深度估計SOTA!自動駕駛單目與環視深度的自適應融合
本文經自動駕駛之心公眾號授權轉載,轉載請聯系出處。
寫在前面&個人理解
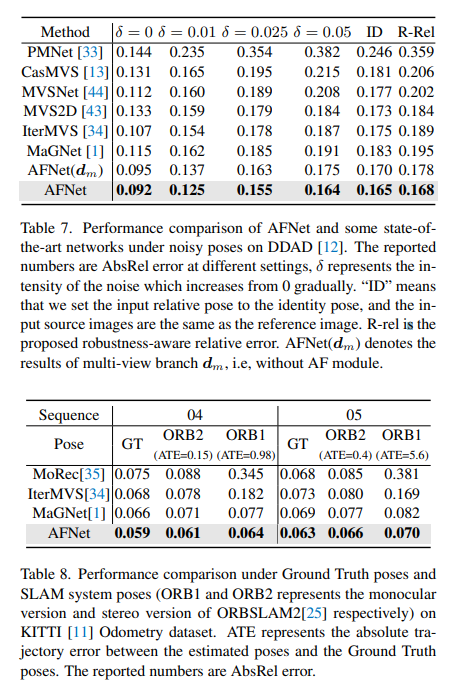
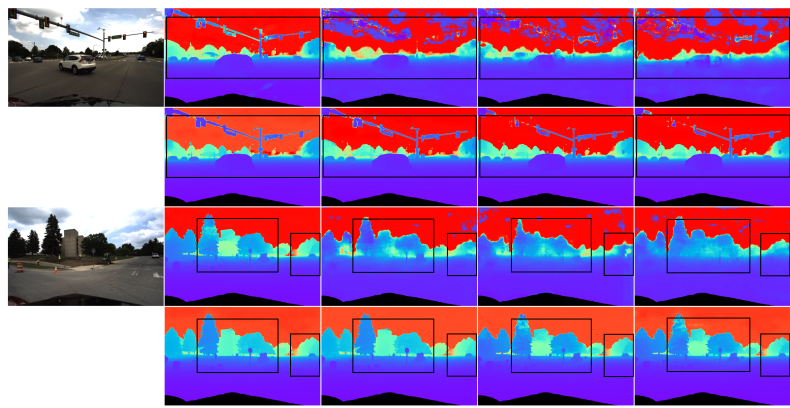
多視圖深度估計在各種基準測試中都取得了較高性能。然而,目前幾乎所有的多視圖系統都依賴于給定的理想相機姿態,而這在許多現實世界的場景中是不可用的,例如自動駕駛。本工作提出了一種新的魯棒性基準來評估各種噪聲姿態設置下的深度估計系統。令人驚訝的是,發現當前的多視圖深度估計方法或單視圖和多視圖融合方法在給定有噪聲的姿態設置時會失敗。為了應對這一挑戰,這里提出了一種單視圖和多視圖融合的深度估計系統AFNet,該系統自適應地集成了高置信度的多視圖和單視圖結果,以實現穩健和準確的深度估計。自適應融合模塊通過基于包裹置信度圖在兩個分支之間動態選擇高置信度區域來執行融合。因此,當面對無紋理場景、不準確的校準、動態對象和其他退化或具有挑戰性的條件時,系統傾向于選擇更可靠的分支。在穩健性測試下,方法優于最先進的多視圖和融合方法。此外,在具有挑戰性的基準測試中實現了最先進的性能 (KITTI和DDAD)。
論文鏈接:https://arxiv.org/pdf/2403.07535.pdf
論文名稱:Adaptive Fusion of Single-View and Multi-View Depth for Autonomous Driving
領域背景
從圖像中進行深度估計是計算機視覺中一個長期存在的問題,具有廣泛的應用。對于基于視覺的自動駕駛系統來說,感知深度是理解道路物體相關性和建模3D環境地圖不可或缺的模塊。由于深度神經網絡被應用于解決各種視覺問題,因此基于CNN的方法已經主導了各種深度基準!
