













數(shù)據(jù)閉環(huán)!DrivingGaussian:逼真環(huán)視數(shù)據(jù),駕駛場(chǎng)景重建SOTA
本文經(jīng)自動(dòng)駕駛之心公眾號(hào)授權(quán)轉(zhuǎn)載,轉(zhuǎn)載請(qǐng)聯(lián)系出處。
寫在前面&筆者的個(gè)人理解
北大王選計(jì)算機(jī)研究所的最新工作,提出了DrivingGaussian,一個(gè)高效、有效的動(dòng)態(tài)自動(dòng)駕駛場(chǎng)景框架。對(duì)于具有移動(dòng)目標(biāo)的復(fù)雜場(chǎng)景,首先使用增量靜態(tài)3D高斯對(duì)整個(gè)場(chǎng)景的靜態(tài)背景進(jìn)行順序和漸進(jìn)的建模。然后利用復(fù)合動(dòng)態(tài)高斯圖來(lái)處理多個(gè)移動(dòng)目標(biāo),分別重建每個(gè)目標(biāo),并恢復(fù)它們?cè)趫?chǎng)景中的準(zhǔn)確位置和遮擋關(guān)系。我們進(jìn)一步使用激光雷達(dá)先驗(yàn)進(jìn)行Gaussian splatting,以重建具有更大細(xì)節(jié)的場(chǎng)景并保持全景一致性。DrivingGaussian在驅(qū)動(dòng)場(chǎng)景重建方面優(yōu)于現(xiàn)有方法,能夠?qū)崿F(xiàn)高保真度和多攝像機(jī)一致性的真實(shí)感環(huán)視視圖合成。
開(kāi)源鏈接:https://pkuvdig.github.io/DrivingGaussian/
總結(jié)來(lái)說(shuō),DrivingGaussian的主要貢獻(xiàn)如下:
- 據(jù)我們所知,DrivingGaussian是第一個(gè)基于復(fù)合Gaussian splatting的大規(guī)模動(dòng)態(tài)駕駛場(chǎng)景的表示和建模框架。
- 引入了兩個(gè)新模塊,包括增量靜態(tài)三維高斯圖和復(fù)合動(dòng)態(tài)高斯圖。前者逐步重建靜態(tài)背景,而后者用高斯圖對(duì)多個(gè)動(dòng)態(tài)目標(biāo)進(jìn)行建模。在LiDAR先驗(yàn)的輔助下,該方法有助于在大規(guī)模駕駛場(chǎng)景中恢復(fù)完整的幾何圖形。
- 綜合實(shí)驗(yàn)表明,DrivingGaussian在挑戰(zhàn)自動(dòng)駕駛基準(zhǔn)方面優(yōu)于以前的方法,并能夠模擬各種下游任務(wù)的corner case。
聊一聊相關(guān)工作
NeRF用于邊界場(chǎng)景。用于新視圖合成的神經(jīng)渲染的快速進(jìn)展受到了極大的關(guān)注。神經(jīng)輻射場(chǎng)(NeRF)利用多層感知器(MLP)和可微分體素渲染,可以從一組2D圖像和相應(yīng)的相機(jī)姿態(tài)信息中重建3D場(chǎng)景并合成新的視圖。然而,NeRF僅限于有邊界的場(chǎng)景,需要中心目標(biāo)和攝影機(jī)之間保持一致的距離。它也很難處理用輕微重疊和向外捕捉方法捕捉的場(chǎng)景。許多進(jìn)步擴(kuò)展了NeRF的功能,導(dǎo)致訓(xùn)練速度、姿態(tài)優(yōu)化、場(chǎng)景編輯和動(dòng)態(tài)場(chǎng)景表示顯著提高。盡管如此,將NeRF應(yīng)用于大規(guī)模無(wú)邊界場(chǎng)景,如自動(dòng)駕駛情景,仍然是一個(gè)挑戰(zhàn)。
