無需訓練,自動擴展的視覺Transformer來了
當前 Vision Transformers (ViT)領域有兩個主要的痛點:1、缺少對 ViT 進行設計和擴展的有效方法;2、訓練 ViT 的計算成本比卷積網絡要大得多。
為了解決這兩個問題,來自得克薩斯大學奧斯汀分校、悉尼科技大學和谷歌的研究者提出了 As-ViT(Auto-scaling Vision Transformers),這是一個無需訓練的 ViT 自動擴展框架,它能以高效且有原則的方式自動設計和擴展 ViT。

論文鏈接:https://arxiv.org/abs/2202.11921
具體來說,研究人員首先利用無訓練搜索過程設計了 ViT 拓撲的「種子」,這種極快的搜索是通過對 ViT 網絡復雜性的全面研究來實現的,從而產生了與真實準確度的強 Kendall-tau 相關性。其次,從「種子」拓撲開始,通過將寬度 / 深度增加到不同的 ViT 層來自動化 ViT 的擴展規則,實現了在一次運行中具有不同數量參數的一系列架構。最后,基于 ViT 在早期訓練階段可以容忍粗粒度 tokenization 的經驗,該研究提出了一種漸進式 tokenization 策略來更快、更節約地訓練 ViT。
作為統一的框架,As-ViT 在分類(ImageNet-1k 上 83.5% 的 top1)和檢測(COCO 上 52.7% 的 mAP)任務上實現了強大的性能,無需任何手動調整或擴展 ViT 架構,端到端模型設計和擴展過程在一塊 V100 GPU 上只需 12 小時。