根據輸入格式,主要分為多視角深度估計和單視角深度估計。多視圖方法估計深度的假設是,給定正確的深度、相機標定和相機姿態,各個視圖的像素應該相似。他們依靠極線幾何來三角測量高質量的深度。然而,多視圖方法的準確性和魯棒性在很大程度上取決于相機的幾何配置和視圖之間的對應匹配。首先,攝像機需要進行足夠的平移以進行三角測量。在自動駕駛場景中,自車可能會在紅綠燈處停車或在不向前移動的情況下轉彎,這會導致三角測量失敗。此外,多視圖方法存在動態目標和無紋理區域的問題,這些問題在自動駕駛場景中普遍存在。另一個問題是運動車輛上的SLAM姿態優化。在現有的SLAM方法中,噪聲是不可避免的,更不用說具有挑戰性和不可避免的情況了。例如,一個機器人或自動駕駛汽車可以在不重新校準的情況下部署數年,從而導致姿勢嘈雜。相比之下,由于單視圖方法依賴于對場景的語義理解和透視投影線索,因此它們對無紋理區域、動態對象更具魯棒性,而不依賴于相機姿勢。然而,由于尺度的模糊性,其性能與多視圖方法相比仍有很大差距。在這里,我們傾向于考慮是否可以很好地結合這兩種方法的優勢,在自動駕駛場景中進行穩健和準確的單目視頻深度估計。
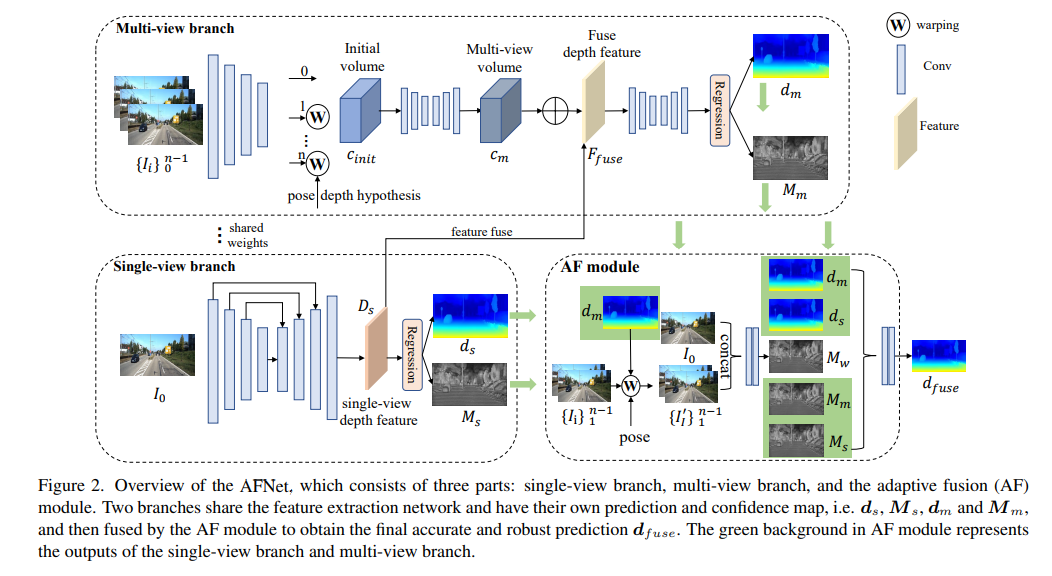
AFNet網絡結構
AFNet結構如下所示,它由三個部分組成:單視圖分支、多視圖分支和自適應融合(AF)模塊。兩個分支共享特征提取網絡,并具有自己的預測和置信度圖,即、,和,然后由AF模塊進行融合,以獲得最終準確和穩健的預測,AF模塊中的綠色背景表示單視圖分支和多視圖分支的輸出。
損失函數:
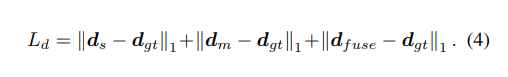
單視圖和多視圖深度模塊
AFNet構造了一個多尺度解碼器來合并主干特征,并獲得深度特征Ds。通過對Ds的前256個通道沿通道維度應用softmax,得到深度概率體積Ps。該特征的最后一個通道用作單視圖深度的置信圖Ms。最后,通過軟加權和來計算單視圖深度,如下所示:
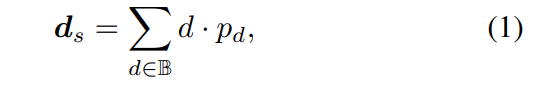
多視圖分支
