













10分鐘看懂 Java NIO 底層原理
寫在前面
很多的小伙伴,被java IO 模型,搞得有點兒暈,一會兒是4種模型,一會兒又變成了5種模型。
很多的小伙伴,也被nio這個名詞搞暈了,一會兒java 的nio 不叫 非阻塞io,一會兒java nio 又是非阻塞io,到底是啥呢?
很多的小伙伴,被異步和非阻塞搞暈了。都非阻塞了,難道不是異步的嗎?這這,好難呀。
此文,從底層入手,給各位小伙伴,起底一下,java的四大io模型。需要面試的,或者沒有弄清楚的小伙伴,徹底的有福了。
一、Java IO讀寫原理
無論是Socket的讀寫還是文件的讀寫,在Java層面的應用開發或者是linux系統底層開發,都屬于輸入input和輸出output的處理,簡稱為IO讀寫。在原理上和處理流程上,都是一致的。區別在于參數的不同。
用戶程序進行IO的讀寫,基本上會用到read&write兩大系統調用。可能不同操作系統,名稱不完全一樣,但是功能是一樣的。
先強調一個基礎知識:read系統調用,并不是把數據直接從物理設備,讀數據到內存。write系統調用,也不是直接把數據,寫入到物理設備。
read系統調用,是把數據從內核緩沖區復制到進程緩沖區;而write系統調用,是把數據從進程緩沖區復制到內核緩沖區。這個兩個系統調用,都不負責數據在內核緩沖區和磁盤之間的交換。底層的讀寫交換,是由操作系統kernel內核完成的。
1. 內核緩沖與進程緩沖區
緩沖區的目的,是為了減少頻繁的系統IO調用。大家都知道,系統調用需要保存之前的進程數據和狀態等信息,而結束調用之后回來還需要恢復之前的信息,為了減少這種損耗時間、也損耗性能的系統調用,于是出現了緩沖區。
有了緩沖區,操作系統使用read函數把數據從內核緩沖區復制到進程緩沖區,write把數據從進程緩沖區復制到內核緩沖區中。等待緩沖區達到一定數量的時候,再進行IO的調用,提升性能。至于什么時候讀取和存儲則由內核來決定,用戶程序不需要關心。
在linux系統中,系統內核也有個緩沖區叫做內核緩沖區。每個進程有自己獨立的緩沖區,叫做進程緩沖區。
所以,用戶程序的IO讀寫程序,大多數情況下,并沒有進行實際的IO操作,而是在讀寫自己的進程緩沖區。
2. java IO讀寫的底層流程
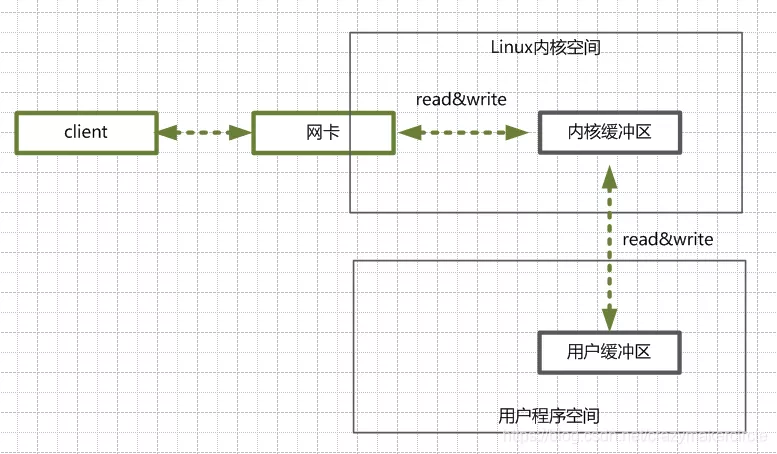
用戶程序進行IO的讀寫,基本上會用到系統調用read&write,read把數據從內核緩沖區復制到進程緩沖區,write把數據從進程緩沖區復制到內核緩沖區,它們不等價于數據在內核緩沖區和磁盤之間的交換。
在這里插入圖片描述
首先看看一個典型Java 服務端處理網絡請求的典型過程:
(1)客戶端請求:Linux通過網卡,讀取客戶斷的請求數據,將數據讀取到內核緩沖區。
(2)獲取請求數據:服務器從內核緩沖區讀取數據到Java進程緩沖區。
(3)服務器端業務處理:Java服務端在自己的用戶空間中,處理客戶端的請求。
(4)服務器端返回數據:Java服務端已構建好的響應,從用戶緩沖區寫入系統緩沖區。
(5)發送給客戶端:Linux內核通過網絡 I/O ,將內核緩沖區中的數據,寫入網卡,網卡通過底層的通訊協議,會將數據發送給目標客戶端。
二、四種主要的IO模型