具有網絡復雜度的 ViT 自動設計和擴展
為加快 ViT 設計并避免繁瑣的手動工作,該研究希望以高效、自動化和有原則的 ViT 搜索和擴展為目標。具體來說有兩個問題需要解決:1)在訓練成本最小甚至為零的情況下,如何高效地找到最優的 ViT 架構拓撲?2)如何擴大 ViT 拓撲的深度和寬度以滿足模型尺寸的不同需求?
擴展 ViT 的拓撲空間
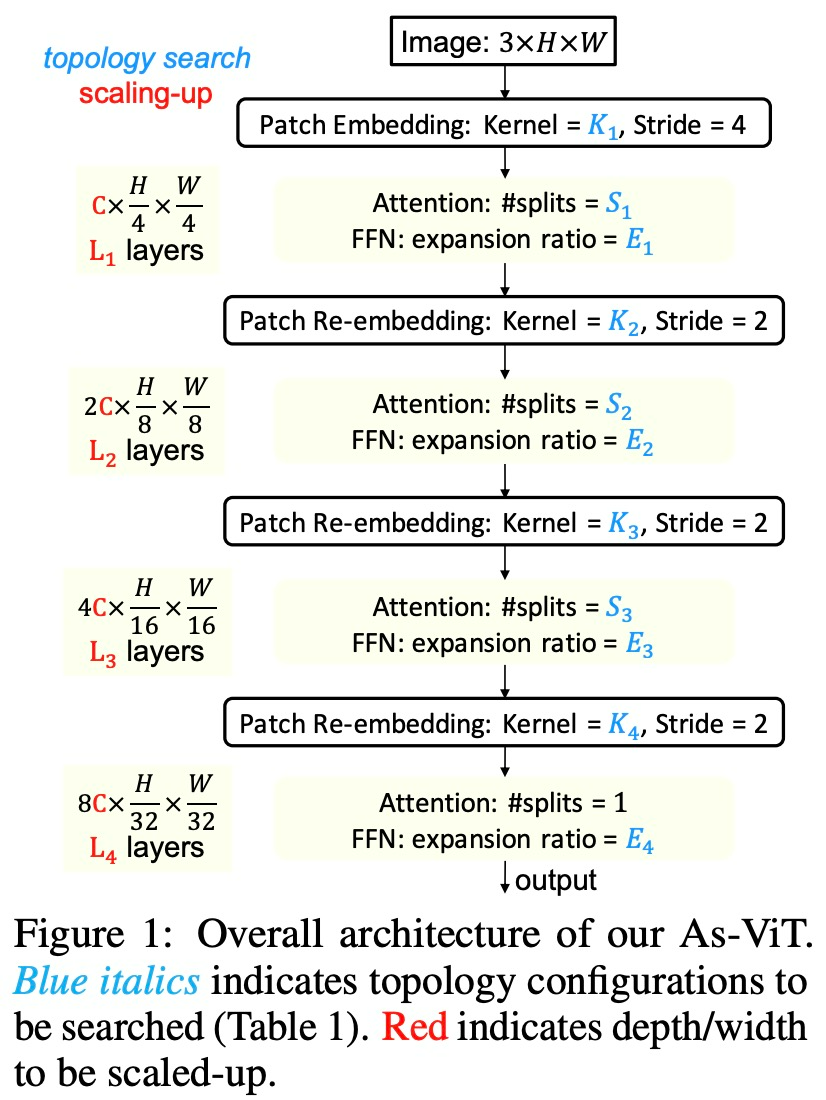
在設計和擴展之前,首先是為 As-ViT 擴展的拓撲搜索空間:首先將輸入圖像嵌入到 1/4 尺度分辨率的塊中,并采用逐級空間縮減和通道加倍策略。這是為了方便密集預測任務,例如需要多尺度特征的檢測。
通過流形傳播評估初始化時的 ViT 復雜性
ViT 訓練速度很慢,因此,通過評估訓練模型的準確率來進行架構搜索的成本將高得讓人難以承受。最近學界出現很多用基于 ReLU 的 CNN 的免訓練神經架構搜索方法,利用局部線性圖 (Mellor et al., 2020)、梯度敏感性 (Abdelfattah et al., 2021)、線性區域數量 (Chen et al., 2021e;f) 或網絡拓撲(Bhardwaj et al., 2021)等方式。