多視圖分支與單視圖分支共享主干,以提取參考圖像和源圖像的特征。我們采用去卷積將低分辨率特征去卷積為四分之一分辨率,并將它們與用于構建cost volume的初始四分之一特征相結合。通過將源特征wrap到參考相機跟隨的假設平面中,形成特征volume。用于不需要太多的魯棒匹配信息,在計算中保留了特征的通道維度并構建了4D cost volume,然后通過兩個3D卷積層將通道數量減少到1。
深度假設的采樣方法與單視圖分支一致,但采樣數量僅為128,然后使用堆疊的2D沙漏網絡進行正則化,以獲得最終的多視圖cost volume。為了補充單視圖特征的豐富語義信息和由于成本正則化而丟失的細節,使用殘差結構來組合單視圖深度特征Ds和cost volume,以獲得融合深度特征,如下所示:
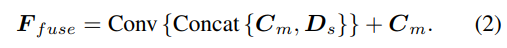
自適應融合模塊
為了獲得最終準確和穩健的預測,設計了AF模塊,以自適應地選擇兩個分支之間最準確的深度作為最終輸出,如圖2所示。通過三個confidence進行融合映射,其中兩個是由兩個分支分別生成的置信圖Ms和Mm,最關鍵的一個是通過前向wrapping生成的置信度圖Mw,以判斷多視圖分支的預測是否可靠。
實驗結果
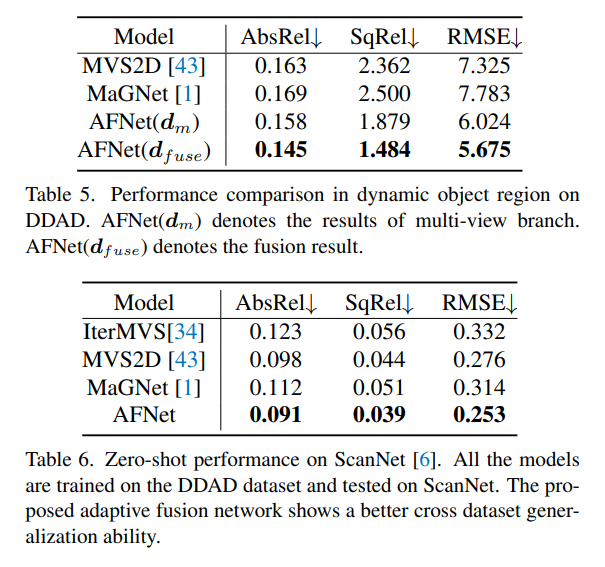
DDAD(自動駕駛的密集深度)是一種新的自動駕駛基準,用于在具有挑戰性和多樣化的城市條件下進行密集深度估計。它由6臺同步相機拍攝,并包含高密度激光雷達生成的準確的地GT深度(整個360度視場)。它在單個相機視圖中有12650個訓練樣本和3950個驗證樣本,其中分辨率為1936×1216。來自6臺攝像機的全部數據用于訓練和測試。KITTI數據集,提供運動車輛上拍攝的戶外場景的立體圖像和相應的3D激光scan,分辨率約為1241×376。
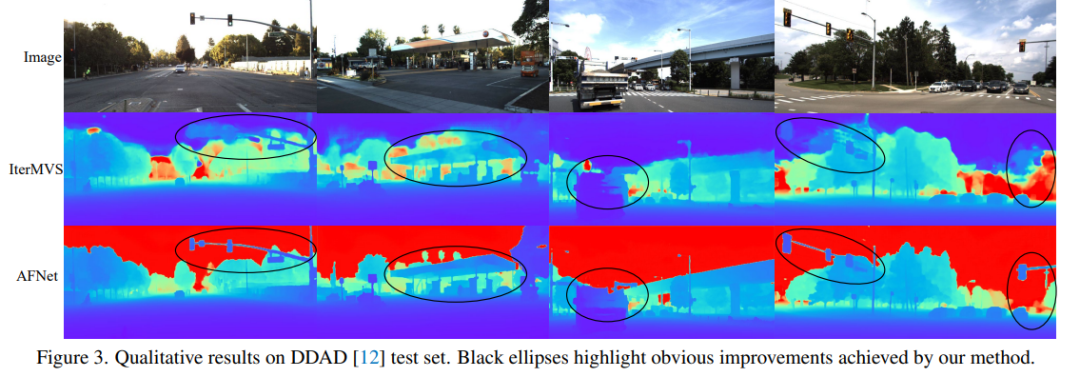
DDAD和KITTI上的評測結果對比。請注意,* 標記了使用其開源代碼復制的結果,其他報告的數字來自相應的原始論文。

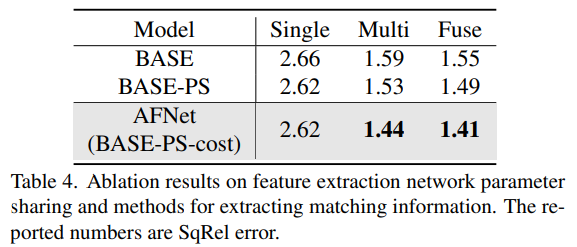
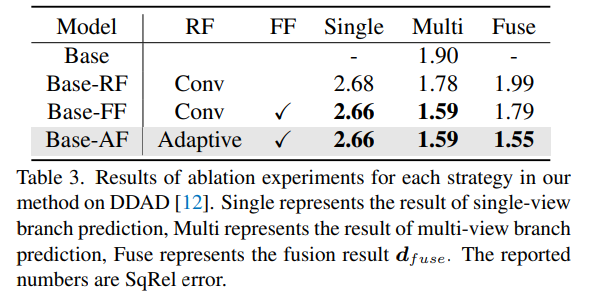
DDAD上方法中每種策略的消融實驗結果。Single表示單視圖分支預測的結果,Multi-表示多視圖分支預測結果,Fuse表示融合結果dfuse。
消融結果的特征提取網絡參數共享和提取匹配信息的方法。