













120億Stable LM 2上線即開源!2萬億token訓(xùn)練,碾壓Llama 2 70B
繼16億輕量級(jí)Stable LM 2推出之后,12B參數(shù)的版本在今天亮相了。
見狀,不少網(wǎng)友紛紛喊話:干的漂亮!但,Stable Diffusion 3啥時(shí)候出啊?


總得來說,Stable LM 2 12B參數(shù)更多,性能更強(qiáng)。
120億參數(shù)版本包含了基礎(chǔ)模型和指令微調(diào)模型,并在七種多語言,高達(dá)2萬億Token數(shù)據(jù)集上完成訓(xùn)練。
在基準(zhǔn)測(cè)試中,其性能趕超Llama 2 70B等開源模型。
官博介紹,最新版本的模型兼顧了性能、效率、內(nèi)存需求和速度,同時(shí)繼續(xù)采用了Stable LM 2 1.6B模型的框架。
通過這次更新,研究人員還為開發(fā)者提供了一個(gè)透明而強(qiáng)大的工具,以推動(dòng)AI語言技術(shù)的創(chuàng)新。

模型地址:https://huggingface.co/stabilityai/stablelm-2-12b
雖然目前只支持4K的上下文窗口,但你先別急。
Stability AI表示很快就會(huì)推出更長(zhǎng)的版本,并且可以第一時(shí)間在Hugging Face上獲取。

12B參數(shù)即可實(shí)現(xiàn)SOTA
Stable LM 2 12B是一個(gè)專為處理多種語言任務(wù)設(shè)計(jì)的高效開源模型,它能夠在大多數(shù)常見硬件上流暢運(yùn)行。
值得一提的是,Stable LM 2 12B可以處理通常只有大模型才能完成的各種任務(wù)。
比如混合專家模型(MoE),往往需要大量的計(jì)算和內(nèi)存資源。
此外,指令微調(diào)版本在工具使用,以及函數(shù)調(diào)用展現(xiàn)出強(qiáng)大的能力,可以適用于各種用途,包括作為檢索RAG系統(tǒng)的核心部分。
性能評(píng)估
在性能方面,參與對(duì)比的有Mixtral(MoE,總共47B/激活13B)、Llama2(13B和70B)、Qwen 1.5(14B)、Gemma(8.5B)和Mistral(7B)。
根據(jù)Open LLM Leaderboard和最新修正的MT-Bench基準(zhǔn)測(cè)試的結(jié)果顯示,Stable LM 2 12B在零樣本以及少樣本的任務(wù)上展現(xiàn)了出色的性能。

MT Bench

Open LLM Leaderboard

Open LLM Leaderboard

0-Shot NLP Tasks
在這個(gè)新版本中,他們將StableLM 2系列模型擴(kuò)展到了12B類別,提供了一個(gè)開放、透明的模型,在功率和精度方面絲毫不打折扣。
Stable LM 2 1.6B技術(shù)報(bào)告
最初發(fā)布的Stable LM 2 1.6B已經(jīng)在Open LLM 排行榜上取得了領(lǐng)先地位,證明了其在同類產(chǎn)品中的卓越性能。

論文地址:https://arxiv.org/abs/2402.17834
模型預(yù)訓(xùn)練
訓(xùn)練大模型(LLM)的第一階段主要是學(xué)習(xí)如何利用大量不同的數(shù)據(jù)源來預(yù)測(cè)序列中的下一個(gè)token,這一階段也被稱之為訓(xùn)練。
它使模型能夠構(gòu)建適用于基本語言功能甚至更高級(jí)的生成和理解任務(wù)的通用內(nèi)部表示。
訓(xùn)練
研究人員按照標(biāo)準(zhǔn)的自回歸序列建模方法對(duì)Stable LM 2進(jìn)行訓(xùn)練,以預(yù)測(cè)下一個(gè)token。
他們從零開始訓(xùn)練模型,上下文長(zhǎng)度為4096,受益于FlashAttention-2的高效序列并行優(yōu)化。
訓(xùn)練以BFloat16混合精度進(jìn)行,同時(shí)將all-reduce操作保持在FP32中。
數(shù)據(jù)
模型性能受訓(xùn)練前數(shù)據(jù)設(shè)計(jì)決策的影響,包括源選擇和采樣權(quán)重。
訓(xùn)練中所用的數(shù)據(jù)均為公開數(shù)據(jù),大部分訓(xùn)練數(shù)據(jù)由其他LLM訓(xùn)練中使用的數(shù)據(jù)源組成,其中包括德語(DE)、西班牙語(ES)、法語(FR)、意大利語(IT)、荷蘭語(NL)和葡萄牙語(PT)的多語言數(shù)據(jù)。