然而 ViT 配備了更復雜的非線性函數如 self-attention、softmax 和 GeLU。因此需要以更一般的方式衡量其學習能力。在新研究中,研究者考慮通過 ViT 測量流形傳播的復雜性,以估計復雜函數可以如何被 ViT 逼近。直觀地說,一個復雜的網絡可以在其輸出層將一個簡單的輸入傳播到一個復雜的流形中,因此可能具有很強的學習能力。在 UT Austin 的工作中,他們通過 ViT 映射簡單圓輸入的多種復雜性:h(θ) = √ N [u^0 cos(θ) + u^1 sin(θ)]。這里,N 是 ViT 輸入的維度(例如,對于 ImageNet 圖像,N = 3 × 224 × 224),u^0 和 u^1 形成了圓所在的 R^N 的二維子空間的標準正交基。
搜索 ViT 拓撲獎勵
研究者提出了基于 L^E 的免訓練搜索(算法 1),大多數 NAS(神經架構搜索)方法將單路徑或超級網絡的準確率或損失值評估為代理推理。當應用于 ViT 時,這種基于訓練的搜索將需要更多的計算成本。對于采樣的每個架構,這里不是訓練 ViT,而是計算 L^E 并將其視為指導搜索過程的獎勵。
除了 L^E,還包括 NTK 條件數 κΘ = λ_max/λ_min ,以指示 ViT 的可訓練性(Chen et al., 2021e; Xiao et al., 2019; Yang, 2020; Hron et al., 2020)。λ_max 和 λ_min 是 NTK 矩陣 Θ 的最大和最小特征值。

