清華博士后用10分鐘講解AlphaCode背后的技術原理,原來程序員不是那么容易被取代的!

本文轉自雷鋒網,如需轉載請至雷鋒網官網申請授權。
不久前,DeepMind 的團隊發布了一個可以自動生成競賽級代碼的人工智能系統——AlphaCode,號稱「媲美普通程序員」,一經發表就在國內外的AI圈里引起了巨大轟動。

-論文地址:https://storage.googleapis.com/deepmind-media/AlphaCode/competition_level_code_generation_with_alphacode.pdf
-數據集:https://github.com/deepmind/code_contests
根據DeepMind的博客介紹,AlphaCode 在號稱「全球最強算法平臺」Codeforces 上的 5,000 名用戶解決的 10 項挑戰中進行了測試。AlphaCode能夠以與人類完全相同的格式在這10項挑戰中自動輸入代碼,生成大量可能的答案,然后像人類程序員一樣通過運行代碼和檢查篩選出可行答案,最終在人類程序員中取得了排名前 54%的好成績。
也就是說,AlphaCode的代碼能力媲美在Codeforces上參加過測試的幾乎一半程序員(2300名)。按照一個初級程序員月薪2萬的算法,AlphaCode有望每年替全球人類資本家省下5.52億的人力成本,使一半程序員失業……
不過,DeepMind團隊當時也明確指出了:AlphaCode目前只適用于競爭類編程比賽。
不可否認,這也是繼DeepMind發布Alpha Go、AlphaZero與AlphaFold之后的又一研究突破,極大地增加了其Alpha系列的傳奇色彩。但與該系列的其他工作(如AlphaGo打敗世界圍棋冠軍)相比,AlphaCode的性能似乎并不突出,
目前正在清華大學朱軍門下擔任博士后研究員的Tea Pearce對AlphaCode的技術原理十分感興趣,對DeepMind的這篇31頁論文進行仔細閱讀后,制作了一個短視頻發表在油管上,從系統概述、測試階段、數據集的預訓練與微調、Transformer模型的訓練過程與Transformer架構等維度對AlphaCode的細節進行了較為詳細的講解。
視頻地址:https://www.youtube.com/watch?v=YjsoN5aJChA
與OpenAI之前開發的GPT-3一樣,AlphaCode也是基于Transformer模型,只不過前者側重于言生成,后者則強調對順序文本(如代碼)的解析。
下面AI科技評論對該短視頻進行了簡單整理:
1 AlphaCode的代碼問題
當前,AlphaCode的目標編碼問題集中為特定的競賽類型,在諸如Codeforces的網站上參加編碼挑戰,其中,這些挑戰包含對一個問題的簡短描述與帶有測試案例的示例,為挑戰者提供了能與正確預期輸出相匹配的輸入。
簡而言之,這些挑戰的目標就是編寫一些代碼,為示例的測試案例與一組隱藏測試案例提供符合預期的輸出。如果你的代碼通過了所有測試,那么你就解決了這個問題。
根據DeepMind的介紹,AlphaCode在Codeforces網站所舉辦的編碼挑戰中取得了與普通用戶相媲美的成功率。
2 AlphaCode系統概述
那么,AlphaCode的工作原理究竟是怎樣的呢?
