中生成全局一致的 alpha 蒙版。該研究進(jìn)一步進(jìn)行了消融實(shí)驗(yàn),以驗(yàn)證該方法的設(shè)計(jì)選擇。
如下圖 6 所示,在 Cat、Girl、Wolf 數(shù)據(jù)集上,研究者對該方法與 IBOH、NOPC、和 NeRF 的自由視點(diǎn) RGB 進(jìn)行了對比。結(jié)果發(fā)現(xiàn),該方法能夠在保留幾何全局視圖一致性的同時重建幾何和外觀上的精細(xì)細(xì)節(jié),例如貓的毛皮紋理、女孩靴子上的圖案以及狼毛的幾何細(xì)節(jié)。IBOH 表現(xiàn)出重影和混疊,NOPC 存在過度模糊和幾何細(xì)節(jié)的損失,而 NeRF 則表現(xiàn)出過多的噪聲和模糊。
下圖 7 展示了在 Cat、Hairstyle 2 數(shù)據(jù)集上,該方法與 IBOH、NOPC 和 NeRF 的自由視點(diǎn) Alpha 效果比較。結(jié)果發(fā)現(xiàn),該方法可以從視線不一致的 alpha 蒙版中恢復(fù)缺失的部分不透明度,例如貓的胡須,如第一行所示,而 IBOH 則會失敗,并出現(xiàn)嚴(yán)重的偽影。該方法可以產(chǎn)生比 NOPC 更銳利(sharp)的 alpha 蒙版,后者會在頭發(fā)周圍產(chǎn)生嚴(yán)重的偽影。而 NeRF 在富有挑戰(zhàn)性的 Hairstyle 2 數(shù)據(jù)集上失敗了。

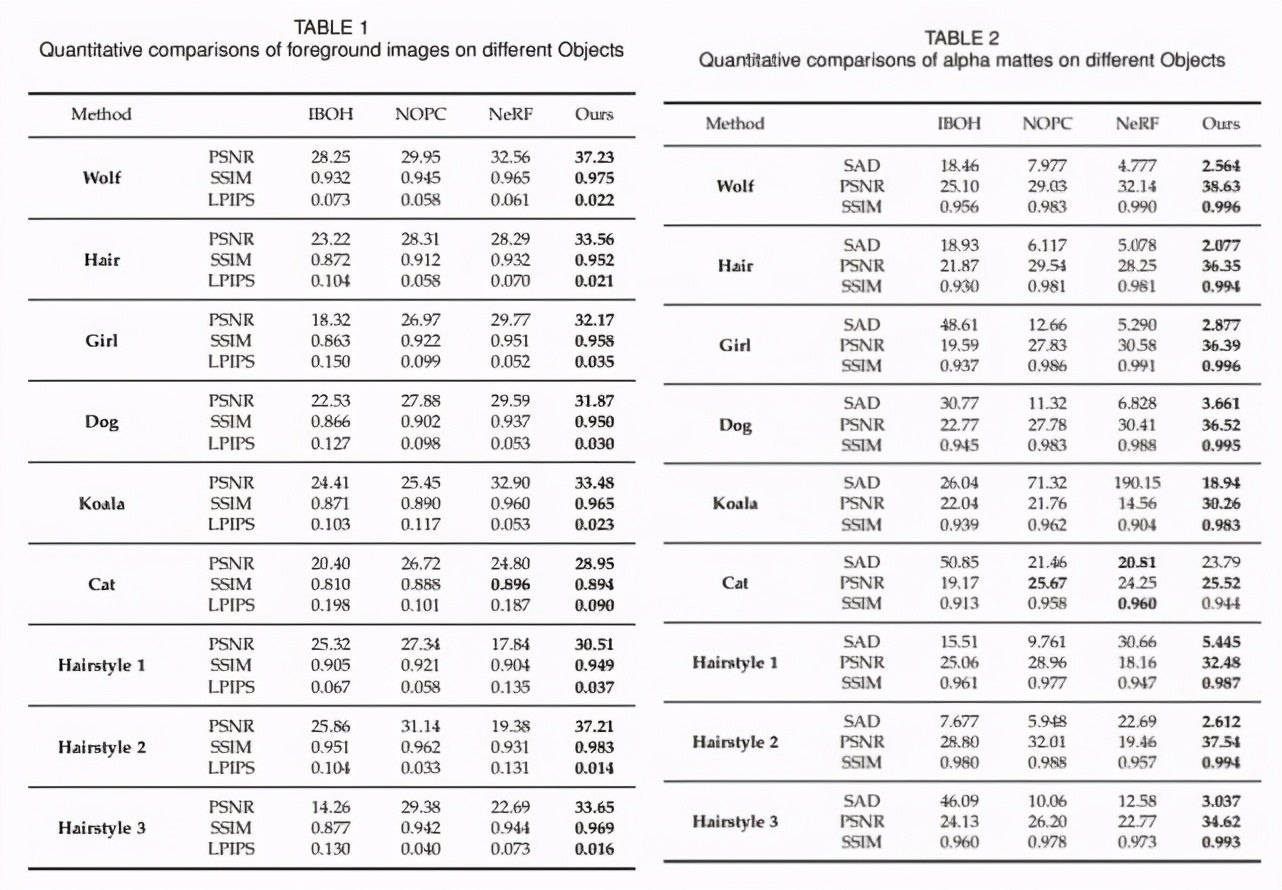
在定量評估方面,研究者使用 PSNR、LPIPS 和 SSIM 作為指標(biāo)定量評估了幾種方法。如下表 1 和表 2 所示,ConvNeRF 在 RGB 和 alpha 結(jié)果上都實(shí)現(xiàn)了顯著的性能提升。
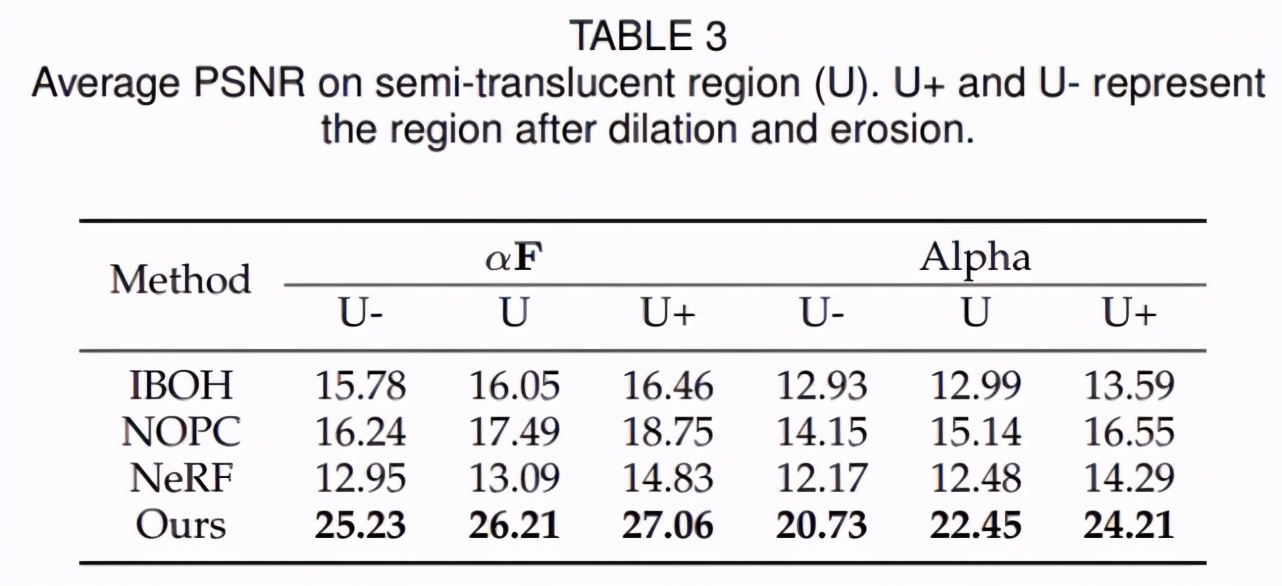
下表 3 展示了在半透明(即 0 < α < 1)區(qū)域上,所有數(shù)據(jù)集的平均 PSNR,該方法實(shí)現(xiàn)了 SOTA 性能。