谷歌推出新模型「pQRNN」,少量參數(shù)下進(jìn)行文本分類,性能堪比BERT
近日,谷歌推出了新模型「pQRNN」,它是由去年推出的「PRADO」進(jìn)一步使用小模型改進(jìn)而得,達(dá)到了SOTA結(jié)果。pQRNN的新穎之處在于,它可以結(jié)合一個(gè)簡(jiǎn)單的映射和一個(gè)quasi-RNN編碼器來(lái)進(jìn)行快速并行處理。同時(shí),谷歌證明了該模型能在參數(shù)較少的情況下進(jìn)行文本分類任務(wù),并達(dá)到BERT級(jí)別的性能表現(xiàn)。
深層神經(jīng)網(wǎng)絡(luò)的快速發(fā)展在過(guò)去的十年中徹底改變了自然語(yǔ)言處理(NLP)領(lǐng)域 。同時(shí),諸如保護(hù)用戶隱私、消除網(wǎng)絡(luò)延遲、啟用離線功能以及降低運(yùn)營(yíng)成本等問(wèn)題,迅速推動(dòng)了可以在移動(dòng)設(shè)備而不是在數(shù)據(jù)中心運(yùn)行的 NLP 模型的發(fā)展。
然而,因?yàn)橐苿?dòng)設(shè)備的內(nèi)存和處理能力有限,這就要求運(yùn)行在移動(dòng)設(shè)備上的模型體積小、效率高,而且不影響其結(jié)果的質(zhì)量。
去年,谷歌發(fā)表了一個(gè)名為「PRADO」的神經(jīng)結(jié)構(gòu),使用一個(gè)參數(shù)量小于200K 的模型,在許多文本分類問(wèn)題上取得了SOTA的結(jié)果。雖然大多數(shù)模型對(duì)每個(gè)token使用固定數(shù)量的參數(shù),但是 PRADO 模型使用的網(wǎng)絡(luò)結(jié)構(gòu)需要極少的參數(shù)來(lái)學(xué)習(xí)任務(wù)最相關(guān)或最有用的token。
PRADO是如何工作的
在一年前開(kāi)發(fā)時(shí),PRADO 利用了 NLP 領(lǐng)域特有的文本分割來(lái)減少模型的大小并提高性能。
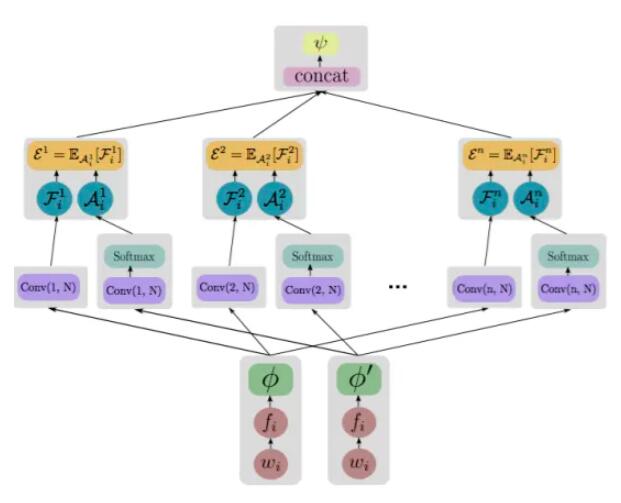
圖:PRADO的模型結(jié)構(gòu)
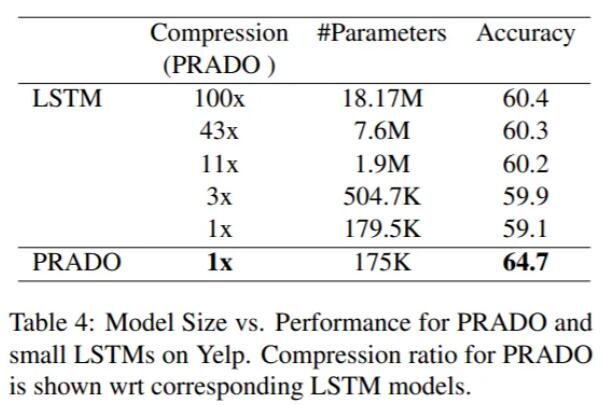
圖:PRADO和LSTM在Yelp數(shù)據(jù)集上的對(duì)比
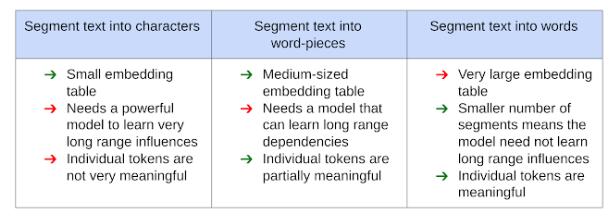
通常,NLP 模型的文本輸入首先被處理成適合輸入神經(jīng)網(wǎng)絡(luò)的形式,將文本分割成與預(yù)定義的通用字典(包含所有可能的token列表)中的值相對(duì)應(yīng)的Segment。