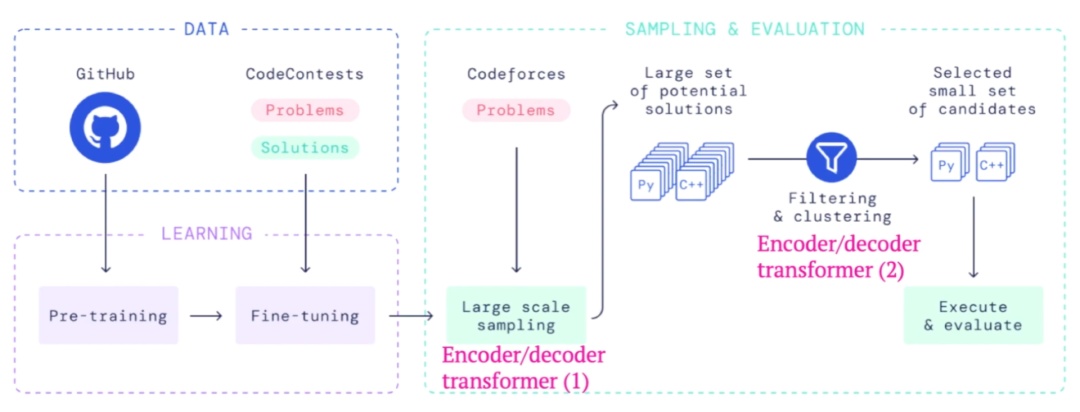
在DeepMind團隊所發表的“Competition-Level Code Generation with AlphaCode”一文中,他們給出了一個高級的概要圖(如下)。如圖所示,AlphaCode的核心組件仍然是Transformer語言模型,其余單獨組件也是舊的。
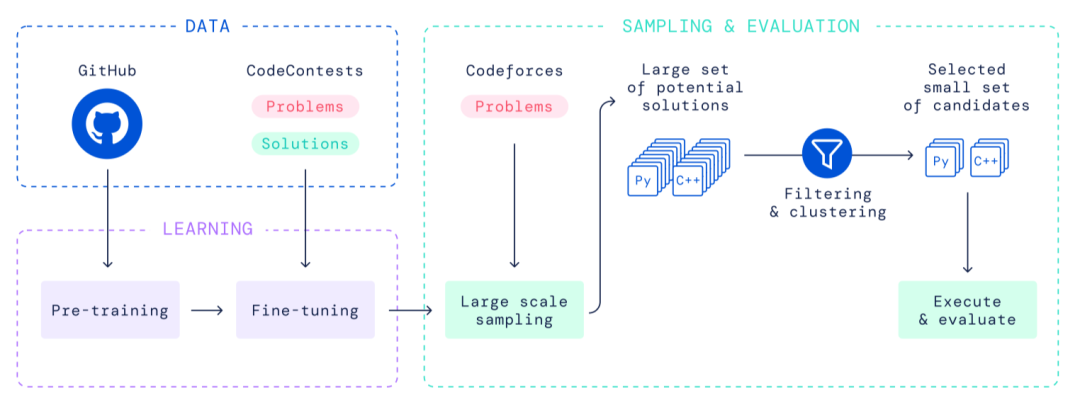
圖注:AlphaCode的系統圖
3 使用的協議
我們先看看AlphaCode在測試時是如何工作的。
首先要知道的一點是,在解決寫代碼的問題時,AlphaCode使用了一個非常具體的協議(protocol),且該協議決定了該系統的管道。根據論文顯示,DeepMind團隊獲得了使用盡可能多的示例測試案例的權限,因為這些測試案例也包含在該問題內。
不過,他們確實將自己的測試限制在了10個提交的隱藏測試發送案例內。
4 測試階段的AlphaCode
AlphaCode的測試時間分為三個獨立的階段。
他們首先使用了一個大規模的Transformer模型,將問題描述示例測試和問題的一些元數據作為輸入,然后從模型中取樣,生成大量潛在的解決方案。之所以先生成大量的潛在解決方案,是因為大多數腳本無法為某些人、甚至編譯器所編譯。
因此,在第二與第三階段,他們就主要針對這100萬個潛在代碼腳本作「減法」,選出他們認為在給定協議的前提下可能有用的10個方案。而他們的做法也很簡單,就是在示例測試案例中測試完這100萬個代碼腳本,然后將無法通過測試的大約99%個腳本排除掉,這就將腳本的數量減少到了千位數。
不過,協議要求其還要繼續縮減到10個解決方案。于是,他們又采取了一個非常聰明的方法:
