性能媲美BERT,參數(shù)量僅為1/300,谷歌最新的NLP模型
在最新的博客文章中,谷歌公布了一個新的 NLP 模型,在文本分類任務(wù)上可以達到 BERT 級別的性能,但參數(shù)量僅為 BERT 的 1/300。
在過去的十年中,深度神經(jīng)網(wǎng)絡(luò)從根本上變革了自然語言處理(NLP)領(lǐng)域的發(fā)展,但移動端有限的內(nèi)存和處理能力對模型提出了更高的要求。人們希望它們可以變得更小,但性能不打折扣。
去年,谷歌發(fā)布了一種被稱為 PRADO 的神經(jīng)架構(gòu),該架構(gòu)當時在許多文本分類問題上都實現(xiàn)了 SOTA 性能,并且參數(shù)量少于 200K。大多數(shù)模型對每個 token 使用固定數(shù)目的參數(shù),而 PRADO 模型使用的網(wǎng)絡(luò)結(jié)構(gòu)只需要很少的參數(shù)即可學(xué)習(xí)與任務(wù)最相關(guān)或最有用的 token。

論文鏈接:https://www.aclweb.org/anthology/D19-1506.pdf
在最新的博客文章中,谷歌的研究者宣布它們改進了 PRADO,并將改進后的模型稱為 pQRNN。新模型以最小的模型尺寸達到了 NLP 任務(wù)的新 SOTA。pQRNN 的新穎之處在于,它將簡單的投影運算與 quasi-RNN 編碼器相結(jié)合,以進行快速、并行的處理。該研究表明,pQRNN 模型能夠在文本分類任務(wù)上實現(xiàn) BERT 級別的性能,但參數(shù)量僅為原來的 1/300。
PRADO 的工作原理
在一年前開發(fā)該模型時,PRADO 在文本分割上充分利用特定領(lǐng)域的 NLP 知識,以降低模型大小和提升模型性能。通常來說,首先通過將文本分割成與預(yù)定義通用詞典中的值相對應(yīng)的 token,將 NLP 模型的文本輸入處理成適用于神經(jīng)網(wǎng)絡(luò)的形式。然后,神經(jīng)網(wǎng)絡(luò)使用可訓(xùn)練參數(shù)向量(包括嵌入表)來唯一識別每個文本片段。但是,文本分割的方式對模型性能、大小和延遲都有顯著的影響。
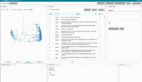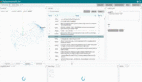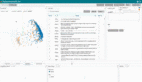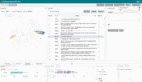
下圖展示了 NLP 社區(qū)使用的各種文本分割方法及其相應(yīng)的優(yōu)缺點:
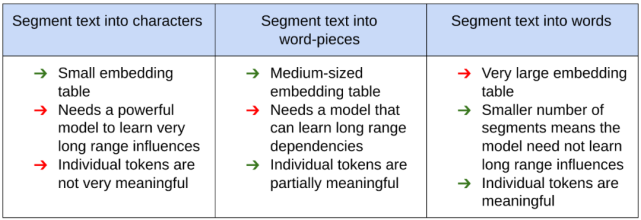
由于文本片段的數(shù)量是影響模型性能和壓縮的重要參數(shù),因此引出了一個問題,即 NLP 模型是否需要能夠清楚地識別每個可能的文本片段。為了回答這個問題,研究者探索了 NLP 任務(wù)的固有復(fù)雜性。
只有語言建模和機器翻譯等少數(shù) NLP 任務(wù)需要了解文本片段之間的細微差異,因此可能需要唯一識別所有可能的文本片段。其他大多數(shù)任務(wù)僅通過了解這些文本片段的子集即可解決。此外,任務(wù)相關(guān)的文本片段子集并不一定是頻率最高的部分,因為可能很大一部分是專用的冠詞,如 a、an 和 the,而這些對很多任務(wù)來說并不重要。
所以,允許網(wǎng)絡(luò)決定給定任務(wù)的最相關(guān)片段可以實現(xiàn)更好的性能。并且,網(wǎng)絡(luò)不需要唯一識別這些文本片段,只需要識別出文本片段的聚類即可。舉例而言,情感分類器只需要了解與文本中的情感強相關(guān)的片段聚類就行了。