然后,神經(jīng)網(wǎng)絡(luò)使用可訓(xùn)練的參數(shù)惟一地識(shí)別每個(gè)Segment,該參數(shù)包括Embedding table。然而這種利用文本分割的方式對(duì)模型的性能、大小和延遲有很大的影響。
下圖顯示了使用各種的方法及其優(yōu)缺點(diǎn):
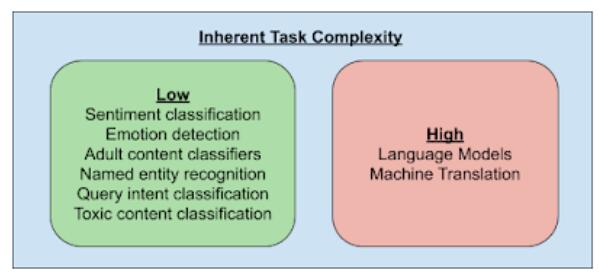
由于文本片段的數(shù)量是模型性能和壓縮的一個(gè)重要參數(shù),從而產(chǎn)生了一個(gè)問(wèn)題: NLP 模型是否需要能夠清楚地識(shí)別每一個(gè)可能的文本片段。為了回答這個(gè)問(wèn)題,谷歌還研究了 NLP 任務(wù)的內(nèi)在復(fù)雜性。
只有少數(shù) NLP 任務(wù)(例如語(yǔ)言模型和機(jī)器翻譯)需要知道文本片段之間的細(xì)微差別,因此需要能夠唯一地識(shí)別所有可能的文本片段。相比之下,其他大多數(shù)任務(wù)可以通過(guò)了解這些片段的一個(gè)小子集來(lái)解決。
此外,與任務(wù)相關(guān)的片段的子集可能不是最常見(jiàn)的片段,如 a,an,the 等,這對(duì)于許多任務(wù)來(lái)說(shuō)是無(wú)用的片段。因此,允許網(wǎng)絡(luò)為給定的任務(wù)確定最相關(guān)的部分可以帶來(lái)更好的性能。
此外,模型不需要能夠唯一地識(shí)別這些片段,只需要識(shí)別文本片段的簇。例如,情感分類器只需要知道與文本中的情感密切相關(guān)的簇即可。
利用這些發(fā)現(xiàn),PRADO 被設(shè)計(jì)用來(lái)學(xué)習(xí)來(lái)自單詞而不是單詞片段或字符的文本片段簇,這使它能夠在低復(fù)雜度的 NLP 任務(wù)中取得良好的表現(xiàn)。由于單詞粒度更有意義,而且對(duì)于大多數(shù)任務(wù)來(lái)說(shuō)最相關(guān)的單詞數(shù)量很少,所以學(xué)習(xí)這樣一個(gè)相關(guān)單詞構(gòu)成的子集所需的模型參數(shù)就少得多。
pQRNND:改進(jìn)PRADO
在 PRADO 成功的基礎(chǔ)上,我們提出了一種改進(jìn)的NLP模型 pQRNN。該模型由三個(gè)構(gòu)建塊、一個(gè)將文本中的token轉(zhuǎn)換為三元向量序列的投影算子、一個(gè)稠密的bottleneck層和一堆 QRNN 編碼器組成。
pQRNN 中投影層的實(shí)現(xiàn)與 PRADO 中使用的相同,并幫助模型學(xué)習(xí)最相關(guān)的tokens,而不需要使用一組固定的參數(shù)來(lái)定義它們。它首先在文本中標(biāo)記出tokens,并使用一個(gè)簡(jiǎn)單的映射函數(shù)轉(zhuǎn)換成三元特征向量。
