













SurroundOcc:環(huán)視三維占據(jù)柵格新SOTA!
本文經(jīng)自動(dòng)駕駛之心公眾號(hào)授權(quán)轉(zhuǎn)載,轉(zhuǎn)載請(qǐng)聯(lián)系出處。
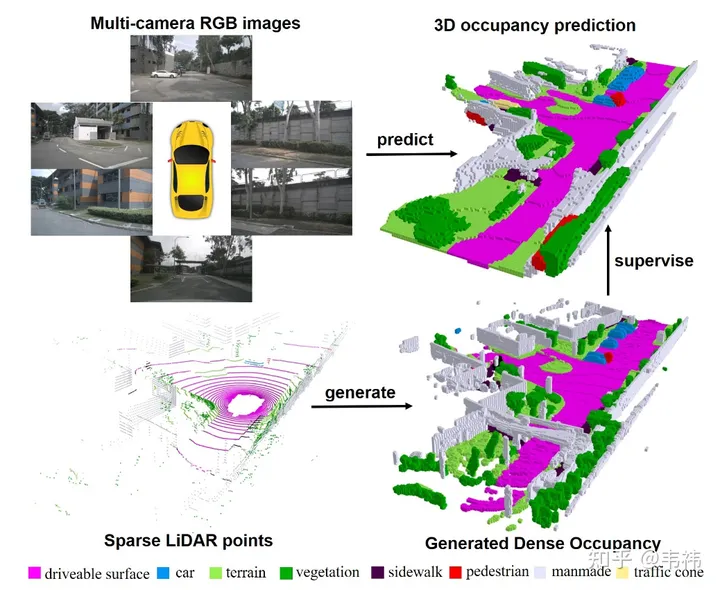
在這個(gè)工作中,我們通過多幀點(diǎn)云構(gòu)建了稠密占據(jù)柵格數(shù)據(jù)集,并設(shè)計(jì)了基于transformer的2D-3D Unet結(jié)構(gòu)的三維占據(jù)柵格網(wǎng)絡(luò)。很榮幸地,我們的文章被ICCV 2023收錄,目前項(xiàng)目代碼已開源,歡迎大家試用。

