













將Transformer用于擴散模型,AI 生成視頻達到照片級真實感
近日,一項視頻生成研究收獲了大量贊譽,甚至被一位 X 網友評價為「好萊塢的終結」。
真的有這么好嗎?我們先看下效果:


很明顯,這些視頻不僅幾乎看不到偽影,而且還非常連貫、細節滿滿,甚至似乎就算真的在電影大片中加上幾幀,也不會明顯違和。
這些視頻的作者是來自斯坦福大學、谷歌、佐治亞理工學院的研究者提出的 Window Attention Latent Transformer,即窗口注意力隱 Transformer,簡稱 W.A.L.T。該方法成功地將 Transformer 架構整合到了隱視頻擴散模型中。斯坦福大學的李飛飛教授也是該論文的作者之一。

- 項目網站:https://walt-video-diffusion.github.io/
- 論文地址:https://walt-video-diffusion.github.io/assets/W.A.L.T.pdf
在此之前,Transformer 架構已經在許多不同領域取得了巨大成功,但圖像和視頻生成式建模領域卻是一個例外,目前該領域的主導范式是擴散模型。
在圖像、視頻生成領域,擴散模型已經成為主要范式。但是,在所有視頻擴散方法中,主導的骨干網絡是由一系列卷積和自注意力層構成的 U-Net 架構。人們之所以偏好 U-Net,是因為 Transformer 中全注意力機制的內存需求會隨輸入序列長度而二次方增長。在處理視頻這樣的高維信號時,這樣的增長模式會讓計算成本變得非常高。
而隱擴散模型(LDM)可在源自自動編碼器的更低維隱空間中運行,從而降低計算需求。在這種情況下,一大關鍵的設計選擇是隱空間的類型:空間壓縮與時空壓縮。
人們往往更喜歡空間壓縮,因為這樣就能使用預訓練的圖像自動編碼器和 LDM,而它們使用了大量配對的圖像 - 文本數據集進行訓練。但是,如果選擇空間壓縮,則會提升網絡復雜度并會讓 Transformer 難以用作網絡骨干(由于內存限制),尤其是在生成高分辨率視頻時。另一方面,雖然時空壓縮可以緩解這些問題,但它卻不適合使用配對的圖像 - 文本數據集,而這些數據集往往比視頻 - 文本數據集更大更多樣化。
W.A.L.T 是一種用于隱視頻擴散模型(LVDM)的 Transformer 方法。
該方法由兩階段構成。
第一階段,用一個自動編碼器將視頻和圖像映射到一個統一的低維隱空間。這樣一來,就可以在圖像和視頻數據集上聯合訓練單個生成模型,并顯著降低生成高分辨率視頻的計算成本。
對于第二階段,該團隊設計了一種用于隱視頻擴散模型的新 Transformer 塊,其由自注意力層構成,這些自注意力層在非重疊、窗口限制的空間和時空注意力之間交替。這一設計的好處主要有兩個:首先,它使用了局部窗口注意力,這能顯著降低計算需求。其次,它有助于聯合訓練,其中空間層可以獨立地處理圖像和視頻幀,而時空層則用于建模視頻中的時間關系。
盡管概念上很簡單,但這項研究首次在公共基準上通過實驗證明 Transformer 在隱視頻擴散中具有卓越的生成質量和參數效率。
最后,為了展示新方法的可擴展性和效率,該團隊還實驗了高難度的照片級圖像到視頻生成任務。他們訓練了三個級聯在一起的模型。其中包括一個基礎隱視頻擴散模型和兩個視頻超分辨率擴散模型。最終能以每秒 8 幀的速度生成分辨率為 512×896 的視頻。在 UCF-101 基準上,這種方法取得了當前最佳的零樣本 FVD 分數。


此外,這個模型還可以用于生成具有一致的 3D 攝像機運動的視頻。

W.A.L.T
學習視覺 token
在視頻的生成式建模領域,一個關鍵的設計決策是隱空間表征的選擇。理想情況下,我們希望得到一種共享和統一的壓縮視覺表征,并且其可同時用于圖像和視頻的生成式建模。
具體來說,給定一個視頻序列 x,目標是學習一個低維表征 z,其以一定的時間和空間比例執行了時空壓縮。為了得到視頻和靜態圖像的統一表征,總是需要將視頻的第一幀與其余幀分開編碼。這樣一來,就可以將靜態圖像當作只有一幀的視頻來處理。
基于這種思路,該團隊的實際設計使用了 MAGVIT-v2 token 化器的因果 3D CNN 編碼器 - 解碼器架構。
這一階段之后,模型的輸入就成了一批隱張量,它們表示單個視頻或堆疊的分立圖像(圖 2)。并且這里的隱表征是實值的且無量化的。

