CV圈對決:谷歌提出ViTGAN,用視覺Transformer訓(xùn)練GAN
卷積神經(jīng)網(wǎng)絡(luò)(convoluitonal neural networks,CNN)憑借強(qiáng)大的卷積和池化(pooling)能力,在計算機(jī)視覺領(lǐng)域占領(lǐng)主導(dǎo)地位。
而最近Transformer架構(gòu)的興起,開始在圖像和視頻識別任務(wù)中與CNN「掰頭」。特別是視覺Transformer(ViT)。
Dosovitskiy等人的研究已經(jīng)展示了將圖像解釋為一系列類似于自然語言中的單詞的標(biāo)記(token)。在ImageNet基準(zhǔn)測試中,以較小的FLOP實現(xiàn)可比的分類精度。

現(xiàn)在盡管ViT及其變體仍然處于起步階段,但鑒于ViT在圖像識別方面表現(xiàn)出對競爭性,以及需要較少的視覺特定歸納偏差,ViT能不能擴(kuò)展應(yīng)用到圖像生成呢?
由谷歌和加州大學(xué)圣地亞哥分校組成的研究團(tuán)隊對這個問題進(jìn)行了研究,并發(fā)表了論文:ViTGAN:用視覺Transformer訓(xùn)練生成對抗網(wǎng)絡(luò)(GAN)。

△ https://arxiv.org/pdf/2107.04589.pdf
論文研究的問題是:ViT是否可以在不使用卷積或池化的情況下完成圖像生成任務(wù),即ViT是否能用具有競爭質(zhì)量的GAN訓(xùn)練出基于CNN的GAN。
研究團(tuán)隊將ViT架構(gòu)集成到中GAN中,發(fā)現(xiàn)現(xiàn)有的GAN正則化方法與自我注意機(jī)制的交互很差,導(dǎo)致訓(xùn)練過程中嚴(yán)重的不穩(wěn)定。
因此,團(tuán)隊引入了新的正則化技術(shù)來訓(xùn)練帶有ViT的GAN,得出以下研究結(jié)果:
1. ViTGAN模型遠(yuǎn)優(yōu)于基于Transformer的GAN模型,在不使用卷積或池化的情況下,性能與基于CNN的GAN(如Style-GAN2)相當(dāng)。
2. ViTGAN模型是首個在GAN中利用視覺Transformer的模型之一。