服務器端編程經常需要構造高性能的IO模型,常見的IO模型有四種:
1. 同步阻塞IO(Blocking IO)
首先,解釋一下這里的阻塞與非阻塞:
阻塞IO,指的是需要內核IO操作徹底完成后,才返回到用戶空間,執行用戶的操作。阻塞指的是用戶空間程序的執行狀態,用戶空間程序需等到IO操作徹底完成。傳統的IO模型都是同步阻塞IO。在java中,默認創建的socket都是阻塞的。
其次,解釋一下同步與異步:
同步IO,是一種用戶空間與內核空間的調用發起方式。同步IO是指用戶空間線程是主動發起IO請求的一方,內核空間是被動接受方。異步IO則反過來,是指內核kernel是主動發起IO請求的一方,用戶線程是被動接受方。
2. 同步非阻塞IO(Non-blocking IO)
非阻塞IO,指的是用戶程序不需要等待內核IO操作完成后,內核立即返回給用戶一個狀態值,用戶空間無需等到內核的IO操作徹底完成,可以立即返回用戶空間,執行用戶的操作,處于非阻塞的狀態。
簡單的說:阻塞是指用戶空間(調用線程)一直在等待,而且別的事情什么都不做;非阻塞是指用戶空間(調用線程)拿到狀態就返回,IO操作可以干就干,不可以干,就去干的事情。
非阻塞IO要求socket被設置為NONBLOCK。
強調一下,這里所說的NIO(同步非阻塞IO)模型,并非Java的NIO(New IO)庫。
3. IO多路復用(IO Multiplexing)
即經典的Reactor設計模式,有時也稱為異步阻塞IO,Java中的Selector和Linux中的epoll都是這種模型。
4. 異步IO(Asynchronous IO)
異步IO,指的是用戶空間與內核空間的調用方式反過來。用戶空間線程是變成被動接受的,內核空間是主動調用者。
這一點,有點類似于Java中比較典型的模式是回調模式,用戶空間線程向內核空間注冊各種IO事件的回調函數,由內核去主動調用。
三、同步阻塞IO(Blocking IO)
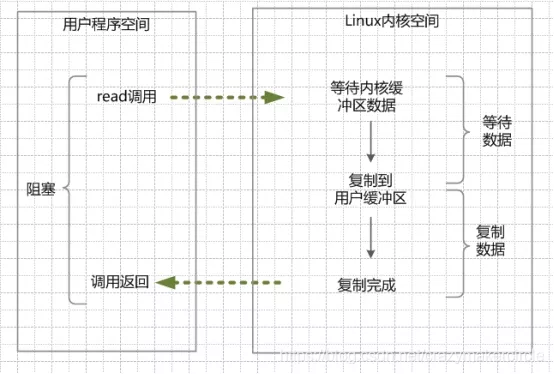
在linux中的Java進程中,默認情況下所有的socket都是blocking IO。在阻塞式 I/O 模型中,應用程序在從IO系統調用開始,一直到到系統調用返回,這段時間是阻塞的。返回成功后,應用進程開始處理用戶空間的緩存數據。
在這里插入圖片描述
舉個栗子,發起一個blocking socket的read讀操作系統調用,流程大概是這樣:
(1)當用戶線程調用了read系統調用,內核(kernel)就開始了IO的第一個階段:準備數據。很多時候,數據在一開始還沒有到達(比如,還沒有收到一個完整的Socket數據包),這個時候kernel就要等待足夠的數據到來。
(2)當kernel一直等到數據準備好了,它就會將數據從kernel內核緩沖區,拷貝到用戶緩沖區(用戶內存),然后kernel返回結果。
(3)從開始IO讀的read系統調用開始,用戶線程就進入阻塞狀態。一直到kernel返回結果后,用戶線程才解除block的狀態,重新運行起來。
所以,blocking IO的特點就是在內核進行IO執行的兩個階段,用戶線程都被block了。
BIO的優點:
程序簡單,在阻塞等待數據期間,用戶線程掛起。用戶線程基本不會占用 CPU 資源。