搜索使用強化學習方法,策略被定為聯合分類分布,并通過策略梯度進行更新,該研究將策略更新為 500 step,觀察到足以使策略收斂(熵從 15.3 下降到 5.7)。搜索過程非常快:在 ImageNet-1k 數據集上只有七個 GPU 小時 (V100),這要歸功于繞過 ViT 訓練的 L^E 的簡單計算。為了解決 L^E 和 κΘ 的不同大小,該研究通過它們的相對值范圍對它們進行歸一化(算法 1 中的第 5 行)。
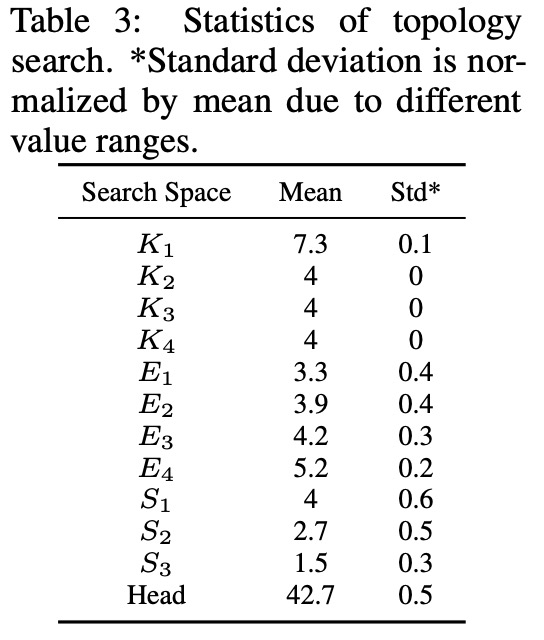
表 3 總結了新搜索方法的 ViT 拓撲統計數據。我們可以看到 L^E 和 κΘ 高度偏好:(1)具有重疊的 token (K_1~K_4 都大于 stride ),以及(2)在更深層中更大的 FFN 擴展率(E_1 < E_2 < E_3 < E_4)。在注意力分裂和正面數量上沒有發現 L^E 和 κΘ 的明顯偏好。
ViT 自主的原則型擴展
得到最優拓撲后,接下來要解決的一個問題是:如何平衡網絡的深度和寬度?
目前,對于 ViT 擴展沒有這樣的經驗法則。最近的工作試圖擴大或增長不同大小的卷積網絡以滿足各種資源限制(Liu et al., 2019a; Tan & Le, 2019)。然而,為了自動找到一個有原則的擴展規則,訓練 ViT 將花費巨大的計算成本。也可以搜索不同的 ViT 變體(如第 3.3 節中所述),但這需要多次運行。相反,「向上擴展,scaling-up」是在一個實驗中生成多個模型變體的更自然的方式。因此,該研究試圖以一種免訓練且有原則的有效方法將搜索到的基本「種子」ViT 擴展到更大的模型。算法 2 中描述了這種自動擴展方法:

初始架構的每個階段都有一個注意力塊,初始隱藏維度 C = 32。每次迭代找出最佳深度和寬度,以進行進一步向上擴展。對于深度,該研究嘗試找出要加深哪個階段(即,在哪個階段添加一個注意力塊);對于寬度,該研究嘗試發現最佳擴展比(即,將通道數擴大到什么程度)。

擴展軌跡如下圖 3 所示。比較自主擴展和隨機擴展,研究者發現擴展原則更喜歡舍棄深度來換取更多寬度,使用更淺但更寬的網絡。這種擴展更類似于 Zhai et al. (2021) 開發的規則。相比之下,ResNet 和 Swin Transformer (Liu et al., 2021) 選擇更窄更深。

通過漸進靈活的 re-tokenization 進行高效的 ViT 訓練
該研究通過提出漸進靈活的 re-tokenization 訓練策略來提供肯定的答案。為了在訓練期間更新 token 的數量而不影響線性投影中權重的形狀,該研究在第一個線性投影層中采用不同的采樣粒度。以第一個投影核 K_1 = 4 且 stride = 4 為例:訓練時研究者逐漸將第一個投影核的 (stride, dilation) 對逐漸變為 (16, 5), (8, 2) 和 (4 , 1),保持權重的形狀和架構不變。
這種 re-tokenization 的策略激發了 ViT 的課程學習(curriculum learning):訓練開始時引入粗采樣以顯著減少 token 的數量。換句話說,As-ViT 在早期訓練階段以極低的計算成本(僅全分辨率訓練的 13.2% FLOPs)快速從圖像中學習粗略信息。