Anything in Any Scene:逼真物體插入(助力各類駕駛數據合成)
原標題:Anything in Any Scene: Photorealistic Video Object Insertion
論文鏈接:https://arxiv.org/pdf/2401.17509.pdf
代碼鏈接:https://github.com/AnythingInAnyScene/anything_in_anyscene
作者單位:小鵬汽車

論文思路
逼真的(realistic)視頻仿真(video simulation)在從虛擬現實到電影制作等各種應用領域都顯示出巨大的潛力。尤其是在現實世界中捕捉視頻不切實際或成本高昂的情況下。視頻仿真中的現有方法通常無法準確地建模光照環境、表示物體幾何形狀或實現高水平的照片級真實感。本文提出了 Anything in Any Scene ,這是一種新穎且通用的真實視頻仿真框架,可以將任何物體無縫插入到現有的動態視頻中,并強調物理真實感。本文提出的總體框架包含三個關鍵過程:1)將真實的物體集成到給定的場景視頻中,并放置適當的位置以確保幾何真實感(geometric realism);2)估計天空和環境光照分布并模擬真實陰影,增強光照真實感(light realism);3)采用風格遷移網絡來細化最終的視頻輸出,以最大限度地提高照片真實感(photorealism)。本文通過實驗證明 Anything in Any Scene 框架可以生成具有出色的幾何真實感、光照真實感和照片真實感的仿真視頻。通過顯著緩解與視頻數據生成相關的挑戰,本文的框架為獲取高質量視頻提供了高效且經濟高效的解決方案。此外,其應用遠遠超出了視頻數據增強的范圍,在虛擬現實、視頻編輯和各種其他以視頻為中心的應用中顯示出廣闊的潛力。
主要貢獻
本文引入了一種新穎且可擴展的 Anything in Any Scene 視頻仿真框架,能夠將任何物體集成到任何動態場景視頻中。
本文的框架獨特地專注于在視頻仿真中保留幾何真實感、光照真實感和照片真實感,確保高質量和真實的輸出。
本文進行了廣泛的驗證,證明該框架有能力制作逼真的視頻仿真,極大地擴展了該領域的應用范圍和潛力。
論文設計
圖像和視頻仿真在從虛擬現實到電影制作的各種應用中都取得了成功。通過逼真的圖像和視頻仿真生成多樣化和高質量的視覺內容的能力具有推動這些領域發展的潛力,能夠引入新的可能性和應用。盡管在現實世界中捕獲的圖像和視頻的真實性非常寶貴,但它們經常受到長尾分布的限制。這導致常見場景的代表性過高,而罕見但關鍵的情況的代表性不足,從而提出了稱為 out-of-distribution problem 的挑戰。通過視頻采集和編輯來解決這些限制的傳統方法被證明是不切實際的或成本過高,因為難以涵蓋所有可能的情況。視頻仿真的重要性,特別是通過將現有視頻與新插入的物體相集成,對于克服這些挑戰變得至關重要。通過生成大規模、多樣化和逼真的視覺內容,視頻仿真有助于增強虛擬現實、視頻編輯和視頻數據增強方面的應用。
然而,考慮物理真實性生成逼真的仿真視頻仍然是一個具有挑戰性的開放問題。現有方法通常因專注于特定設置而表現出局限性,特別是室內環境[9,26,45,46,57]。這些方法可能無法充分解決室外場景的復雜性,包括不同的光照條件和快速移動的物體。依賴 3D 模型配準的方法僅限于集成有限類別的物體 [12,32,40,42]。許多方法忽略了一些重要因素,例如光照環境建模、正確的物體放置和實現真實感 [12, 36]。失敗的案例如圖 1 所示。因此,這些限制極大地限制了它們在需要高度可擴展、幾何一致和真實場景視頻仿真的領域(例如自動駕駛和機器人)中的應用。
本文提出了一個用于解決這些挑戰的逼真視頻物體插入的綜合框架 Anything in Any Scene。該框架設計具有通用性,適用于室內和室外場景,保證幾何真實感、光照真實感和照片真實感等方面的物理準確性。本文的目標是創建視頻仿真,不僅有利于機器學習中的視覺數據增強,而且適用于各種視頻應用,例如虛擬現實和視頻編輯。
本文的 Anything in Any Scene 框架的概述如圖 2 所示。本文在第 3 節中詳細介紹了本文新穎且可擴展的流程,用于構建場景視頻和物體網格(object mesh)的多樣化資產庫。本文介紹了一種視覺數據查詢引擎,旨在利用描述性關鍵詞從視覺查詢中高效檢索相關視頻片段。接下來,本文提出兩種生成 3D meshes 的方法,利用現有 3D 資產以及多視圖圖像重建。這允許不受限制地插入任何所需的物體,即使它非常不規則或語義較弱。在第 4 節中,本文詳細介紹了將物體集成到動態場景視頻中的方法,重點是保持物理真實感。本文設計了第 4.1 節中描述的物體放置和穩定方法,確保插入的物體穩定地錨定(anchored)在連續的視頻幀上。為了解決創建逼真的光照和陰影效果的挑戰,本文估計天空和環境光照并在渲染過程中生成逼真的陰影,如第 4.2 節所述。生成的仿真視頻幀不可避免地包含與現實世界捕獲的視頻不同的不現實的偽影,例如噪聲水平、色彩保真度和清晰度方面的成像質量差異。本文在 4.3 節中采用風格遷移網絡來增強照片真實感。
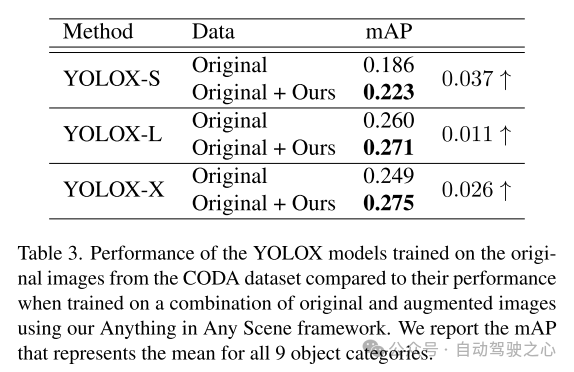
從本文提出的框架生成的仿真視頻達到了高度的光照真實感、幾何真實感和照片真實感,在質量和數量上都優于其他視頻,如第 5.3 節所示。本文在5.4節中進一步展示了本文的仿真視頻在訓練感知算法中的應用,以驗證其實用價值。Anything in Any Scene 框架能夠創建大規模、低成本的視頻數據集,用于具有時間效率和逼真視覺質量的數據增強,從而減輕視頻數據生成的負擔,并有可能改善長尾分布和分布外的挑戰。憑借其通用的框架設計,Anything in Any Scene 框架可以輕松整合改進的模型和新模塊,例如改進的 3D mesh 重建方法,進一步增強視頻仿真性能。
 圖 1. 光照環境估計錯誤、物體擺放位置錯誤和紋理風格不真實的仿真視頻幀示例,這些問題使得圖像缺乏物理真實感。
圖 1. 光照環境估計錯誤、物體擺放位置錯誤和紋理風格不真實的仿真視頻幀示例,這些問題使得圖像缺乏物理真實感。 圖 2. 用于逼真視頻物體插入的 Anything in Any Scene 框架概述
圖 2. 用于逼真視頻物體插入的 Anything in Any Scene 框架概述 圖 3. 用于放置物體的駕駛場景視頻示例。每幅圖像中的紅點是物體插入的位置。
圖 3. 用于放置物體的駕駛場景視頻示例。每幅圖像中的紅點是物體插入的位置。
實驗結果