BIO的缺點:
一般情況下,會為每個連接配套一條獨立的線程,或者說一條線程維護一個連接成功的IO流的讀寫。在并發量小的情況下,這個沒有什么問題。但是,當在高并發的場景下,需要大量的線程來維護大量的網絡連接,內存、線程切換開銷會非常巨大。因此,基本上,BIO模型在高并發場景下是不可用的。
四、同步非阻塞NIO(None Blocking IO)
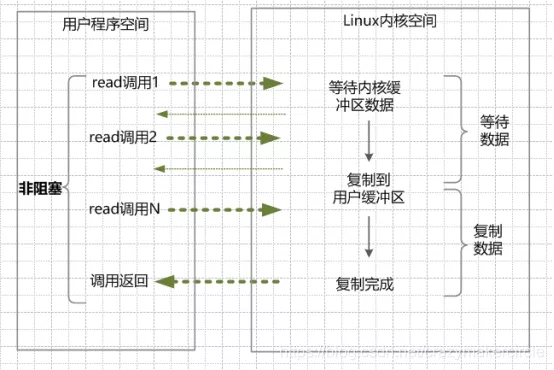
在linux系統下,可以通過設置socket使其變為non-blocking。NIO 模型中應用程序在一旦開始IO系統調用,會出現以下兩種情況:
- 在內核緩沖區沒有數據的情況下,系統調用會立即返回,返回一個調用失敗的信息。
- 在內核緩沖區有數據的情況下,是阻塞的,直到數據從內核緩沖復制到用戶進程緩沖。復制完成后,系統調用返回成功,應用進程開始處理用戶空間的緩存數據。
在這里插入圖片描述
舉個栗子。發起一個non-blocking socket的read讀操作系統調用,流程是這個樣子:
- 在內核數據沒有準備好的階段,用戶線程發起IO請求時,立即返回。用戶線程需要不斷地發起IO系統調用。
- 內核數據到達后,用戶線程發起系統調用,用戶線程阻塞。內核開始復制數據。它就會將數據從kernel內核緩沖區,拷貝到用戶緩沖區(用戶內存),然后kernel返回結果。
- 用戶線程才解除block的狀態,重新運行起來。經過多次的嘗試,用戶線程終于真正讀取到數據,繼續執行。
NIO的特點:應用程序的線程需要不斷的進行 I/O 系統調用,輪詢數據是否已經準備好,如果沒有準備好,繼續輪詢,直到完成系統調用為止。
NIO的優點:每次發起的 IO 系統調用,在內核的等待數據過程中可以立即返回。用戶線程不會阻塞,實時性較好。
NIO的缺點:需要不斷的重復發起IO系統調用,這種不斷的輪詢,將會不斷地詢問內核,這將占用大量的 CPU 時間,系統資源利用率較低。
總之,NIO模型在高并發場景下,也是不可用的。一般 Web 服務器不使用這種 IO 模型。一般很少直接使用這種模型,而是在其他IO模型中使用非阻塞IO這一特性。java的實際開發中,也不會涉及這種IO模型。
再次說明,Java NIO(New IO) 不是IO模型中的NIO模型,而是另外的一種模型,叫做IO多路復用模型( IO multiplexing )。
五、 IO多路復用模型(I/O multiplexing)
如何避免同步非阻塞NIO模型中輪詢等待的問題呢?這就是IO多路復用模型。
IO多路復用模型,就是通過一種新的系統調用,一個進程可以監視多個文件描述符,一旦某個描述符就緒(一般是內核緩沖區可讀/可寫),內核kernel能夠通知程序進行相應的IO系統調用。
目前支持IO多路復用的系統調用,有 select,epoll等等。select系統調用,是目前幾乎在所有的操作系統上都有支持,具有良好跨平臺特性。epoll是在linux 2.6內核中提出的,是select系統調用的linux增強版本。
IO多路復用模型的基本原理就是select/epoll系統調用,單個線程不斷的輪詢select/epoll系統調用所負責的成百上千的socket連接,當某個或者某些socket網絡連接有數據到達了,就返回這些可以讀寫的連接。因此,好處也就顯而易見了——通過一次select/epoll系統調用,就查詢到到可以讀寫的一個甚至是成百上千的網絡連接。