無(wú)邊界場(chǎng)景的NeRF。對(duì)于大規(guī)模無(wú)界場(chǎng)景,一些工作引入了NeRF的精細(xì)版本來(lái)對(duì)多尺度城市級(jí)靜態(tài)場(chǎng)景進(jìn)行建模。然而,這些方法在假設(shè)場(chǎng)景保持靜態(tài)的情況下對(duì)場(chǎng)景進(jìn)行建模,并在有效捕捉動(dòng)態(tài)元素方面面臨挑戰(zhàn)。
同時(shí),以前基于NeRF的方法高度依賴于精確的相機(jī)位姿。在沒(méi)有精確位姿的情況下,能夠從動(dòng)態(tài)單目視頻中進(jìn)行合成。然而,這些方法僅限于前向單目視點(diǎn),并且在處理來(lái)自周圍多相機(jī)設(shè)置的輸入時(shí)遇到了挑戰(zhàn)。
由上述基于NeRF的方法合成的視圖的質(zhì)量在具有多個(gè)動(dòng)態(tài)目標(biāo)和變化以及照明變化的場(chǎng)景中惡化,這是由于它們依賴于射線采樣。此外,激光雷達(dá)的利用僅限于提供輔助深度監(jiān)督,其在重建中的潛在好處,如提供幾何先驗(yàn),尚未得到探索。
為了解決這些限制,我們使用復(fù)合Gaussian splatting來(lái)對(duì)無(wú)界動(dòng)態(tài)場(chǎng)景進(jìn)行建模,其中靜態(tài)背景隨著自車輛的移動(dòng)而逐步重建,多個(gè)動(dòng)態(tài)目標(biāo)通過(guò)高斯圖建模并集成到整個(gè)場(chǎng)景中。激光雷達(dá)被用作高斯的初始化,提供了更準(zhǔn)確的幾何形狀先驗(yàn)和全面的場(chǎng)景描述,而不僅僅是作為圖像的深度監(jiān)督。
3D Gaussian Splatting。最近的3DGaussian splatting(3D-GS)用許多3D高斯對(duì)靜態(tài)場(chǎng)景進(jìn)行建模,在新的視圖合成和訓(xùn)練速度方面實(shí)現(xiàn)了最佳結(jié)果。與之前的顯式場(chǎng)景表示(例如,網(wǎng)格、體素)相比,3D-GS可以用更少的參數(shù)對(duì)復(fù)雜形狀進(jìn)行建模。與隱式神經(jīng)渲染不同,3D-GS允許使用基于splat的光柵化進(jìn)行快速渲染和可微分計(jì)算。
Dynamic 3D Gaussian Splatting。最初的3D-GS是用來(lái)表示靜態(tài)場(chǎng)景的,一些研究人員已經(jīng)將其擴(kuò)展到動(dòng)態(tài)目標(biāo)/場(chǎng)景。給定一組動(dòng)態(tài)單目圖像,
在真實(shí)世界的自動(dòng)駕駛場(chǎng)景中,數(shù)據(jù)采集平臺(tái)的高速移動(dòng)會(huì)導(dǎo)致廣泛而復(fù)雜的背景變化,通常由稀疏視圖(例如2-4個(gè)視圖)捕獲。此外,具有強(qiáng)烈空間變化和遮擋的快速移動(dòng)動(dòng)態(tài)目標(biāo)使情況進(jìn)一步復(fù)雜化。總的來(lái)說(shuō),這些因素對(duì)現(xiàn)有方法提出了重大挑戰(zhàn)。
詳解DrivingGaussian
Composite Gaussian Splatting
3D-GS在純靜態(tài)場(chǎng)景中表現(xiàn)良好,但在涉及大規(guī)模靜態(tài)背景和多個(gè)動(dòng)態(tài)目標(biāo)的混合場(chǎng)景中具有顯著的局限性。如圖2所示,我們的目標(biāo)是用無(wú)界靜態(tài)背景和動(dòng)態(tài)目標(biāo)的復(fù)合Gaussian splatting來(lái)表示周圍的大型駕駛場(chǎng)景。