他們使用了第二個Transformer模型將問題描述作為輸入,但不是嘗試生成代碼來解決問題,而是用Transformer生成測試案例輸入,并為每個問題抽樣50個測試案例輸入。現在,他們不嘗試生成輸入與輸出對,而只是試圖產生一些與問題相關的現實輸入。所以,AlphaCode可能必須根據問題所在,生成字符串、二進制數或數字列表等。
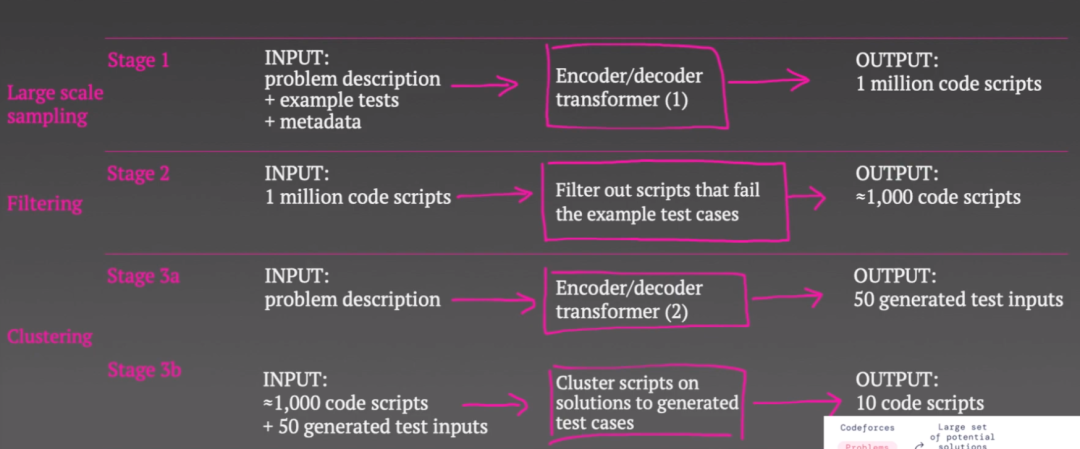
圖注:Tim Pearce對AlphaCode在測試時的三個階段進行講解
為什么這是個好主意?因為他們認為如果兩個腳本對所有 50 個生成的測試所返回的答案是相同的,那么它們就可能使用相同的算法,并且可能不想浪費兩個提交來嘗試這兩個腳本。
所以,他們在這 50 個生成的輸入上編譯并運行大約 1000 個腳本。然后,他們根據這 50 個虛構輸入的輸出對腳本進行聚類。接著,他們會從每個聚類中選擇一個示例腳本。如果十個腳本中的任何一個通過了所有隱藏測試,那么這些腳本就是最終的10個腳本,他們也就成功地解決了編碼問題,否則就是失敗。這就是 AlphaCode 在測試時的工作方式。
這其中涉及到對Transformer模型的訓練,可以看下文。
5 對數據集進行預訓練與微調
AlphaCode 使用的是當今深度學習中相當標準的預訓練微調過程。
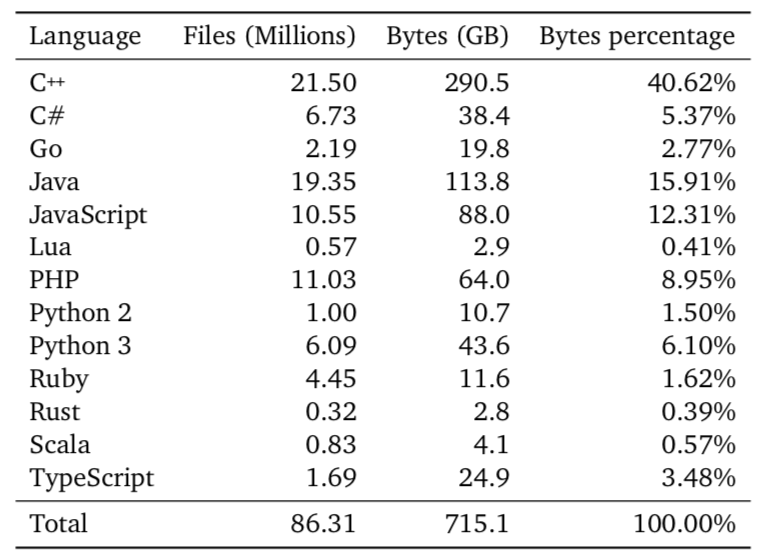
這里有兩個數據集:第一個數據集是由各種編程語言組成的公共 Github 存儲庫,包含 715 GB 海量代碼,用于預訓練階段,目的是讓Transformer學習一些非常通用的知識,比如代碼結構和語法。