在訓練的后期階段,該研究逐漸切換到細粒度采樣,恢復完整的 token 分辨率,并保持有競爭力的準確率。如圖 4 所示,當在早期訓練階段使用粗采樣訓練 ViT 時,它仍然可以獲得很高的準確率,同時需要極低的計算成本。不同采樣粒度之間的轉換引入了性能的跳躍,最終網絡恢復了具有競爭力的最終性能。
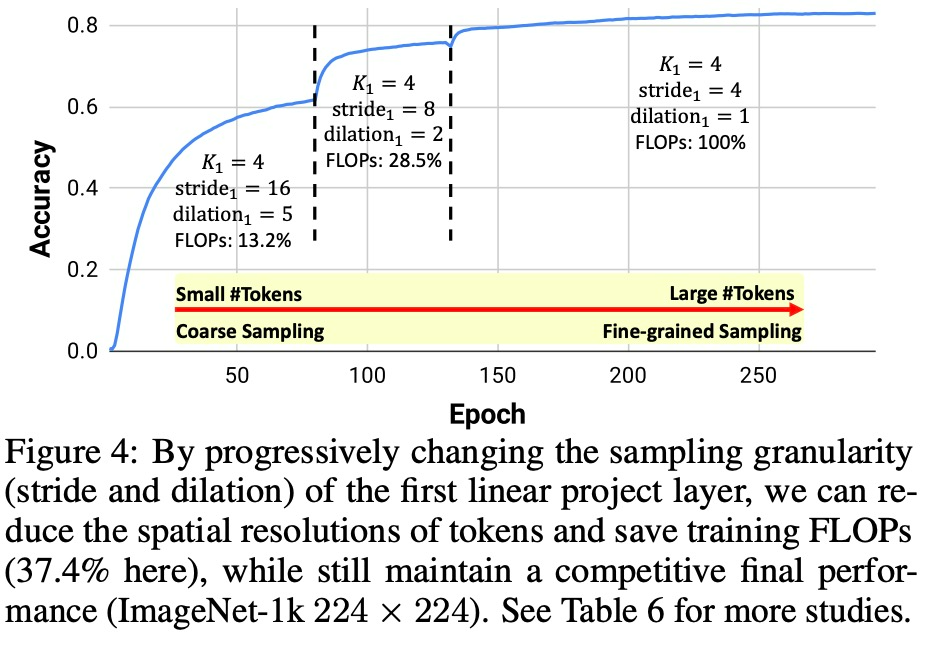
如圖 4 所示,當 ViT 在早期訓練階段使用粗采樣訓練 ViT 時,它仍然可以獲得很高的準確率,同時需要極低的計算成本。不同采樣粒度之間的轉換引入了性能的跳躍,最終網絡恢復了具有競爭力的最終性能。
實驗
AS-VIT:自動擴展 VIT
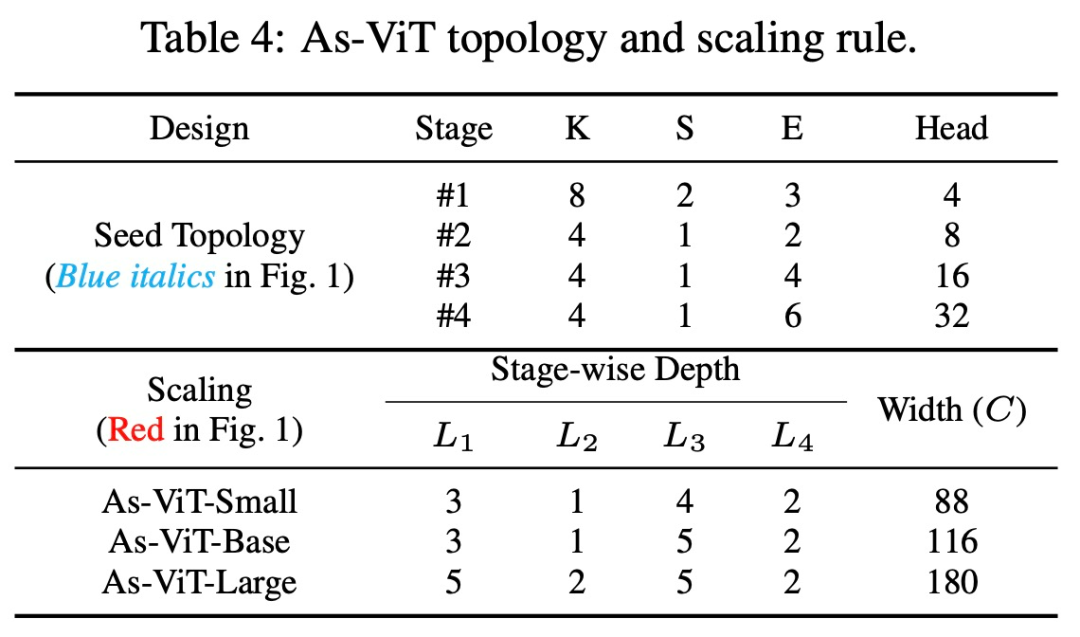
該研究在表 4 中展示了搜索到的 As-ViT 拓撲。這種架構在第一個投影(tokenization)step 和三個重新嵌入 step 中,促進了 token 之間的強烈重疊。FFN 擴展比首先變窄,然后在更深的層變寬。利用少量注意力拆分來更好地聚合全局信息。
圖像分類
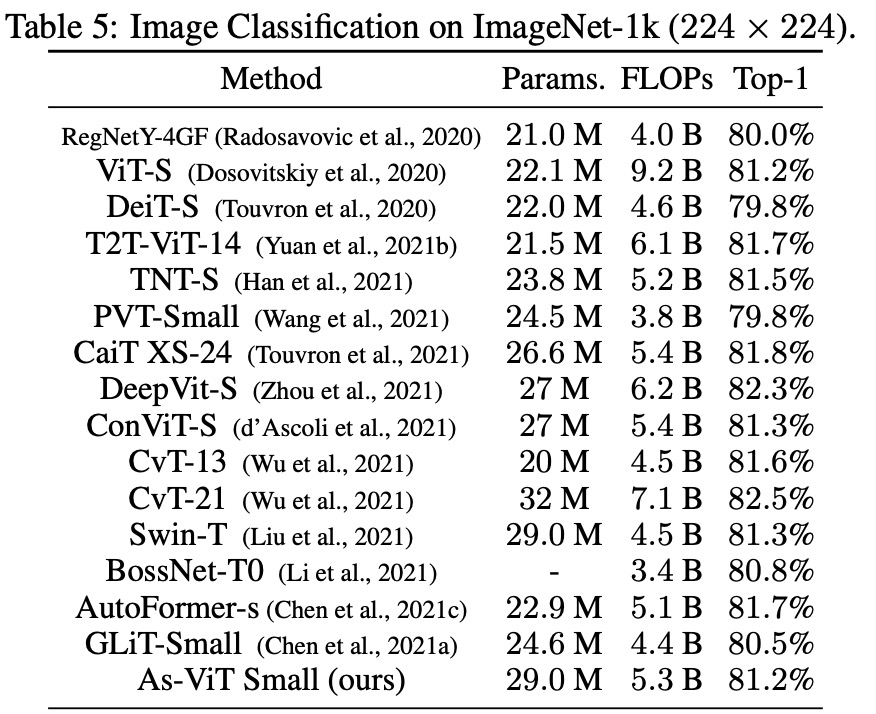
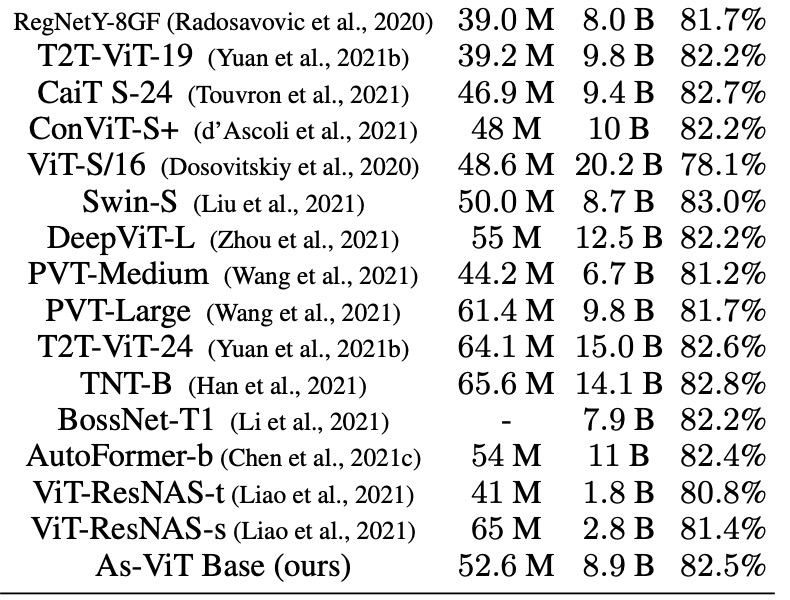
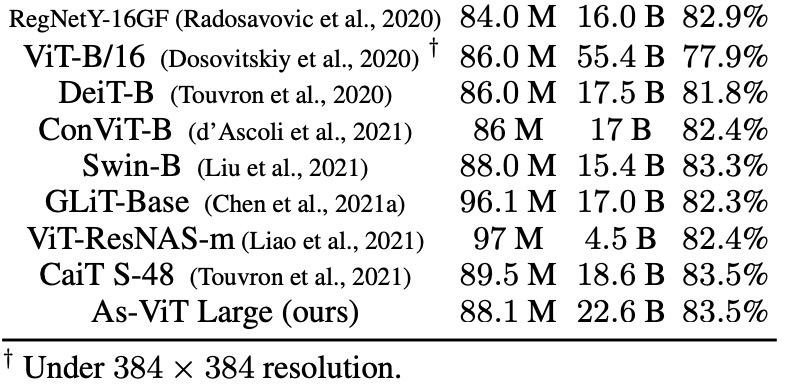
