參數少量提升,性能指數爆發!谷歌:大語言模型暗藏「神秘技能」
由于可以做一些沒訓練過的事情,大型語言模型似乎具有某種魔力,也因此成為了媒體和研究員炒作和關注的焦點。
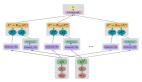
當擴展大型語言模型時,偶爾會出現一些較小模型沒有的新能力,這種類似于「創造力」的屬性被稱作「突現」能力,代表我們向通用人工智能邁進了一大步。
如今,來自谷歌、斯坦福、Deepmind和北卡羅來納大學的研究人員,正在探索大型語言模型中的「突現」能力。

解碼器提示的 DALL-E
神奇的「突現」能力
自然語言處理(NLP)已經被基于大量文本數據訓練的語言模型徹底改變。擴大語言模型的規模通常會提高一系列下游NLP任務的性能和樣本效率。
在許多情況下,我們可以通過推斷較小模型的性能趨勢預測大型語言模型的性能。例如,規模對語言模型困惑的影響已被驗證跨越超過七個數量級。
然而,某些其他任務的性能卻并沒有以可預測的方式提高。
例如,GPT-3的論文表明,語言模型執行多位數加法的能力對于從100M到13B參數的模型具有平坦的縮放曲線,近似隨機,但會在一個節點造成性能的飛升。

鑒于語言模型在NLP研究中的應用越來越多,因此更好地理解這些可能意外出現的能力非常重要。
在近期發表在機器學習研究(TMLR)上的論文「大型語言模型的突現能力」中,研究人員展示了數十個擴展語言模型所產生的「突現」能力的例子。
這種「突現」能力的存在提出了一個問題,即額外的縮放是否能進一步擴大語言模型的能力范圍。

某些提示和微調方法只會在更大的模型中產生改進
「突現」提示任務
首先,我們討論在提示任務中可能出現的「突現」能力。
在此類任務中,預先訓練的語言模型會被提示執行下一個單詞預測的任務,并通過完成響應來執行任務。
如果沒有任何進一步的微調,語言模型通常可以執行訓練期間沒有看到的任務。

當任務在特定規模閾值下不可預測地從隨機性能飆升至高于隨機性能時,我們將其稱為「突現」任務。
下面我們展示了三個具有「突現」表現的提示任務示例:多步算術、參加大學水平的考試和識別單詞的預期含義。
在每種情況下,語言模型的表現都很差,對模型大小的依賴性很小,直到達到某個閾值——它們的性能驟升。

對于足夠規模的模型,這些任務的性能只會變得非隨機——例如,算術和多任務NLU任務的訓練每秒浮點運算次數(FLOP)超過10的22次方,上下文任務中單詞的訓練FLOP超過10的24次方。
「突現」提示策略
第二類「突現」能力包括增強語言模型能力的提示策略。
提示策略是用于提示的廣泛范式,可應用于一系列不同的任務。當它們對小型模型失敗并且只能由足夠大的模型使用時,它們被認為是可「突現」的。
思維鏈提示是「突現」提示策略的一個典型示例,提示模型在給出最終答案之前生成一系列中間步驟。
思維鏈提示使語言模型能夠執行需要復雜推理的任務,例如多步數學單詞問題。
值得一提的是,模型無需經過明確培訓即可獲得思維鏈推理的能力,下圖則顯示了一個思維鏈提示的示例。

思維鏈提示的實證結果如下所示。

對于較小的模型,應用思維鏈提示并不會優于標準提示,例如當應用于GSM8K時,這是一個具有挑戰性的數學文字問題基準。
然而對于大型模型,思維鏈提示在GSM8K上達到了57%的解決率,在我們的測試中性能顯著提升。
研究「突現」能力的意義
那么研究「突現」能力,又究竟有什么意義呢?
識別大型語言模型中的「突現」能力,是理解此類現象及其對未來模型能力的潛在影響的第一步。
例如,由于「突現」小樣本提示能力和策略沒有在預訓練中明確編碼,研究人員可能不知道當前語言模型的小樣本提示能力的全部范圍。
此外,進一步擴展是否會潛在地賦予更大的模型「突現」能力,這個問題同樣十分重要。
- 為什么會出現「突現」能力?
- 當某些能力出現時,語言模型的新現實世界應用會被解鎖嗎?
- 由于計算資源昂貴,能否在不增加擴展性的情況下通過其他方法解鎖突現」能力(例如更好的模型架構或訓練技術)?
研究人員表示,這些問題尚且不得而知。
不過隨著NLP領域的不斷發展,分析和理解語言模型的行為,包括由縮放產生的「突現」能力,是十分重要的。