













視覺Transformer BERT預訓練新方式:中科大、MSRA等提出PeCo
基于大型語料庫訓練的 Transformer 模型在自然語言處理中取得了巨大的成功,作為 Transformer 構建塊,self-attention 極大地改變了計算機視覺任務。NLP 的成功不僅依賴于 Transformer 的計算效率和可擴展性,還依賴于對大量文本進行自監督學習。目前 NLP 領域存在兩種主流的學習范式:基于自回歸語言建模的 GPT 和基于掩碼語言建模的 BERT,這兩者在計算機視覺領域中也被重新設計,以便充分利用海量的網絡圖像。
然而,在視覺任務上設計具有相似風格的目標是具有挑戰性的,因為圖像作為一種高維和冗余的模態,在兩個方面與文本不同:首先,文本由離散字符組成,而圖像在顏色空間中呈現連續值;其次,文本中的離散 token 包含高級語義含義,而離散化的圖像在像素級和 patch 級包含大量冗余 token。
因此,我們不禁會問是否有一種方法可以學習感知離散視覺 token,這將有助于圖像預訓練。
基于上述觀察,來自中國科學技術大學、微軟亞研等機構的研究者提出了學習感知 codebook( perceptual codebook ,PeCo),用于視覺 transformer 的 BERT 預訓練。目前,BEiT 成功地將 BERT 預訓練從 NLP 領域遷移到了視覺領域。BEiT 模型直接采用簡單的離散 VAE 作為視覺 tokenizer,但沒有考慮視覺 token 語義層面。相比之下,NLP 領域中的離散 token 是高度語義化的。這種差異促使研究者開始學習感知 codebook,他們發現了一個簡單而有效的方法,即在 dVAE 訓練期間強制執行感知相似性。
該研究證明 PeCo 生成的視覺 token 能夠表現出更好的語義,幫助預訓練模型在各種下游任務中實現較好的遷移性能。例如,該研究使用 ViT-B 主干在 ImageNet-1K 上實現了 84.5% 的 Top-1 準確率,在相同的預訓練 epoch 下比 BEiT 高 1.3。此外,該方法還可以將 COCO val 上的目標檢測和分割任務性能分別提高 +1.3 box AP 和 +1.0 mask AP,并且將 ADE20k 上的語義分割任務提高 +1.0 mIoU。

論文地址:https://arxiv.org/pdf/2111.12710v1.pdf
方法
在自然語言中,詞是包含高級語義信息的離散 token。相比之下,視覺信號是連續的,具有冗余的低級信息。在本節中,該研究首先簡要描述了 VQ-VAE 的離散表示學習,然后介紹如何學習感知 codebook 的過程,最后對學習感知視覺 token 進行 BERT 預訓練。
學習用于可視化內容的離散 Codebook
該研究利用 VQ-VAE 將連續圖像內容轉換為離散 token 形式。圖像表示為 x∈ R^H×W×3,VQ-VAE 用離散視覺 Codebook 來表示圖像,即
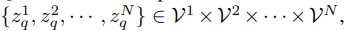
其中,VQ-VAE 包含三個主要部分:編碼器、量化器和解碼器。編碼器負責將輸入圖像映射到中間潛在向量 z = Enc(x);量化器根據最近鄰分配原則負責將位置 (i, j) 處的向量量化為來自 Codebook 對應的碼字(codewords):
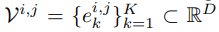
然后得到如下公式:

其中 q 是量化編碼器,可以將向量映射到 codebook 索引,r 是量化解碼器,可以從索引重構向量。基于量化的碼字為 z_q,解碼器旨在重構輸入圖像 x。VQ-VAE 的訓練目標定義為:
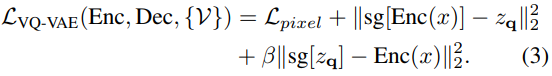
學習用于視覺內容的 PeCo
該研究提出,在不包含像素損失的情況下,對模型強制執行原始圖像和重構圖像之間的感知相似性。感知相似性不是基于像素之間的差異得到的,而是基于從預訓練深度神經網絡中提取的高級圖像特征表示之間的差異而得到。該研究希望這種基于 feature-wise 的損失能夠更好地捕捉感知差異并提供對低級變化的不變性。下圖從圖像重構的角度展示了模型使用不同損失的比較,結果表明圖像在較低的 pixel-wise 損失下可能不會出現感知相似:

圖 1. 不同損失下的圖像重構比較。每個示例包含三個圖像,輸入(左)、使用 pixel-wise 損失重構圖像(中)、使用 pixel-wise 損失和 feature-wise 損失重構圖像(右)。與中間圖像相比,右側圖像在感知上與輸入更相似。
在形式上,假設輸入圖像 x 和重構圖像
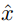
的感知度量可以表示為:
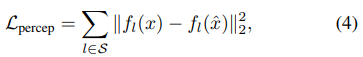
其中 S 表示提取特征的層數,總的目標函數為:
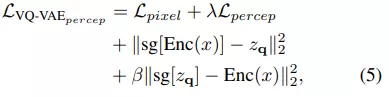
BERT objective 執行掩碼圖像建模
該研究采用 BERT objective 在離散視覺 token 上執行掩碼圖像建模任務,如 BEiT。對于給定的圖像 x,輸入 token 為不重疊的圖像 patch,輸出 token 是通過學習方程 (5) 獲得的離散感知視覺單詞。設輸入為 {x_1 , x_2 , · · · , x_N },并且真值輸出為
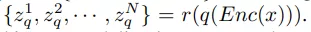
。 掩碼圖像建模的目標是從掩碼輸入中恢復相應的視覺 token,其中一部分輸入 token 已被掩碼掉。準確地說,令 M 為掩碼索引集合,掩碼輸入
表示為:
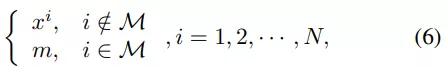
其中,m 是與非掩碼 token 相同維度的可學習掩碼 token。掩碼(masked)輸入 token 被送入 L 層視覺 Transformer,最后一層的隱藏輸出表示為 {h^1 , h^2 , · · · , h^N }。
實驗
該研究將預訓練模型應用于各種下游任務,包括 ImageNet-1K 分類、COCO 目標檢測和 ADE20k 分割。
與 SOTA 模型比較
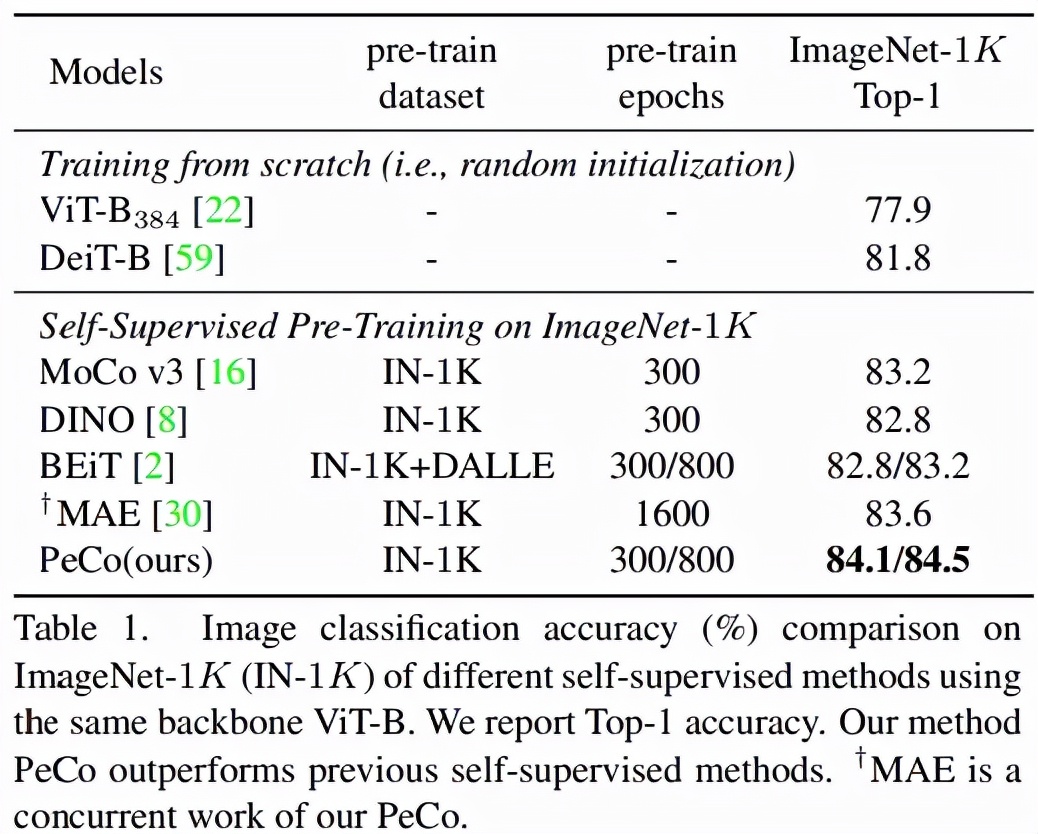
首先該研究將 PeCo 與 SOTA 研究進行比較。研究者使用 ViT-B 作為主干并在 ImageNet-1K 上進行預訓練,epoch 為 300 。