學習生成圖像和視頻
Patchify(圖塊化)。按照原始 ViT 的設計,該團隊對每個隱含幀分別進行圖塊化,做法是將其轉換成一個不重疊圖塊的序列。他們也使用了可學習的位置嵌入,即空間和時間位置嵌入的和。位置嵌入會被添加到圖塊的線性投影中。注意,對于圖像而言,只需簡單地添加對應第一隱含幀的時間位置嵌入。
窗口注意力。完全由全局自注意力模塊組成的 Transformer 模型的計算和內存成本很高,尤其是對于視頻任務。為了效率以及聯合處理圖像和視頻,該團隊是以窗口方式計算自注意力,這基于兩種類型的非重疊配置:空間(S)和時空(ST),參見圖 2。
空間窗口(SW)注意力關注的是一個隱含幀內的所有 token。SW 建模的是圖像和視頻中的空間關系。時空窗口(STW)注意力的范圍是一個 3D 窗口,建模的是視頻隱含幀之間的時間關系。最后,除了絕對位置嵌入,他們還使用了相對位置嵌入。
據介紹,這個設計雖然簡單,但卻有很高的計算效率,并且能在圖像和視頻數據集上聯合訓練。不同于基于幀級自動編碼器的方法,新方法不會產生閃動的偽影,而這是分開編碼和解碼視頻幀方法的常見問題。
條件式生成
為了實現可控的視頻生成,除了以時間步驟 t 為條件,擴散模型還往往會使用額外的條件信息 c,比如類別標簽、自然語言、過去幀或低分辨率視頻。在新提出的 Transformer 骨干網絡中,該團隊整合了三種類型的條件機制,如下所述:
交叉注意力。除了在窗口 Transformer 塊中使用自注意力層,他們還為文本條件式生成添加了交叉注意力層。當只用視頻訓練模型時,交叉注意力層使用同樣窗口限制的注意力作為自注意力層,這意味著 S/ST 將具有 SW/STW 交叉注意力層(圖 2)。然而,對于聯合訓練,則只使用 SW 交叉注意力層。對于交叉注意力,該團隊的做法是將輸入信號(查詢)和條件信號 (key, value) 連接起來。
AdaLN-LoRA。在許多生成式和視覺合成模型中,自適應歸一化層都是重要組件。為了整合自適應歸一化層,一種簡單方法是為每一層 i 包含一個 MLP 層,以對條件參數的向量進行回歸處理。這些附加 MLP 層的參數數量會隨層的數量而線性增長,并會隨模型維度的變化二次增長。受 LoRA 啟發,研究者提出了一種減少模型參數的簡單方案:AdaLN-LoRA。
以自我為條件(Self-conditioning)。除了以外部輸入為條件,迭代式生成算法還能以自己在推理期間生成的樣本為條件。具體來說,Chen et al. 在論文《Analog bits: Generating discrete data using diffusion models with self-conditioning》中修改了擴散模型的訓練過程,使得模型有一定概率 p_sc 生成一個樣本,然后再基于這個初始樣本,使用另一次前向通過來優化這個估計。另有一定概率 1-p_sc 僅完成一次前向通過。該團隊沿通道維度將該模型估計與輸入連接到一起,然后發現這種簡單技術與 v-prediction 結合起來效果很好。
自回歸生成
為了通過自回歸預測生成長視頻,該團隊還在幀預測任務上對模型進行了聯合訓練。其實現方式是在訓練過程中讓模型有一定概率 p_fp 以過去幀為條件。條件要么是 1 個隱含幀(圖像到視頻生成),要么是 2 個隱含幀(視頻預測)。這種條件是通過沿有噪聲隱含輸入的通道維度整合進模型中。推理過程中使用的是標準的無分類器引導,并以 c_fp 作為條件信號。
視頻超分辨率
使用單個模型生成高分辨率視頻的計算成本非常高,基本難以實現。而研究者則參考論文《Cascaded diffusion models for high fidelity image generation》使用一種級聯式方法將三個模型級聯起來,它們操作的分辨率越來越高。
其中基礎模型以 128×128 的分辨率生成視頻,然后再經過兩個超分辨率階段被上采樣兩次。首先使用一種深度到空間卷積運算在空間上對低分辨率輸入(視頻或圖像)進行上采樣。請注意,不同于訓練(提供了基本真值低分辨率輸入),推理依靠的是之前階段生成的隱含表征。
為了減少這種差異并能在超分辨率階段更穩健地處理在低分辨率階段產生的偽影,該團隊還使用了噪聲條件式增強。
縱橫比微調。為了簡化訓練和利用具有不同縱橫比的更多數據源,他們在基礎階段使用的是方形縱橫比。然后他們又在一個數據子集上對模型進行了微調,通過位置嵌入插值來生成縱橫比為 9:16 的視頻。
實驗
研究者在多種任務上評估了新提出的方法:以類別為條件的圖像和視頻生成、幀預測、基于文本的視頻生成。他們也通過消融研究探索了不同設計選擇的效果。
視覺生成
視頻生成:在 UCF-101 和 Kinetics-600 兩個數據集上,W.A.L.T 在 FVD 指標上優于之前的所有方法,參見表 1。
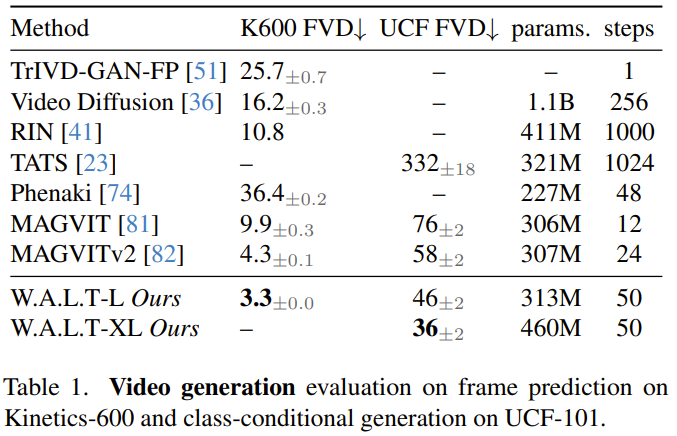
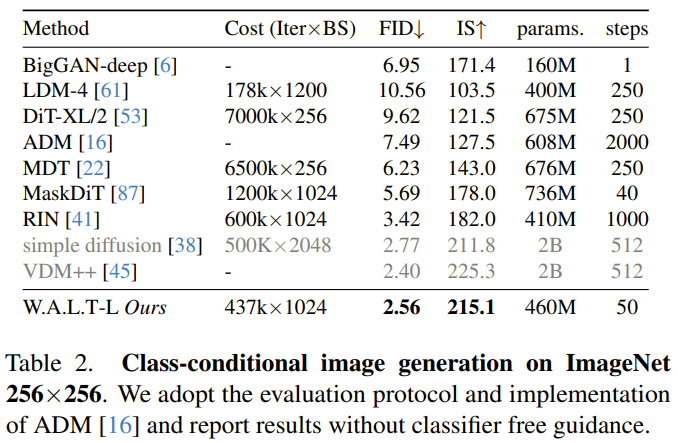
圖像生成:表 2 比較了 W.A.L.T 與其它當前最佳方法生成 256×256 分辨率圖像的結果。新提出的模型的表現優于之前的方法,并且不需要專門的調度、卷積歸納偏差、改進的擴散損失和無分類器指導。雖然 VDM++ 的 FID 分數略高一些,但它的模型參數卻多很多(2B)。
消融研究
為了理解不同設計決策的貢獻,該團隊也進行了消融研究。表 3 給出了在圖塊大小、窗口注意力、自我條件、AdaLN-LoRA 和自動編碼器方面的消融研究結果。