3. ViTGAN模型展示了在標(biāo)準(zhǔn)圖像生成基準(zhǔn)(包括CIFAR、CelebA和LSUN bedroom數(shù)據(jù)集)中,這種Transformer與最先進(jìn)的卷積架構(gòu)具有可比性的方法。
實驗方法
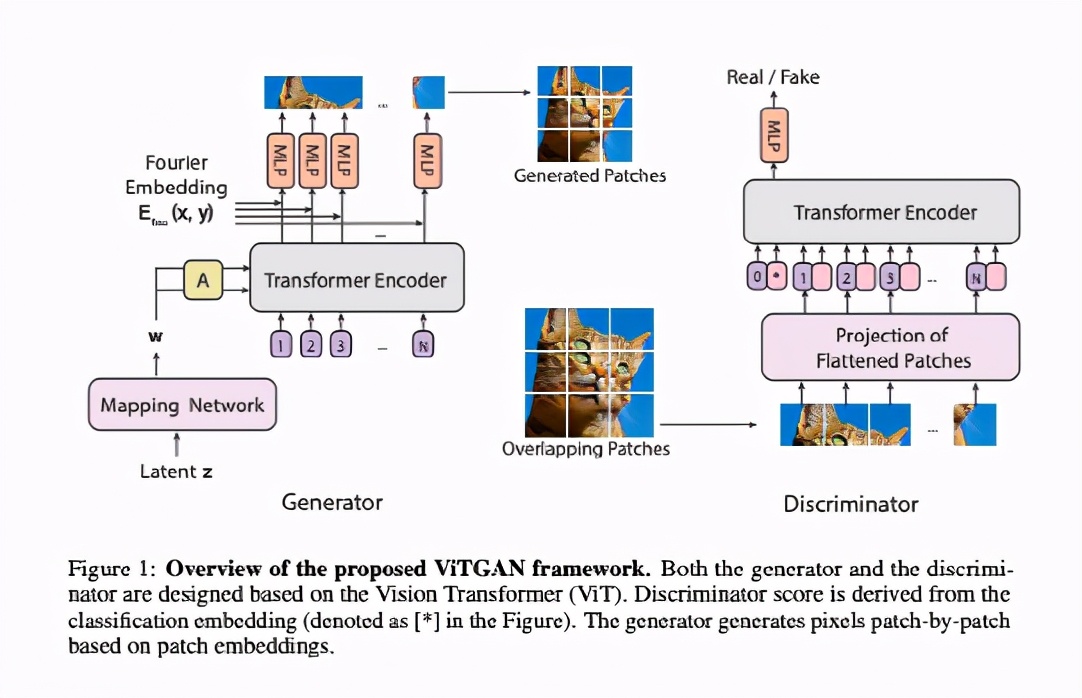
上圖說明了ViTGAN的架構(gòu),包括一個ViT鑒別器和一個基于ViT的生成器。
實驗發(fā)現(xiàn),直接使用ViT作為鑒別器會使訓(xùn)練變得不穩(wěn)定。作者對生成器和鑒別器都引入了新的技術(shù),用來穩(wěn)定訓(xùn)練動態(tài)并促進(jìn)收斂。(1)ViT鑒別器的正則化;(2)生成器的新架構(gòu)。
由于現(xiàn)有的 GAN 正則化方法與 self-attention 的交互很差,在訓(xùn)練過程中導(dǎo)致嚴(yán)重的不穩(wěn)定。
為了解決這個問題,作者引入了新穎的「正則化」技術(shù)來訓(xùn)練帶有 ViT 的 GAN數(shù)據(jù)集上實現(xiàn)了與最先進(jìn)的基于CNN 的 StyleGAN2 相當(dāng)?shù)男阅堋?/p>
利普希茨連續(xù)(Lipschitz continuity)在GAN鑒別器中很重要,首先它作為WGAN中近似Wasserstein距離的一個條件而引入注意力,后來在其他GAN設(shè)置中被證實超出了 Wasserstein損失。特別是,證明了Lipschitz鑒別器保證了最優(yōu)鑒別函數(shù)的存在以及唯一納什均衡的存在。
然而,最近的一項工作表明,標(biāo)準(zhǔn)dot product self-attention(即Equation 5)層的Lipschitz常數(shù)可以是無界的,使Lipschitz連續(xù)在ViTs中被違反。
如Equation 7所示,實驗用歐氏距離代替點積相似度,query 和 key的投影矩陣的權(quán)重也是一樣的。
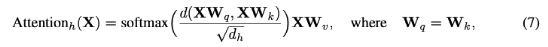
實驗發(fā)現(xiàn),在初始化時將每層的歸一化權(quán)重矩陣與spectral norm相乘就足以解決這個問題。實驗用以下的更新規(guī)則來實現(xiàn)spectral norm,其中σ計算權(quán)重矩陣的標(biāo)準(zhǔn)spectral norm.