圖像分類任務:在 ImageNet 1K 上進行分類任務的 Top-1 準確率如表 1 所示。可以看出,與從頭開始訓練的模型相比,PeCo 顯著提高了性能,這表明預訓練的有效性。更重要的是,與之前自監督預訓練模型相比,PeCo 模型實現了最佳性能。值得一提的是,與采用 800 epoch 的 BEiT 預訓練相比,PeCo 僅用 300 epoch 就實現了 0.9% 的提高,并比 MAE 采用 1600 epoch 預訓練性能提高 0.5%。這驗證了 PeCo 確實有利于預訓練。
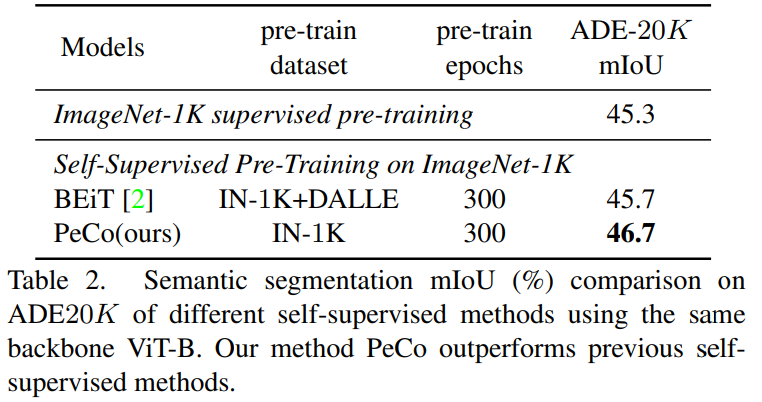
語義分割任務:該研究將 PeCo 與 1)在 ImageNet-1K 上進行監督預訓練和 2)BEiT(SOTA 性能自監督學習模型)進行比較,評估指標是 mIoU,結果如表 2 所示。由結果可得,PeCo 在預訓練期間不涉及任何標簽信息,卻取得了比監督預訓練更好的性能。此外,與自監督 BEiT 相比,PeCo 模型也獲得了較好的性能,這進一步驗證了 PeCo 的有效性。
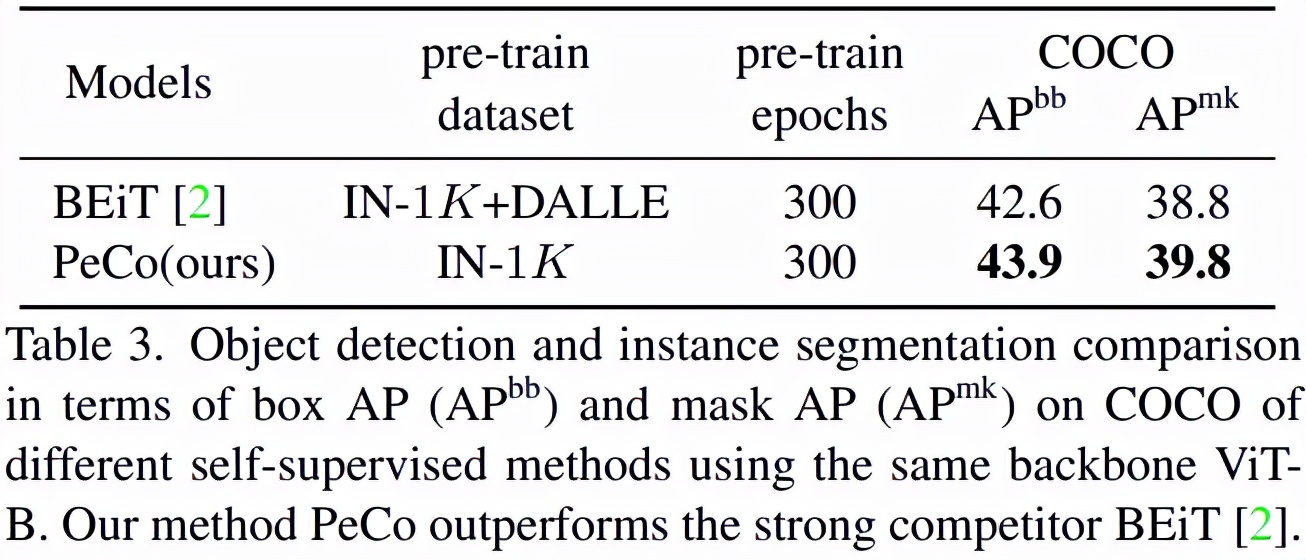
目標檢測與分割:如表 3 所示,在這一任務上,PeCo 獲得了最好的性能:
感知 Codebook 分析
碼字語義:學習的感知碼字是否具有(更多)語義含義?為了回答這個問題,該研究設計實驗以提供視覺和定量結果。
首先,該研究將對應于相同碼字的圖像 patch 進行可視化,并與兩個基線進行比較:在 2.5 億私有數據上訓練而成的 DALL-E codebook;不使用感知相似性的 PeCo 模型的一個變體。結果如圖 3 所示,我們可以看到該研究碼字與語義高度相關,如圖中所示的輪子,來自基線的碼字通常與低級信息(如紋理、顏色、邊緣)相關。

此外,該研究還與不使用感知相似性的變體進行了比較。如表 4 所示, 我們可以發現感知碼字在線性評估和重構圖像分類方面獲得了更高的準確率。這表明感知 codebook 具有更多的語義意義,有利于圖像重構過程。

下圖為使用 BEiT 和 PeCo 在 ImageNet-1k 上重構任務的示例。對于每個樣本,第一張是原始圖像,第二張是對應的掩碼圖像,第三張是 BEiT 重構圖像,最后一張是從感知 codebook(PeCo)重構的圖像。PeCo 在感知 codebook 的幫助下,能夠對掩碼區域進行更語義化的預測。




