文本到視頻生成
該團隊在文本 - 圖像和文本 - 視頻對上聯合訓練了 W.A.L.T 的文本到視頻生成能力。他們使用了一個來自公共互聯網和內部資源的數據集,其中包含約 970M 對文本 - 圖像和約 89M 對文本 - 視頻。
基礎模型(3B)的分辨率為 17×128×128,兩個級聯的超分辨率模型則分別為 17×128×224 → 17×256×448 (L, 1.3B, p = 2) 和 17× 256×448→ 17×512×896 (L, 419M, p = 2)。他們也在基礎階段對縱橫比進行了微調,以便以 128×224 的分辨率生成視頻。所有的文本到視頻生成結果都使用了無分類器引導方法。
下面是一些生成的視頻示例,更多請訪問項目網站:
文本:A squirrel eating a burger.

文本:A cat riding a ghost rider bike through the desert.

定量評估
以科學方式評估基于文本的視頻生成還依然是一大難題,部分原因是缺乏標準化的訓練數據集和基準。到目前為止,研究者的實驗和分析都集中于標準的學術基準,它們使用了同樣的訓練數據,以確保比較是公平的對照。
盡管如此,為了與之前的文本到視頻生成研究比較,該團隊還是報告了在零樣本評估設置下在 UCF-101 數據集上的結果。
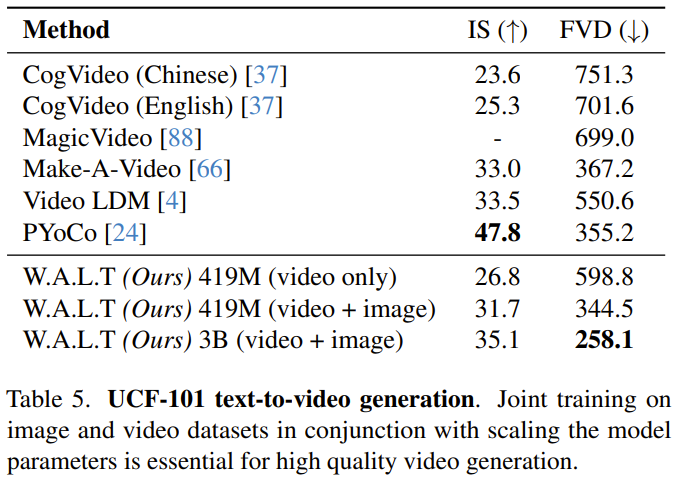
可以看到,W.A.L.T 的優勢很明顯。
更多細節請參考原論文。
