增量靜態(tài)3D高斯。駕駛場(chǎng)景的靜態(tài)背景由于其大規(guī)模、長(zhǎng)持續(xù)時(shí)間以及隨著自車輛運(yùn)動(dòng)和多相機(jī)變換的變化而帶來(lái)的挑戰(zhàn)。隨著自我載體的移動(dòng),靜態(tài)背景經(jīng)常發(fā)生時(shí)間上的變化。由于透視原理,從遠(yuǎn)離光流的時(shí)間步長(zhǎng)預(yù)先融入遠(yuǎn)處的街道場(chǎng)景可能會(huì)導(dǎo)致尺度混亂,導(dǎo)致令人不快的偽影和模糊。為了解決這個(gè)問(wèn)題,我們通過(guò)引入增量靜態(tài)3D高斯來(lái)增強(qiáng)3D-GS,利用車輛運(yùn)動(dòng)帶來(lái)的視角變化和相鄰幀之間的時(shí)間關(guān)系,如圖3所示。

具體來(lái)說(shuō),我們首先基于LiDAR先驗(yàn)提供的深度范圍,將靜態(tài)場(chǎng)景均勻地劃分為N個(gè)bin。這些bin按時(shí)間順序排列,其中每個(gè)bin來(lái)自一個(gè)或多個(gè)時(shí)間步長(zhǎng)的多目圖像。對(duì)于第一個(gè)bin內(nèi)的場(chǎng)景,我們使用LiDAR先驗(yàn)初始化高斯模型(類似地適用于SfM點(diǎn)):
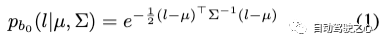
對(duì)于隨后的bin,我們使用來(lái)自前一個(gè)bin的高斯作為位置先驗(yàn),并根據(jù)相鄰bin的重疊區(qū)域?qū)R相鄰bin。每個(gè)bin的3D中心可以定義為:
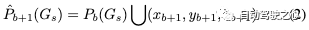
迭代地,我們將后續(xù)bin中的場(chǎng)景合并到先前構(gòu)建的高斯模型中,并將多個(gè)周圍幀作為監(jiān)督。增量靜態(tài)高斯模型Gs可以定義為:
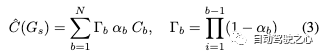
請(qǐng)注意,在靜態(tài)高斯模型的增量構(gòu)建過(guò)程中,前后相機(jī)對(duì)同一場(chǎng)景的采樣可能存在差異。為了解決這個(gè)問(wèn)題,我們?cè)?D高斯投影期間使用加權(quán)平均來(lái)盡可能準(zhǔn)確地重建場(chǎng)景的顏色:

復(fù)合動(dòng)態(tài)高斯圖。自動(dòng)駕駛環(huán)境高度復(fù)雜,涉及多個(gè)動(dòng)態(tài)目標(biāo)和時(shí)間變化。如圖3所示,由于自車輛和動(dòng)態(tài)目標(biāo)的運(yùn)動(dòng),通常從有限的視圖(例如2-4視圖)觀察目標(biāo)。高速還導(dǎo)致動(dòng)態(tài)目標(biāo)的顯著空間變化,這使得使用固定的高斯表示它們具有挑戰(zhàn)性。
為了應(yīng)對(duì)這些挑戰(zhàn),我們引入了復(fù)合動(dòng)態(tài)高斯圖,可以在大規(guī)模、長(zhǎng)期的駕駛場(chǎng)景中構(gòu)建多個(gè)動(dòng)態(tài)目標(biāo)。我們首先從靜態(tài)背景中分解動(dòng)態(tài)前景目標(biāo),使用數(shù)據(jù)集提供的邊界框來(lái)構(gòu)建動(dòng)態(tài)高斯圖。動(dòng)態(tài)目標(biāo)通過(guò)其目標(biāo)ID和相應(yīng)的出現(xiàn)時(shí)間戳來(lái)識(shí)別。此外,Segment Anything模型用于基于邊界框范圍的動(dòng)態(tài)目標(biāo)的精確像素提取。
然后,我們將動(dòng)態(tài)高斯圖構(gòu)建為:
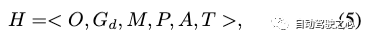
在這里,我們分別為每個(gè)動(dòng)態(tài)目標(biāo)計(jì)算高斯。使用變換矩陣mo,我們將目標(biāo)o的坐標(biāo)系變換為靜態(tài)背景所在的世界坐標(biāo):