下表 5 展示了 As-ViT 與其他模型的比較。與之前基于 Transformer 和基于 CNN 的架構相比,As-ViT 以相當數量的參數和 FLOP 實現了 SOTA 性能。
高效訓練
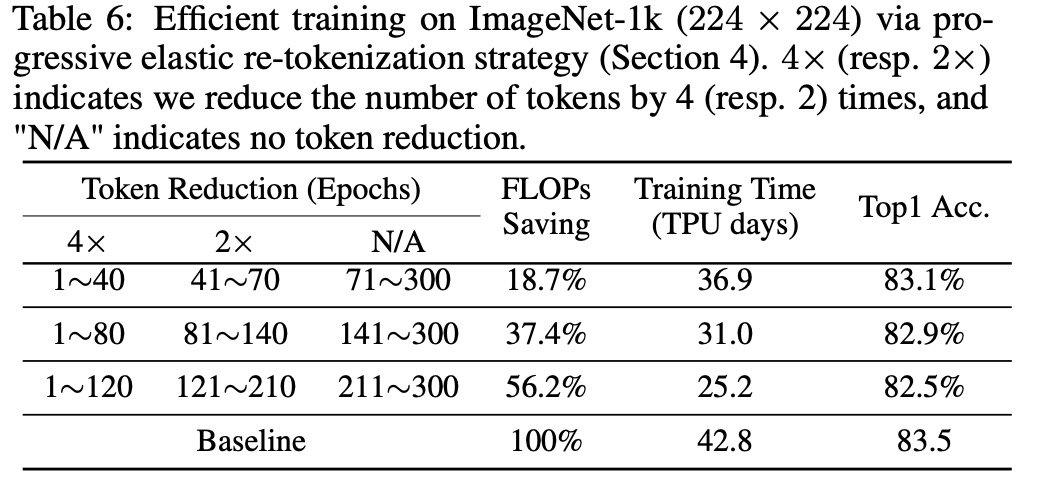
研究者調整了表 6 中為每個 token 減少階段的時期,并將結果顯示在表 6 中。標準訓練需要 42.8 TPU 天,而高效訓練可節省高達 56.2% 的訓練 FLOP 和 41.1% 的訓練 TPU 天,仍然達到很高的準確率。
拓撲和擴展的貢獻
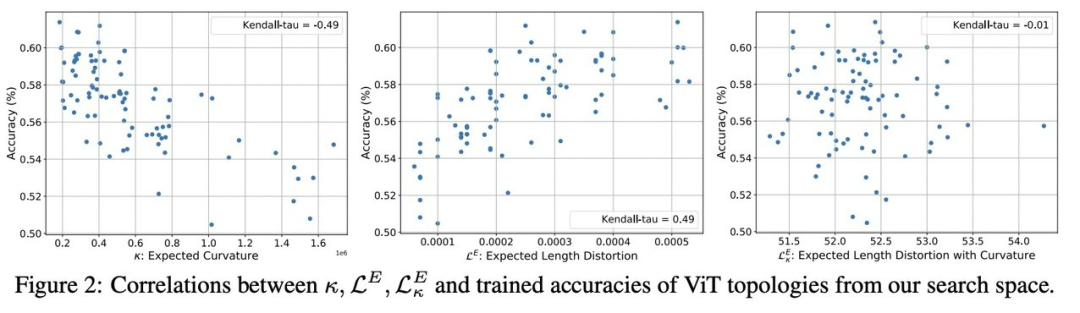
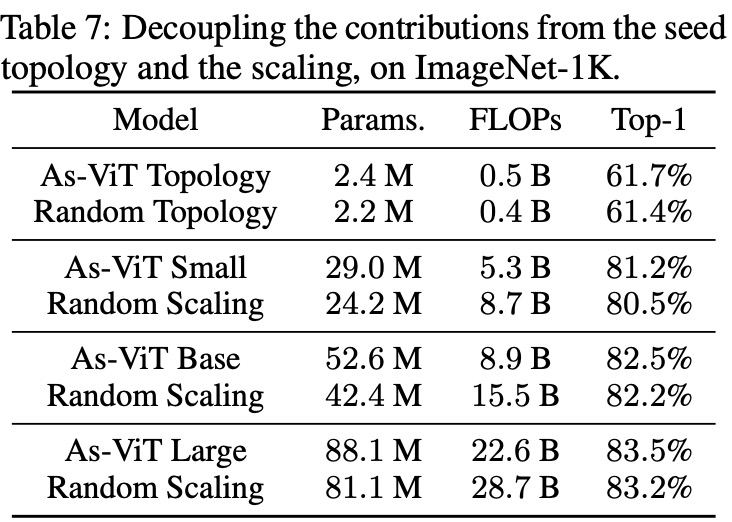
為了更好地驗證搜索型拓撲和擴展規則的貢獻,該研究進行了更多的消融研究(表 7)。首先,在擴展之前直接訓練搜索到的拓撲。該研究搜索的種子拓撲優于圖 2 中 87 個隨機拓撲中的最佳拓撲。
第二,該研究將基于復雜度的規則與「隨機擴展 + As-ViT 拓撲」進行比較。在不同的擴展下,該研究的自動擴展也優于隨機擴展。
COCO 數據集上的目標檢測
該研究將 As-ViT 與標準 CNN 和之前的 Transformer 網絡進行了比較。比較是通過僅更改主干而其他設置未更改來進行的。從下表 8 的結果可以看出,As-ViT 也可以捕獲多尺度特征并實現最先進的檢測性能,盡管它是在 ImageNet 上設計的,并且它的復雜性是為分類而測量的。
?
 ?
?