這使得這個(gè)三元向量序列具有平衡的對(duì)稱分布并且可以唯一地表示文本。這種表示并不直接有用,因?yàn)樗鼪](méi)有解決所關(guān)心的任務(wù)所需的任何信息,而且網(wǎng)絡(luò)也無(wú)法控制這種表示。
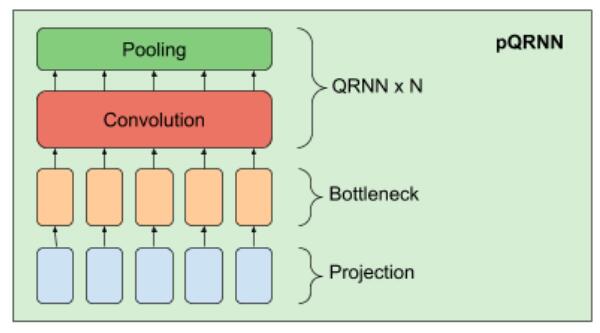
我們將它傳入一個(gè)密集的bottleneck層,使網(wǎng)絡(luò)能夠?qū)W習(xí)與當(dāng)前的任務(wù)相關(guān)的單詞表示法,但bottleneck層產(chǎn)生的表示仍然沒(méi)有考慮到單詞的上下文。
接下來(lái)通過(guò)使用一堆雙向 QRNN 編碼器來(lái)學(xué)習(xí)上下文表示,其結(jié)果就是使得網(wǎng)絡(luò)能夠從沒(méi)有經(jīng)過(guò)預(yù)處理的輸入文本中學(xué)習(xí)到上下文表示。
pQRNN的性能表現(xiàn)
作者在civil-comments數(shù)據(jù)集上對(duì) pQRNN 進(jìn)行評(píng)估,并在同一任務(wù)上與 BERT 模型進(jìn)行比較。
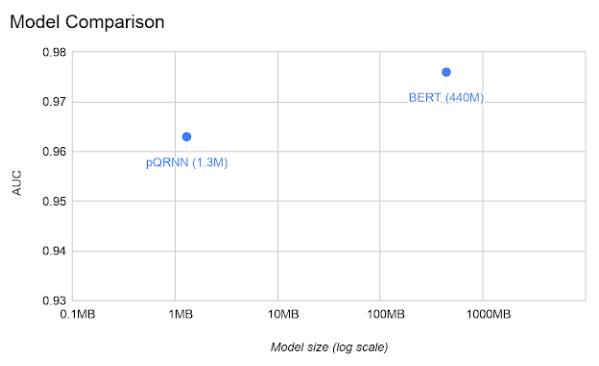
簡(jiǎn)單地說(shuō),因?yàn)槟P痛笮∨c參數(shù)數(shù)目成正比,故pQRNN參數(shù)比 BERT 小得多。此外,pQRNN 是量化處理過(guò)的,進(jìn)一步減少了4倍的模型大小。
公開(kāi)訓(xùn)練的 BERT 版本在這項(xiàng)任務(wù)上表現(xiàn)不佳,因此將其與通過(guò)幾個(gè)不同相關(guān)多語(yǔ)種數(shù)據(jù)源預(yù)訓(xùn)練后的BERT版本進(jìn)行比較,以獲得盡可能好的性能。
結(jié)論:輕量級(jí)文本分類神器
通過(guò)使用上一代模型PRADO證明了它可以作為下一代最先進(jìn)的輕量級(jí)文本分類模型的基礎(chǔ)。改進(jìn)后的pQRNN模型表明這種新的體系結(jié)構(gòu)幾乎可以達(dá)到BERT級(jí)的性能,盡管只使用1/300的參數(shù)量和有監(jiān)督的數(shù)據(jù)。
為了促進(jìn)這一領(lǐng)域的進(jìn)一步研究,谷歌現(xiàn)在已經(jīng)開(kāi)源了 PRADO 模型,并鼓勵(lì)社區(qū)使用它作為新模型架構(gòu)的起點(diǎn)。
項(xiàng)目地址:https://github.com/tensorflow/models/tree/master/research/sequence_projection