在優(yōu)化了動(dòng)態(tài)高斯圖中的所有節(jié)點(diǎn)后,我們使用復(fù)合高斯圖將動(dòng)態(tài)目標(biāo)和靜態(tài)背景相結(jié)合。根據(jù)邊界框的位置和方向,按時(shí)間順序?qū)⒚總€(gè)節(jié)點(diǎn)的高斯分布連接到靜態(tài)高斯場(chǎng)中。在多個(gè)動(dòng)態(tài)目標(biāo)之間發(fā)生遮擋的情況下,我們根據(jù)與攝影機(jī)中心的距離調(diào)整不透明度:根據(jù)光傳播原理,距離越近的目標(biāo)不透明度越高:
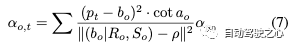
最后,包括靜態(tài)背景和多個(gè)動(dòng)態(tài)目標(biāo)的復(fù)合高斯場(chǎng)可以公式化為:

LiDAR Prior with surrounding views
基元3D-GS試圖通過(guò)structure-from-motion(SfM)來(lái)初始化高斯。然而,用于自動(dòng)駕駛的無(wú)邊界城市場(chǎng)景包含許多多尺度背景和前景。盡管如此,它們只是通過(guò)極其稀疏的視圖才能瞥見(jiàn),導(dǎo)致幾何結(jié)構(gòu)的錯(cuò)誤和不完整恢復(fù)。
為了為高斯提供更好的初始化,我們?cè)?D高斯之前引入了激光雷達(dá),以獲得更好的幾何形狀,并在環(huán)視視圖配準(zhǔn)中保持多相機(jī)的一致性。在每個(gè)時(shí)間步長(zhǎng),給定從移動(dòng)平臺(tái)和多幀激光雷達(dá)掃描Lt收集的一組多相機(jī)圖像。我們的目標(biāo)是使用激光雷達(dá)圖像多模態(tài)數(shù)據(jù)最小化多相機(jī)配準(zhǔn)誤差,并獲得準(zhǔn)確的點(diǎn)位置和幾何先驗(yàn)。
我們首先合并多幀激光雷達(dá)掃描,以獲得場(chǎng)景的完整點(diǎn)云,并從每個(gè)圖像中單獨(dú)提取圖像特征。接下來(lái),我們將激光雷達(dá)點(diǎn)投影到環(huán)視的圖像上。對(duì)于每個(gè)激光雷達(dá)點(diǎn),我們將其坐標(biāo)變換到相機(jī)坐標(biāo)系,并通過(guò)投影將其與相機(jī)圖像平面的2D像素匹配:

值得注意的是,來(lái)自激光雷達(dá)的點(diǎn)可能被投影到多個(gè)圖像的多個(gè)像素上。因此,我們選擇到圖像平面的歐幾里得距離最短的點(diǎn),并將其保留為投影點(diǎn),指定顏色。
與以往的三維重建工作類似,我們將密集束平差(DBA)擴(kuò)展到多相機(jī)設(shè)置,并獲得更新的激光雷達(dá)點(diǎn)。實(shí)驗(yàn)結(jié)果證明,在與周圍的多目對(duì)準(zhǔn)之前用激光雷達(dá)進(jìn)行初始化有助于為高斯模型提供更精確的幾何先驗(yàn)。
Global Rendering via Gaussian Splatting
本文采用可微3DGaussian splatting渲染器,并將全局復(fù)合3D高斯投影到2D中,其中協(xié)方差矩陣由下式給出:

復(fù)合高斯場(chǎng)將全局3D高斯投影到多個(gè)2D平面上,并在每個(gè)時(shí)間步長(zhǎng)使用環(huán)視視圖進(jìn)行監(jiān)督。在全局渲染過(guò)程中,下一個(gè)時(shí)間步長(zhǎng)的高斯最初對(duì)當(dāng)前圖像不可見(jiàn),隨后與相應(yīng)全局圖像的監(jiān)督相結(jié)合。
我們的方法的損失函數(shù)由三個(gè)部分組成。接下來(lái),我們首先將tile結(jié)構(gòu)相似性(TSSIM)引入Gaussian Splatting,它測(cè)量渲染的tile與對(duì)應(yīng)的GT之間的相似性。

我們還引入了用于減少3D高斯中異常值的魯棒損失,其可以定義為:

通過(guò)監(jiān)督激光雷達(dá)的預(yù)期高斯位置,進(jìn)一步利用激光雷達(dá)損失,獲得更好的幾何結(jié)構(gòu)和邊緣形狀:
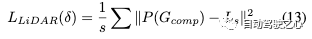
實(shí)驗(yàn)結(jié)果
如表1所示,我們的方法在很大程度上優(yōu)于Instant-NGP,后者使用基于哈希的NeRF進(jìn)行新的視圖合成。Mip-NeRF和MipNeRF360是針對(duì)無(wú)界戶外場(chǎng)景設(shè)計(jì)的兩種方法。我們的方法在所有評(píng)估指標(biāo)中也顯著超過(guò)了它們。

KITTI-360單視圖合成的比較。為了進(jìn)一步驗(yàn)證我們的方法在單目駕駛場(chǎng)景設(shè)置上的有效性,我們對(duì)KITTI-360數(shù)據(jù)集進(jìn)行了實(shí)驗(yàn),并將其與現(xiàn)有的SOTA方法進(jìn)行了比較。如表2所示,我們的方法在單目駕駛場(chǎng)景中表現(xiàn)出最佳性能,大大超過(guò)了現(xiàn)有方法。補(bǔ)充材料中提供了更多的結(jié)果和視頻。

消融實(shí)驗(yàn)
Gaussians的初始化先驗(yàn)。通過(guò)對(duì)比實(shí)驗(yàn)分析了不同先驗(yàn)和初始化方法對(duì)高斯模型的影響。原始3D-GS提供了兩種初始化模式:隨機(jī)生成點(diǎn)和COLMAP計(jì)算的SfM點(diǎn)。我們還提供了另外兩種初始化方法:從預(yù)先訓(xùn)練的NeRF模型導(dǎo)出的點(diǎn)云和使用LiDAR先驗(yàn)生成的點(diǎn)。
同時(shí),為了分析點(diǎn)云數(shù)量的影響,我們將激光雷達(dá)下采樣到600K,并應(yīng)用自適應(yīng)濾波(1M)來(lái)控制生成的激光雷達(dá)點(diǎn)的數(shù)量。我們還為隨機(jī)生成的點(diǎn)(600K和1M)設(shè)置了不同的最大閾值。這里,SfM-600K±20K表示COLMAP計(jì)算的點(diǎn)數(shù),NeRF-1M±20K代表預(yù)訓(xùn)練的NeRF模型生成的總點(diǎn)數(shù),LiDAR-2M±20K代表LiDAR點(diǎn)的原始數(shù)量。