第二個數據集要小得多,只服務于 AlphaCode 的目標,用于微調。該數據集是從一些編碼挑戰網站上抓取的,包括Codeforces。他們稍后會在數據集上進行測試,包含問題描述測試用例和人工編寫的解決方案。這些是數據集。現在,我們該怎么處理它們?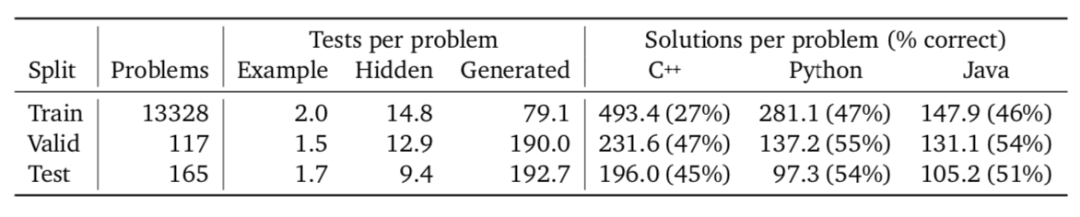
6 Transformer模型的訓練過程
首先說一下預訓練階段。
他們抓取了一些 github 代碼,并隨機選擇所謂的樞軸點(pivot point)。
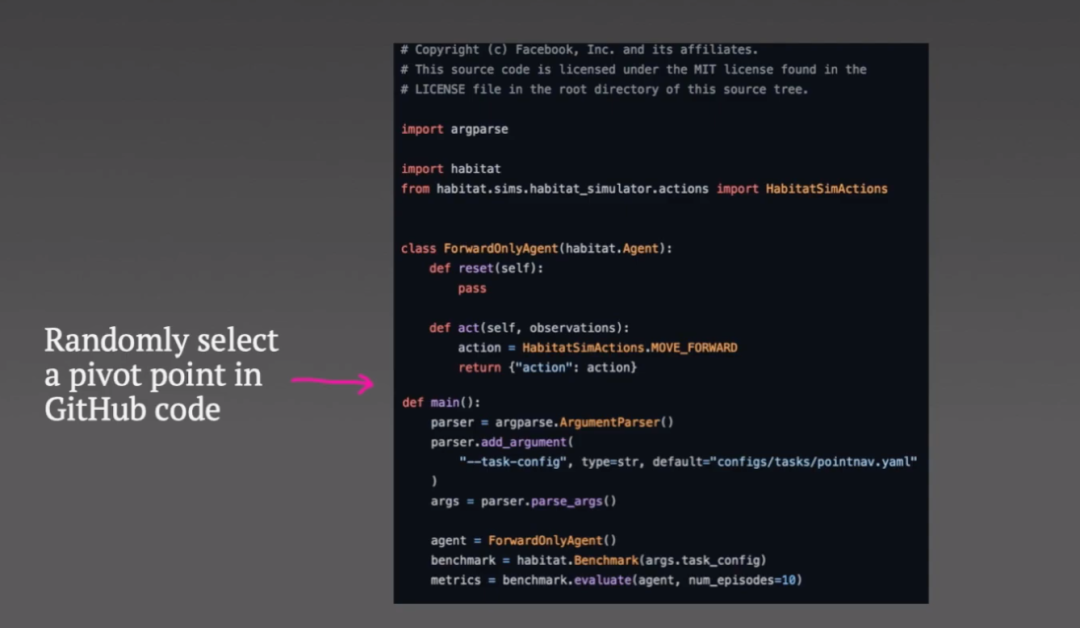
樞軸點之前的所有內容都會被輸入編碼器,而解碼器的目標是重建樞軸點以下的代碼。
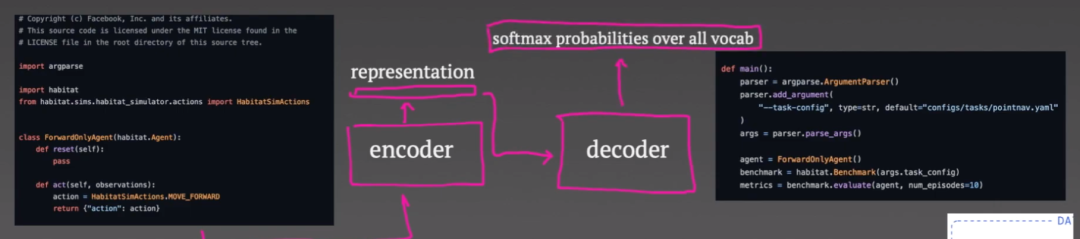
編碼器僅輸出代碼的向量表示,可用于整個解碼過程。
解碼器以自回歸方式運行:首先預測代碼的第一個標記。然后,損失函數只是預測的 softmax 輸出和真實令牌(token)之間的交叉熵。第一個真正的令牌會成為解碼器的輸入,然后預測第二個令牌,并且當要求解碼器預測代碼令牌的意外結束時,重復此過程直到代碼結束。
現在,這些損失通過解碼器和編碼器反向傳播,盡管事實證明:只為編碼器添加第二個損失很重要。
這被稱為掩碼語言,可以高效地建模損失。將輸入到編碼器中的一些令牌清空。作為一種輔助任務,編碼器嘗試預測哪個令牌被屏蔽。一旦預訓練任務完成,我們就進入微調任務。
在這里,我們將問題描述的元數據和示例輸入投喂到編碼器中,并嘗試使用解碼器生成人工編寫的代碼。這時,你可以看到這與編碼器-解碼器架構強制執行的結構非常自然地吻合,損失與預訓練任務完全相同。
還有一個生成測試輸入的Transformer。這也是從同一個 github 預訓練任務初始化而來的,但它是經過微調來生成測試輸入,而不是生成代碼。