arXiv:https://arxiv.org/pdf/2303.09551.pdf
Code:https://github.com/weiyithu/SurroundOcc
主頁(yè):https://weiyithu.github.io/SurroundOcc/
最近一直在瘋狂找工作,沒有閑下來寫,正好最近提交了camera-ready,作為一個(gè)工作的收尾覺得還是寫個(gè)知乎總結(jié)下。其實(shí)文章部分的介紹各個(gè)公眾號(hào)寫的已經(jīng)很好了,也感謝他們的宣傳,大家可以直接參考自動(dòng)駕駛之心的自動(dòng)駕駛之心:nuScenes SOTA!SurroundOcc:面向自動(dòng)駕駛的純視覺3D占據(jù)預(yù)測(cè)網(wǎng)絡(luò)(清華&天大)。總的來說,contribution分為兩塊,一部分是如何利用多幀的lidar點(diǎn)云構(gòu)建稠密occupancy數(shù)據(jù)集,另一部分是如何設(shè)計(jì)occupancy預(yù)測(cè)的網(wǎng)絡(luò)。其實(shí)兩部分的內(nèi)容都比較直接易懂,大家有哪塊不理解的也可以隨時(shí)問我。那么這篇文章我想講點(diǎn)論文之外的事情,一個(gè)是如何改進(jìn)當(dāng)前方案使其更加易于部署,另一個(gè)是未來的發(fā)展方向。
部署
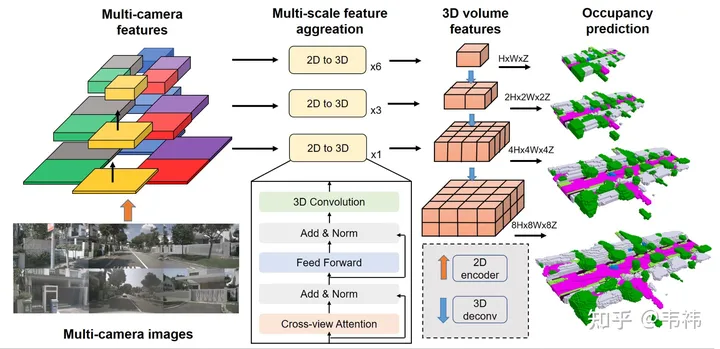
一個(gè)網(wǎng)絡(luò)是否易于部署,主要看其中有沒有比較難在板端實(shí)現(xiàn)的算子,SurroundOcc這個(gè)方法里比較難搞的兩個(gè)算子是transformer層以及3D卷積。
transformer的主要作用是將2D feature轉(zhuǎn)換到3D空間,那么其實(shí)這部分也可以用LSS,Homography甚至mlp來實(shí)現(xiàn),所以可以根據(jù)已實(shí)現(xiàn)的方案去修改這部分的網(wǎng)絡(luò)。但據(jù)我所知,transformer的方案在幾個(gè)方案里對(duì)calibration不敏感并且性能也比較好,建議有能力實(shí)現(xiàn)transformer部署的還是利用原有方案。
對(duì)于3D卷積來說,可以將其替換成2D卷積,這里需要將原來 (C, H, W, Z) 的3D feature reshape成(C* Z, H, W)的 2D feature,然后就可以用2D卷積進(jìn)行特征提取了,在最后occupancy預(yù)測(cè)那步再把它reshape回(C, H, W, Z),并進(jìn)行監(jiān)督。另一方面,skip connection由于分辨率比較大所以比較吃顯存,部署的時(shí)候可以去掉只留最小分辨率那一層。我們實(shí)驗(yàn)發(fā)現(xiàn)3D卷積中的這兩個(gè)操作在nuscenes上都會(huì)有些許掉點(diǎn),但業(yè)界數(shù)據(jù)集規(guī)模要遠(yuǎn)大于nuscenes,有時(shí)候有些結(jié)論也會(huì)改變,掉點(diǎn)應(yīng)該會(huì)少甚至不掉。
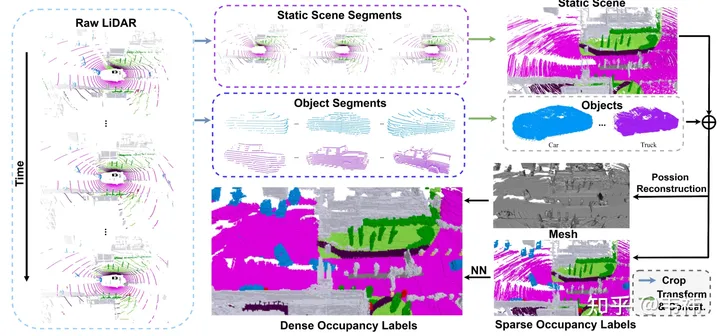
數(shù)據(jù)集構(gòu)建方面,最耗時(shí)的一步是泊松重建那步。由于我們用的是nuscenes數(shù)據(jù)集,是用32線lidar采集的,即使利用了多幀拼接技術(shù),我們發(fā)現(xiàn)拼接后的點(diǎn)云還是有很多的洞,所以我們利用泊松重建補(bǔ)洞。但其實(shí)現(xiàn)在業(yè)界用的許多l(xiāng)idar的點(diǎn)云都比較稠密,例如M1,RS128等,那么泊松重建這一步可以省略,將加速數(shù)據(jù)集構(gòu)建這一步。
另一方面,SurroundOcc里是利用nuscenes中標(biāo)注好的三維目標(biāo)檢測(cè)框?qū)㈧o態(tài)場(chǎng)景和動(dòng)態(tài)物體分離的。但實(shí)際應(yīng)用過程中,可以利用autolabel,也就是三維目標(biāo)檢測(cè)&跟蹤大模型去得到每個(gè)物體在整個(gè)sequence中的檢測(cè)框。相較于人工標(biāo)注的label,利用大模型跑出來的結(jié)果肯定會(huì)存在一些誤差,最直接的體現(xiàn)就是多幀的物體拼接后會(huì)有重影的現(xiàn)象。但其實(shí)occupancy對(duì)于物體形狀的要求沒有那么高,只要檢測(cè)框位置比較準(zhǔn)就能滿足需求。
未來方向
當(dāng)前方法還是比較依賴lidar提供occupancy的監(jiān)督信號(hào)的,但很多車上,尤其是一些低階輔助駕駛的車上沒有l(wèi)idar,這些車通過shadow模式可以傳回來大量的RGB數(shù)據(jù),那么一個(gè)未來方向是能不能只利用RGB進(jìn)行自監(jiān)督學(xué)習(xí)。一個(gè)自然的解決思路就是利用NeRF進(jìn)行監(jiān)督,具體來說,前面backbone部分不變,得到一個(gè)occupancy的預(yù)測(cè),然后利用體素渲染得到每個(gè)相機(jī)視角下的RGB,和訓(xùn)練集中的真值RGB做loss形成監(jiān)督信號(hào)。但很可惜的是這一套straightforward的方法我們?cè)嚵嗽嚥⒉皇呛躻ork,可能的原因是室外場(chǎng)景range太大,nerf可能hold不住,但也可能我們沒有調(diào)好,大家也可以再試試。
另一個(gè)方向是時(shí)序&occupancy flow。其實(shí)occupancy flow對(duì)于下游任務(wù)的用處遠(yuǎn)比單幀occupancy大。ICCV的時(shí)候沒來得及整occupancy flow的數(shù)據(jù)集,而且發(fā)paper的話還要對(duì)比很多flow的baseline,所以當(dāng)時(shí)就沒搞這塊。時(shí)序網(wǎng)絡(luò)可以參考BEVFormer和BEVDet4D的方案,比較簡(jiǎn)單有效。難的地方還是flow數(shù)據(jù)集這一部分,一般的物體可以用sequence的三維目標(biāo)檢測(cè)框算出來,但異型物體例如小動(dòng)物塑料袋等,可能需要借助場(chǎng)景流的方法進(jìn)行標(biāo)注。

原文鏈接:https://mp.weixin.qq.com/s/_crun60B_lOz6_maR0Wyug





