如表3所示,隨機(jī)生成的點(diǎn)會(huì)導(dǎo)致最差的結(jié)果,因?yàn)樗鼈內(nèi)狈θ魏螏缀蜗闰?yàn)。由于點(diǎn)稀疏和無(wú)法容忍的結(jié)構(gòu)誤差,用SfM點(diǎn)初始化也不能充分恢復(fù)場(chǎng)景的精確幾何結(jié)構(gòu)。利用從預(yù)先訓(xùn)練的NeRF模型生成的點(diǎn)云提供了相對(duì)準(zhǔn)確的幾何先驗(yàn),但仍存在明顯的異常值。對(duì)于用LiDAR先驗(yàn)初始化的模型,盡管下采樣會(huì)導(dǎo)致一些局部區(qū)域的幾何信息丟失,但它仍然保留了相對(duì)準(zhǔn)確的結(jié)構(gòu)先驗(yàn),從而超過(guò)了SfM(圖5)。我們還可以觀察到,實(shí)驗(yàn)結(jié)果不會(huì)隨著激光雷達(dá)點(diǎn)數(shù)量的增加而線性變化。我們推斷這是因?yàn)檫^(guò)密的點(diǎn)存儲(chǔ)了冗余特征,干擾了高斯模型的優(yōu)化。

每個(gè)模塊的有效性。我們分析了每個(gè)提出的模塊對(duì)最終性能的貢獻(xiàn)。如表4所示,復(fù)合動(dòng)態(tài)高斯圖模塊在重建動(dòng)態(tài)駕駛場(chǎng)景中發(fā)揮著至關(guān)重要的作用,而增量靜態(tài)3D高斯圖模塊能夠?qū)崿F(xiàn)高質(zhì)量的大規(guī)模背景重建。這兩個(gè)新穎的模塊顯著提高了復(fù)雜駕駛場(chǎng)景的建模質(zhì)量。關(guān)于所提出的損失函數(shù),結(jié)果表明,和都顯著提高了渲染質(zhì)量,增強(qiáng)了紋理細(xì)節(jié)并消除了偽影。在LiDAR先驗(yàn)的幫助下,幫助高斯獲得更好的幾何先驗(yàn)。實(shí)驗(yàn)結(jié)果還表明,即使沒(méi)有激光雷達(dá)先驗(yàn),DrivingGaussian也能很好地執(zhí)行,對(duì)各種初始化方法表現(xiàn)出強(qiáng)大的魯棒性。

Corner Case仿真
進(jìn)一步展示了我們?cè)谡鎸?shí)駕駛場(chǎng)景中模擬Corner Case的方法的有效性。如圖6所示,我們可以將任意動(dòng)態(tài)對(duì)象插入重建的高斯場(chǎng)中。模擬場(chǎng)景主要具有時(shí)間一致性,并在多個(gè)傳感器之間表現(xiàn)出良好的傳感器間一致性。我們的方法能夠?qū)ψ詣?dòng)駕駛場(chǎng)景進(jìn)行可控的模擬和編輯,促進(jìn)安全自動(dòng)駕駛系統(tǒng)的研究。

總結(jié)
本文提出了DrivingGaussian,這是一種基于所提出的復(fù)合高斯Splatting的用于表示大規(guī)模動(dòng)態(tài)自動(dòng)駕駛場(chǎng)景的新框架。DrivingGaussian使用增量靜態(tài)3D高斯逐步對(duì)靜態(tài)背景進(jìn)行建模,并使用復(fù)合動(dòng)態(tài)高斯圖捕獲多個(gè)運(yùn)動(dòng)目標(biāo)。我們進(jìn)一步利用激光雷達(dá)先驗(yàn)來(lái)獲得精確的幾何結(jié)構(gòu)和多視圖一致性。DrivingGaussian在兩個(gè)著名的驅(qū)動(dòng)數(shù)據(jù)集上實(shí)現(xiàn)了最先進(jìn)的性能,允許高質(zhì)量的周圍視圖合成和動(dòng)態(tài)場(chǎng)景重建。

原文鏈接:https://mp.weixin.qq.com/s/pGwIbrgvmbScyNKNbZLE1w






