仔細(xì)選擇不同數(shù)據(jù)域的混合比例至關(guān)重要,尤其是非英語數(shù)據(jù)和代碼數(shù)據(jù)。
下圖展示了Stable LM 2預(yù)訓(xùn)練數(shù)據(jù)集中各領(lǐng)域有效訓(xùn)練詞塊的百分比。
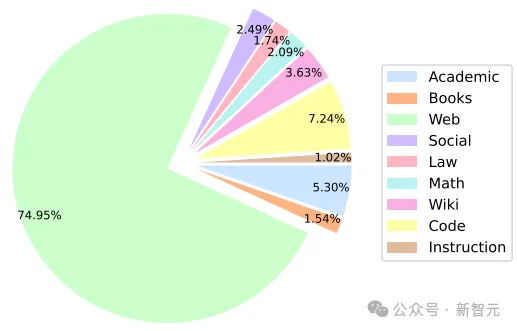
分詞器
研究人員使用了Arcade100k,這是一個(gè)從OpenAI的tiktoken.cl100k_base擴(kuò)展而來的BPE標(biāo)記器,其中包括用于代碼和數(shù)字拆分處理的特殊token。
詞庫(kù)由100,289個(gè)token組成,在訓(xùn)練過程中被填充為最接近的64的倍數(shù)(100,352),以滿足NVIDIA A100設(shè)備上推薦的Tensor Core對(duì)齊方式。
架構(gòu)
該模型在設(shè)計(jì)上與LLaMA架構(gòu)類似,下表顯示了一些關(guān)鍵的架構(gòu)細(xì)節(jié)。

