譯者 | 陳峻
審校 | 重樓
在本文中,我將向您介紹“少樣本(Few-shot)學習”的相關概念,并重點討論被廣泛應用于文本分類的SetFit方法。

傳統的機器學習(ML)
在監督(Supervised)機器學習中,大量數據集被用于模型訓練,以便磨練模型能夠做出精確預測的能力。在完成訓練過程之后,我們便可以利用測試數據,來獲得模型的預測結果。然而,這種傳統的監督學習方法存在著一個顯著缺點:它需要大量無差錯的訓練數據集。但是并非所有領域都能夠提供此類無差錯數據集。因此,“少樣本學習”的概念應運而生。
在深入研究Sentence Transformer fine-tuning(SetFit)之前,我們有必要簡要地回顧一下自然語言處理(Natural Language Processing,NLP)的一個重要方面,也就是:“少樣本學習”。
少樣本學習
少樣本學習是指:使用有限的訓練數據集,來訓練模型。模型可以從這些被稱為支持集的小集合中獲取知識。此類學習旨在教會少樣本模型,辨別出訓練數據中的相同與相異之處。例如,我們并非要指示模型將所給圖像分類為貓或狗,而是指示它掌握各種動物之間的共性和區別。可見,這種方法側重于理解輸入數據中的相似點和不同點。因此,它通常也被稱為元學習(meta-learning)、或是從學習到學習(learning-to-learn)。
值得一提的是,少樣本學習的支持集,也被稱為k向(k-way)n樣本(n-shot)學習。其中“k”代表支持集里的類別數。例如,在二分類(binary classification)中,k 等于 2。而“n”表示支持集中每個類別的可用樣本數。例如,如果正分類有10個數據點,而負分類也有10個數據點,那么 n就等于10。總之,這個支持集可以被描述為雙向10樣本學習。
既然我們已經對少樣本學習有了基本的了解,下面讓我們通過使用SetFit進行快速學習,并在實際應用中對電商數據集進行文本分類。
SetFit架構
由Hugging Face和英特爾實驗室的團隊聯合開發的SetFit,是一款用于少樣本照片分類的開源工具。你可以在項目庫鏈接--https://github.com/huggingface/setfit?ref=hackernoon.com中,找到關于SetFit的全面信息。
就輸出而言,SetFit僅用到了客戶評論(Customer Reviews,CR)情感分析數據集里、每個類別的八個標注示例。其結果就能夠與由三千個示例組成的完整訓練集上,經調優的RoBERTa Large的結果相同。值得強調的是,就體積而言,經微優的RoBERTa模型比SetFit模型大三倍。下圖展示的是SetFit架構:
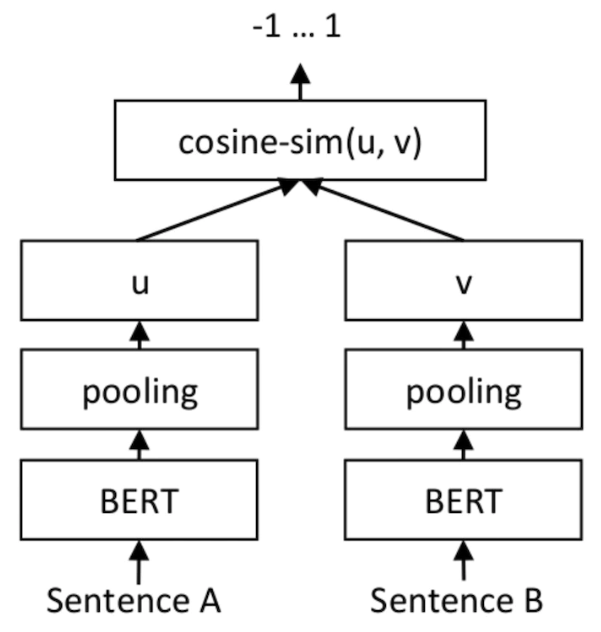
圖片來源:https://www.sbert.net/docs/training/overview.html?ref=hackernoon.com
用SetFit實現快速學習
SetFit的訓練速度非常快,效率也極高。與GPT-3和T-FEW等大模型相比,其性能極具競爭力。請參見下圖:
 SetFit與T-Few 3B模型的比較
SetFit與T-Few 3B模型的比較
如下圖所示,SetFit在少樣本學習方面的表現優于RoBERTa。
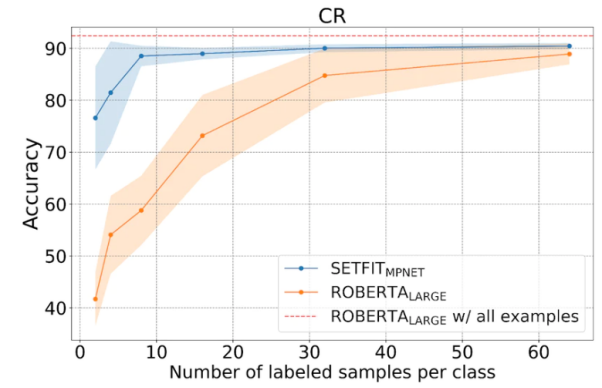
SetFit與RoBERT的比較,圖片來源:https://huggingface.co/blog/setfit?ref=hackernoon.com
數據集
下面,我們將用到由四個不同類別組成的獨特電商數據集,它們分別是:書籍、服裝與配件、電子產品、以及家居用品。該數據集的主要目的是將來自電商網站的產品描述歸類到指定的標簽下。
為了便于采用少樣本的訓練方法,我們將從四個類別中各選擇八個樣本,從而得到總共32個訓練樣本。而其余樣本則將留作測試之用。簡言之,我們在此使用的支持集是4向8樣本學習。下圖展示的是自定義電商數據集的示例:
 自定義電商數據集樣本
自定義電商數據集樣本
我們采用名為“all-mpnet-base-v2”的Sentence Transformers預訓練模型,將文本數據轉換為各種向量嵌入。該模型可以為輸入文本,生成維度為768的向量嵌入。
如下命令所示,我們將通過在conda環境(是一個開源的軟件包管理系統和環境管理系統)中安裝所需的軟件包,來開始SetFit的實施。
!pip3 install SetFit
!pip3 install sklearn
!pip3 install transformers
!pip3 install sentence-transformers安裝完軟件包后,我們便可以通過如下代碼加載數據集了。
from datasets import load_dataset
dataset = load_dataset('csv', data_files={
"train": 'E_Commerce_Dataset_Train.csv',
"test": 'E_Commerce_Dataset_Test.csv'
})我們來參照下圖,看看訓練樣本和測試樣本數。
 訓練和測試數據
訓練和測試數據