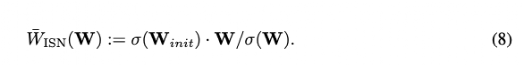
設(shè)計生成器
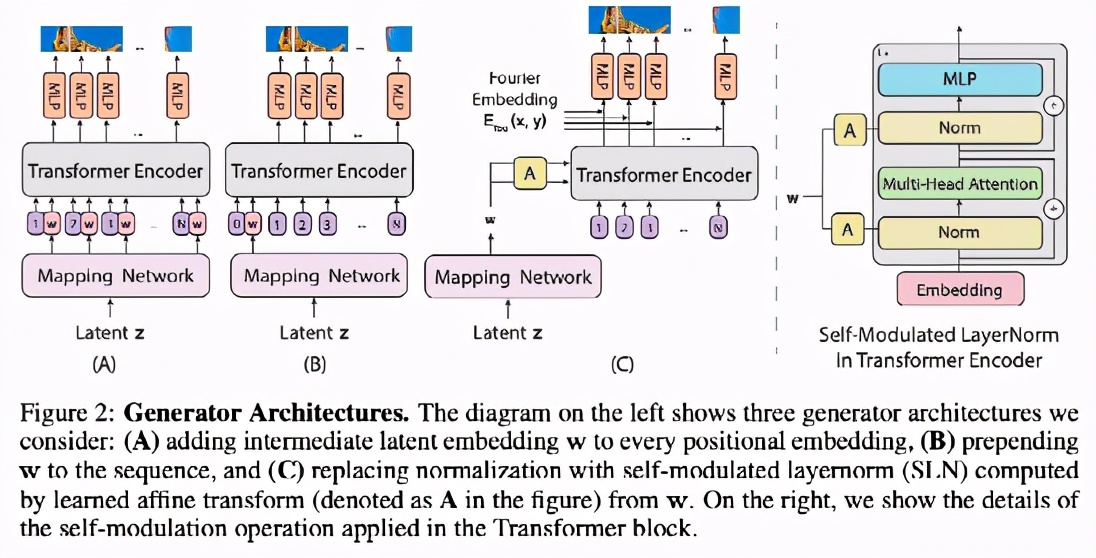
設(shè)計一個基于ViT架構(gòu)的生成器并不簡單。一個挑戰(zhàn)是將ViT從預(yù)測一組類別標(biāo)簽轉(zhuǎn)換為在一個空間區(qū)域內(nèi)生成像素點。
在介紹實驗?zāi)P椭埃髡呦扔懻搩蓚€可信的基線模型,如Fig. 2 (A)和2 (B)所示。這兩個模型交換ViT的輸入和輸出,從嵌入物中生成像素,特別是從潛伏向量 w,即w=MLP(z)(Fig. 2中稱為映射網(wǎng)絡(luò)),由MLP從高斯噪聲向量z中導(dǎo)出。
這兩個基線生成器在輸入序列上有所不同。Fig. 2(A)將一個位置嵌入序列作為輸入位置嵌入序列,并在每個位置嵌入中加入中間特征向量w.
實驗結(jié)果
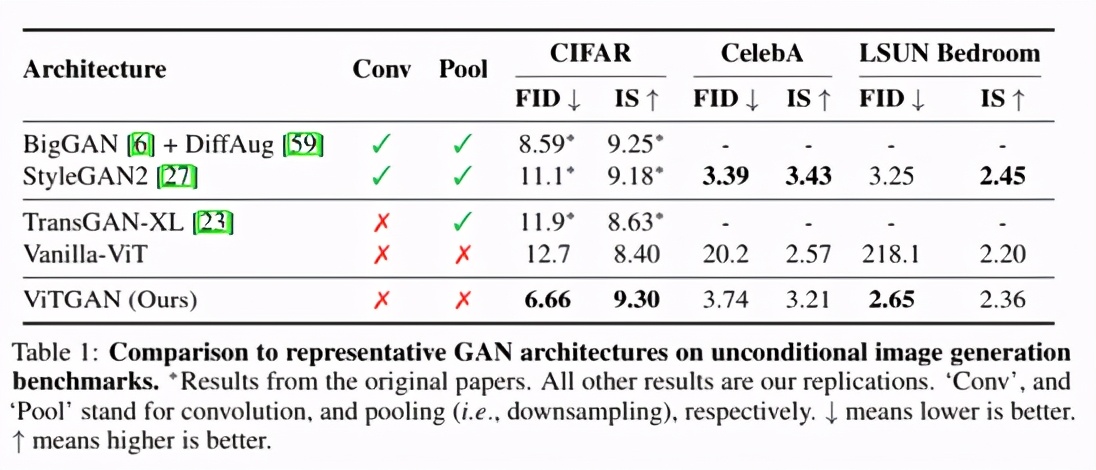
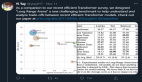
△ ViTGAN與基線架構(gòu)關(guān)于圖像合成的主要結(jié)果對比
TransGAN是現(xiàn)有唯一一個完全建立在 Transformer 架構(gòu)上的無卷積GAN,其最佳變體是TransGAN-XL。
Vanilla-ViT是一種基于ViT的GAN,它使用圖2(A)中所示的生成器和一個vanilla ViT鑒別器。
為公平比較,該基線使用了R1 penalty和bCR + DiffAug。
此外,BigGAN和StyleGAN2也作為最先進(jìn)的基于CNN的GAN模型加入對比。