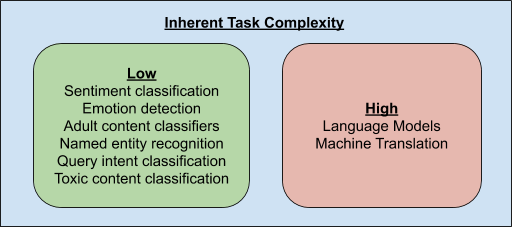
基于此,PRADO 被設(shè)計成從詞(word)中學(xué)習(xí)文本片段的聚類,而不是 word piece 或字符,從而使它能夠在低復(fù)雜度 NLP 任務(wù)中實現(xiàn)良好的性能。由于 word unit 更有意義,而且與大多數(shù)任務(wù)最相關(guān)的詞并不多,所以學(xué)習(xí)相關(guān)詞聚類的簡化子集所需要的模型參數(shù)就少了很多。
改進 PRADO
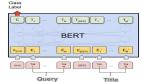
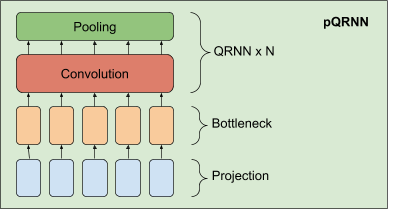
谷歌研究者在 PRADO 的基礎(chǔ)上開發(fā)了一個更強的 NLP 模型——pQRNN。該模型由三個構(gòu)建塊組成——一個是將文本中的 token 轉(zhuǎn)化為三元向量序列的投影算子、一個密集 bottleneck 層和若干 QRNN 編碼器。
pQRNN 中投影層的實現(xiàn)與 PRADO 中所用到的一致,幫助模型學(xué)習(xí)相關(guān)性最強的 token,但沒有一組固定的參數(shù)來定義這些 token。它首先對文本中的 token 進行識別,然后使用一個簡單的映射函數(shù)將其轉(zhuǎn)換為三元特征向量。這將產(chǎn)生一個三元向量序列,該序列具有平衡對稱分布,用來表示文本。這種表示沒有直接用途,因為它不包含解決感興趣任務(wù)所需的任何信息,而且網(wǎng)絡(luò)無法控制這種表示。
研究者將其與一個密集 bottleneck 層結(jié)合在一起,以使網(wǎng)絡(luò)可以學(xué)習(xí)到一個與手頭任務(wù)相關(guān)的逐詞表示。bottleneck 層產(chǎn)生的表示仍然沒有考慮到詞的上下文。因此,研究者利用若干雙向 QRNN 編碼器學(xué)習(xí)了一個上下文表示。這樣可以得到一個僅從文本輸入就能學(xué)到上下文表示的網(wǎng)絡(luò),并且無需任何預(yù)處理。
pQRNN 的性能
研究者在 civil_comments 數(shù)據(jù)集上評估了 pQRNN,并將其與 BERT 模型在相同的任務(wù)中進行了比較。模型的大小與其參數(shù)量成正比,因此 pQRNN 比 BERT 小得多。
此外,pQRNN 還進行了量化處理(quantized),因此模型體積進一步縮小到原來的 1/4。公開訓(xùn)練的 BERT 在本文的任務(wù)中表現(xiàn)不好,因此拿來對比的 BERT 其實是在幾個不同的相關(guān)多語言數(shù)據(jù)源上進行預(yù)訓(xùn)練得到的,以使其達到最好的表現(xiàn)。
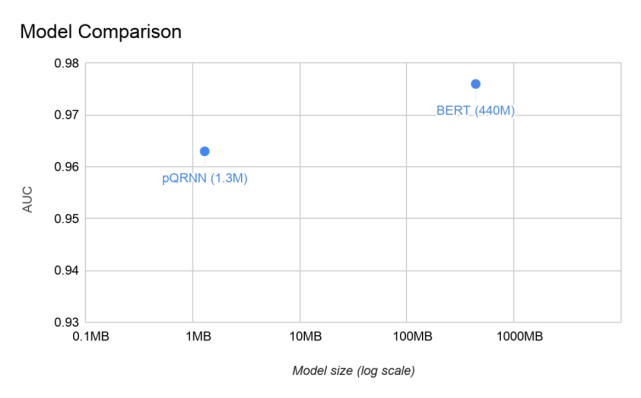
在實驗中,研究者得到了兩個模型的 AUC 信息。在沒有任何預(yù)訓(xùn)練、只在監(jiān)督數(shù)據(jù)訓(xùn)練的情況下,pQRNN 的 AUC 是 0.963,用到了 130 萬個量化(8-bit)參數(shù)。在幾個不同數(shù)據(jù)源進行預(yù)訓(xùn)練并在監(jiān)督數(shù)據(jù)上進行微調(diào)之后,BERT 模型得到的 AUC 是 0.976,用到了 1.1 億個浮點參數(shù)。
為了鼓勵社區(qū)在谷歌研究成果的基礎(chǔ)上做出進一步改進,谷歌還開源了 PRADO 模型。
項目地址:https://github.com/tensorflow/models/tree/master/research/sequence_projection