其中,與LLaMA的主要區(qū)別如下:
1. 位置嵌入
旋轉(zhuǎn)位置嵌入應(yīng)用于頭嵌入尺寸的前25%,以提高后續(xù)吞吐量
2. 歸一化
相對(duì)于RMSNorm,LayerNorm具有學(xué)習(xí)偏置項(xiàng)
3. 偏置
從前饋網(wǎng)絡(luò)和多頭自注意層中刪除了鍵、查詢和值預(yù)測(cè)以外的所有偏置項(xiàng)。
模型微調(diào)
有監(jiān)督微調(diào)(SFT)
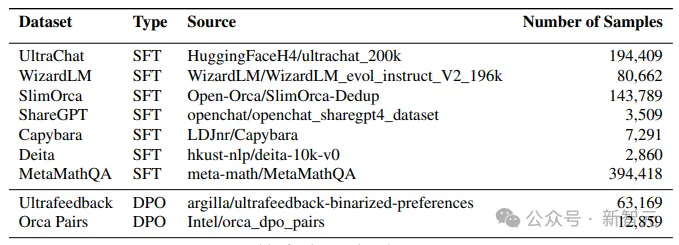
研究人員在Hugging Face Hub上公開的一些指令數(shù)據(jù)集上對(duì)預(yù)訓(xùn)練模型進(jìn)行微調(diào)。
尤其是使用了UltraChat、WizardLM、SlimOrca、ShareGPT、Capybara、Deita和MetaMathQA會(huì)話數(shù)據(jù)集,樣本總數(shù)為826,938個(gè)。
直接偏好優(yōu)化(DPO)
直接偏好優(yōu)化(Direct Preference Optimization,簡(jiǎn)稱 DPO)是 Zephyr-7B、Neural-Chat-7B和Tulu-2-DPO-70B等近期強(qiáng)模型的基本工具。
在應(yīng)用SFT后,通過DPO對(duì)得到的模型進(jìn)行微調(diào)。
在這個(gè)階段,他們使用UltraFeedback和Intel Orca Pairs這兩個(gè)數(shù)據(jù)集,并通過刪除了排名并列的配對(duì)、內(nèi)容重復(fù)的配對(duì)以及所選回應(yīng)得分低于80%的配對(duì)來過濾數(shù)據(jù)集。
實(shí)驗(yàn)結(jié)果和基準(zhǔn)測(cè)試
少樣本和零樣本評(píng)估
研究人員通過流行基準(zhǔn)評(píng)估了Stable LM 2的少樣本和零樣本能力,并將結(jié)果與類似大小的開源預(yù)訓(xùn)練模型進(jìn)行了比較。下表列出了模型評(píng)估結(jié)果。
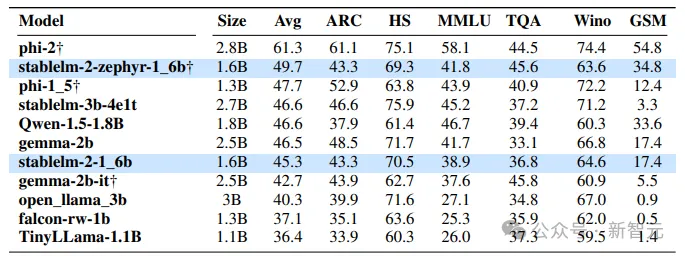
可以看出,Stable LM 2 1.6B (stablelm-2-1-6b)的性能明顯優(yōu)于其他基礎(chǔ)模型。
同樣,經(jīng)過指令微調(diào)的版本(stablelm-2-1-6b-dpo)比微軟的Phi-1.5平均提高了2%,但在幾發(fā)準(zhǔn)確率上卻落后于更大的Phi-2.0。與谷歌的Gemma 2B(2.5B參數(shù))相比,性能也有顯著提高。
多語種評(píng)估
通過在 ChatGPT 翻譯版本的 ARC、HS、TQA 和 MMLU 上進(jìn)行評(píng)估,來評(píng)估在多語言環(huán)境下的知識(shí)和推理能力。
此外,還使用了機(jī)器翻譯的LAMBADA數(shù)據(jù)集測(cè)試了下一個(gè)單詞的預(yù)測(cè)能力。
下表為zero-shot測(cè)試結(jié)果,可以看出與規(guī)模是其兩倍的模型相比,Stable LM 2的性能更加出眾。

MT基準(zhǔn)評(píng)估
他們還在流行的多輪基準(zhǔn)MT-Bench上測(cè)試了模型的對(duì)話能力。

Stable LM 2 1.6B顯示出具有競(jìng)爭(zhēng)力的性能,與MT-Bench上的大型模型能力相當(dāng)甚至更好。
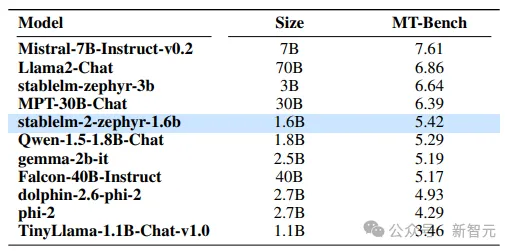
雖然該模型落后于Mistral 7B Instruct v0.2(比Stable LM 2大4倍多)等更強(qiáng)大的模型,但該模型提供了更好的聊天性能,并以較大優(yōu)勢(shì)擊敗了Phi-2、Gemma 2B和TinyLLaMA 1.1B這兩個(gè)大模型。






