從上述表格可以看出,ViTGAN模型大大優(yōu)于其他基于Transformer的GAN模型。這是在 Transformer架構(gòu)上改進(jìn)的穩(wěn)定GAN訓(xùn)練的結(jié)果。它實現(xiàn)了與最先進(jìn)的基于 CNN 的模型相當(dāng)?shù)男阅堋?/p>
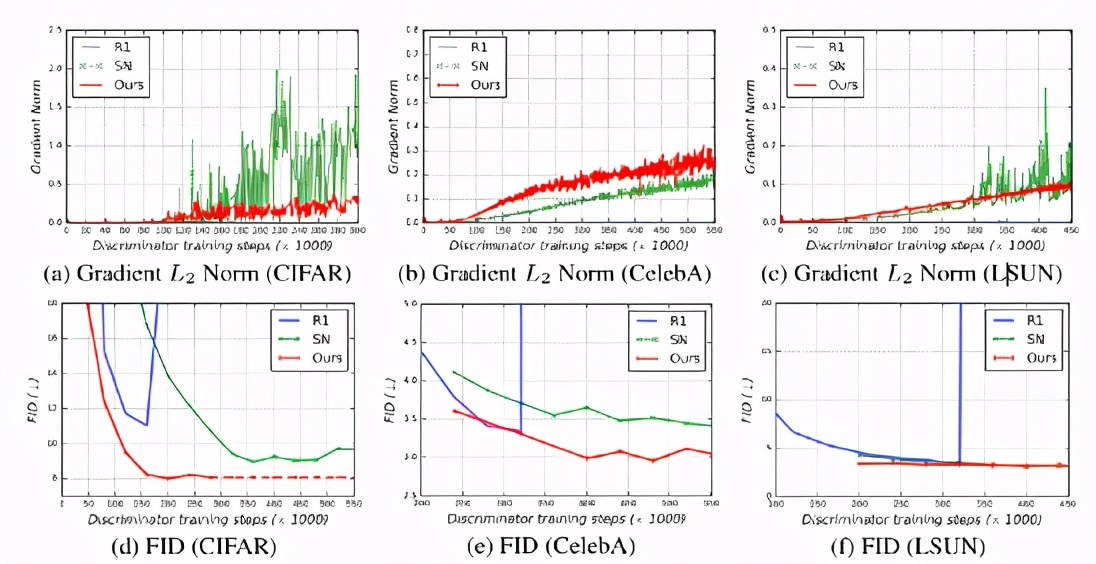
這一結(jié)果提供了一個經(jīng)驗證據(jù):Transformer架構(gòu)可以在生成對抗訓(xùn)練中與卷積網(wǎng)絡(luò)相媲美。



如上圖所示,ViTGAN模型(最后一列)顯著提高了最佳 Transformer 基線(中間列)的圖像保真度。即使與StyleGAN2相比,ViTGAN生成的圖像質(zhì)量和多樣性也相當(dāng)。
總結(jié)
這篇論文介紹了ViTGAN,利用GAN中的視覺Transformer(ViTs),并提出了確保其訓(xùn)練穩(wěn)定性和提高收斂性的基本技術(shù)。
在標(biāo)準(zhǔn)基準(zhǔn)(CIFAR-10、CelebA和LSUN bedroom)上的實驗表明,提出的模型實現(xiàn)了與最先進(jìn)的基于CNN的GAN相媲美的性能。
至于限制,ViTGAN是一個建立在普通ViT架構(gòu)上的新的通用GAN模型。它仍然無法擊敗最好的基于CNN的GAN模型。
這可以通過將先進(jìn)的訓(xùn)練技術(shù)納入ViTGAN框架得到改善。希望ViTGAN能夠促進(jìn)這一領(lǐng)域未來的研究,并可以擴(kuò)展到其他圖像和視頻合成任務(wù)。