我們使用sklearn軟件包中的LabelEncoder,將文本標簽轉換為編碼標簽。
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()通過LabelEncoder,我們將對訓練和測試數據集進行編碼,并將編碼后的標簽添加到數據集的“標簽”列中。請參見如下代碼:
Encoded_Product = le.fit_transform(dataset["train"]['Label'])
dataset["train"] = dataset["train"].remove_columns("Label").add_column("Label", Encoded_Product).cast(dataset["train"].features)
Encoded_Product = le.fit_transform(dataset["test"]['Label'])
dataset["test"] = dataset["test"].remove_columns("Label").add_column("Label", Encoded_Product).cast(dataset["test"].features)下面,我們將初始化SetFit模型和句子轉換器(sentence-transformers)模型。
from setfit import SetFitModel, SetFitTrainer
from sentence_transformers.losses import CosineSimilarityLoss
model_id = "sentence-transformers/all-mpnet-base-v2"
model = SetFitModel.from_pretrained(model_id)
trainer = SetFitTrainer(
model=model,
train_dataset=dataset["train"],
eval_dataset=dataset["test"],
loss_class=CosineSimilarityLoss,
metric="accuracy",
batch_size=64,
num_iteratinotallow=20,
num_epochs=2,
column_mapping={"Text": "text", "Label": "label"}
)初始化完成兩個模型后,我們現在便可以調用訓練程序了。
trainer.train()在完成了2個訓練輪數(epoch)后,我們將在eval_dataset上,對訓練好的模型進行評估。
trainer.evaluate()經測試,我們的訓練模型的最高準確率為87.5%。雖然87.5%的準確率并不算高,但是畢竟我們的模型只用了32個樣本進行訓練。也就是說,考慮到數據集規模的有限性,在測試數據集上取得87.5%的準確率,實際上是相當可觀的。
此外,SetFit還能夠將訓練好的模型,保存到本地存儲器中,以便后續從磁盤加載,用于將來的預測。
trainer.model._save_pretrained(save_directory="SetFit_ECommerce_Output/")
model=SetFitModel.from_pretrained("SetFit_ECommerce_Output/", local_files_notallow=True)如下代碼展示了根據新的數據進行的預測結果:
input = ["Campus Sutra Men's Sports Jersey T-Shirt Cool-Gear: Our Proprietary Moisture Management technology. Helps to absorb and evaporate sweat quickly. Keeps you Cool & Dry. Ultra-Fresh: Fabrics treated with Ultra-Fresh Antimicrobial Technology. Ultra-Fresh is a trademark of (TRA) Inc, Ontario, Canada. Keeps you odour free."]
output = model(input)可見,其預測輸出為1,而標簽的LabelEncoded值為“服裝與配件”。由于傳統的AI模型需要大量的訓練資源(包括時間和數據),才能有穩定水準的輸出。而我們的模型與之相比,既準確又高效。
至此,相信您已經基本掌握了“少樣本學習”的概念,以及如何使用SetFit來進行文本分類等應用。當然,為了獲得更深刻的理解,我強烈建議您選擇一個實際場景,創建一個數據集,編寫對應的代碼,并將該過程延展到零樣本學習、以及單樣本學習上。
譯者介紹
陳峻(Julian Chen),51CTO社區編輯,具有十多年的IT項目實施經驗,善于對內外部資源與風險實施管控,專注傳播網絡與信息安全知識與經驗。
原文標題:Mastering Few-Shot Learning with SetFit for Text Classification,作者:Shyam Ganesh S)