7 Transformer架構
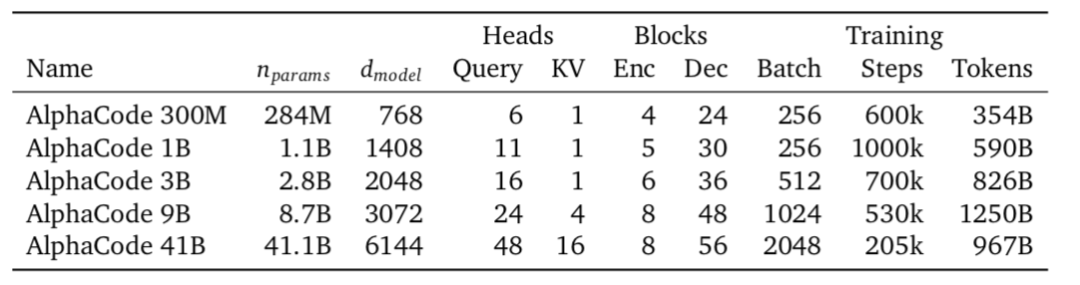
DeepMind 團隊對各種大小的模型進行了實驗。經實驗,較大規模的模型往往表現更好。編碼器和解碼器本身由多頭注意力層組成,且這些層非常標準。
8 其他技巧
該論文有許多進步之處。在這里,我不打算全部介紹,只想強調一個我認為很酷炫的點,就是標簽和評級增強,以及問題描述。
我們總是將元數據作為Transformer的輸入。這包括問題的編程語言難度等級。一些問題的標簽與解決方案在訓練時是否正確?他們顯然知道這些字段的值是什么,但是在測試時他們并不知道什么是酷炫的,那就是他們實際上可以在測試時將不同的內容輸入到這些字段中以影響生成的代碼。例如,你可以控制系統將生成的編程語言,甚至影響這種解決方案。
它嘗試生成比如是否嘗試動態編程方法或進行詳盡搜索的答案。他們在測試時發現有幫助的是,當他們對 100 萬個解決方案的初始池進行抽樣時,是將其中的許多字段隨機化。通過在這個初始池中擁有更多的多樣性,其中一個代碼腳本更有可能是正確的。
9 結語
以上就是 Tea Pearce 對 AlphaCode 工作原理的講解。從AlphaCode的工作出發,他談到自己的思考:為什么DeepMind團隊在這些編碼問題上實現的性能水平比在圍棋(AlphaGo)或星際爭霸(AlphaZero)游戲中的超人水平系統要低得多呢? Tea Pearce的分析是,從自然語言描述中編寫代碼本質上就比玩游戲要困難得多,但這也可能是因為游戲中可用的數據少得多。你可以根據需要模擬盡可能多的數據,而編碼問題的數量是有限的。最后,Tea Pearce拋出問題:AI寫代碼之所以難的原因可能是什么?在未來,AI的代碼水平要怎樣才能超越人類最優水平?