圖 4. 原始天空圖像、重建的 HDR 圖像及其相關的太陽光照分布圖的示例

圖 5. 原始和重建的 HDR 的環境全景圖像示例

圖 6. 為插入的物體生成陰影的示例

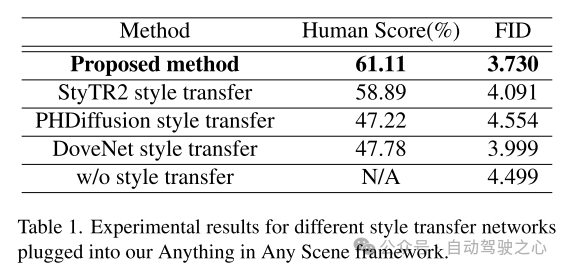
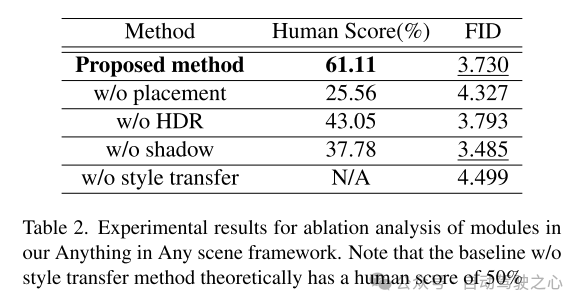
圖 7. 使用不同風格遷移網絡對 PandaSet 數據集的仿真視頻幀進行定性比較。

圖 8. PandaSet 數據集的仿真視頻幀在各種渲染條件下的定性比較。
總結:
本文提出了一個創新且可擴展的框架,”Anything in Any Scene",專為逼真的視頻仿真而設計。本文提出的框架將各種物體無縫集成到不同的動態視頻中,確保保留幾何真實感、光照真實感和照片真實感。通過廣泛的演示,本文展示了其在緩解視頻數據收集和生成相關挑戰方面的功效,提供了適用于各種場景的經濟高效且省時的解決方案。本文的框架的應用在下游感知任務中顯示出顯著的改進,特別是在解決目標檢測中的長尾分布問題方面。本文框架的靈活性允許直接集成每個模塊的改進模型,本文的框架為逼真視頻仿真領域的未來探索和創新奠定了堅實的基礎。
引用:
Bai C, Shao Z, Zhang G, et al. Anything in Any Scene: Photorealistic Video Object Insertion[J]. arXiv preprint arXiv:2401.17509, 2024.