舉個栗子。發起一個多路復用IO的的read讀操作系統調用,流程是這個樣子:
在這里插入圖片描述
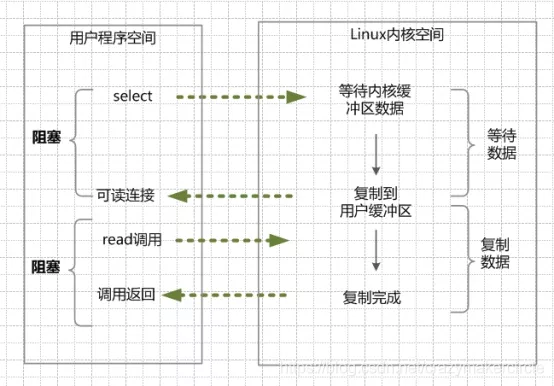
在這種模式中,首先不是進行read系統調動,而是進行select/epoll系統調用。當然,這里有一個前提,需要將目標網絡連接,提前注冊到select/epoll的可查詢socket列表中。然后,才可以開啟整個的IO多路復用模型的讀流程。
(1) 進行select/epoll系統調用,查詢可以讀的連接。kernel會查詢所有select的可查詢socket列表,當任何一個socket中的數據準備好了,select就會返回。
當用戶進程調用了select,那么整個線程會被block(阻塞掉)。
(2)用戶線程獲得了目標連接后,發起read系統調用,用戶線程阻塞。內核開始復制數據。它就會將數據從kernel內核緩沖區,拷貝到用戶緩沖區(用戶內存),然后kernel返回結果。
(3)用戶線程才解除block的狀態,用戶線程終于真正讀取到數據,繼續執行。
多路復用IO的特點:
- IO多路復用模型,建立在操作系統kernel內核能夠提供的多路分離系統調用select/epoll基礎之上的。多路復用IO需要用到兩個系統調用(system call), 一個select/epoll查詢調用,一個是IO的讀取調用。
- 和NIO模型相似,多路復用IO需要輪詢。負責select/epoll查詢調用的線程,需要不斷的進行select/epoll輪詢,查找出可以進行IO操作的連接。
- 另外,多路復用IO模型與前面的NIO模型,是有關系的。對于每一個可以查詢的socket,一般都設置成為non-blocking模型。只是這一點,對于用戶程序是透明的(不感知)。
多路復用IO的優點:
- 用select/epoll的優勢在于,它可以同時處理成千上萬個連接(connection)。與一條線程維護一個連接相比,I/O多路復用技術的最大優勢是:系統不必創建線程,也不必維護這些線程,從而大大減小了系統的開銷。
- Java的NIO(new IO)技術,使用的就是IO多路復用模型。在linux系統上,使用的是epoll系統調用。
多路復用IO的缺點:
- 本質上,select/epoll系統調用,屬于同步IO,也是阻塞IO。都需要在讀寫事件就緒后,自己負責進行讀寫,也就是說這個讀寫過程是阻塞的。
如何充分的解除線程的阻塞呢?那就是異步IO模型。
六、異步IO模型(asynchronous IO)
如何進一步提升效率,解除最后一點阻塞呢?這就是異步IO模型,全稱asynchronous I/O,簡稱為AIO。
AIO的基本流程是:用戶線程通過系統調用,告知kernel內核啟動某個IO操作,用戶線程返回。kernel內核在整個IO操作(包括數據準備、數據復制)完成后,通知用戶程序,用戶執行后續的業務操作。
kernel的數據準備是將數據從網絡物理設備(網卡)讀取到內核緩沖區;kernel的數據復制是將數據從內核緩沖區拷貝到用戶程序空間的緩沖區。
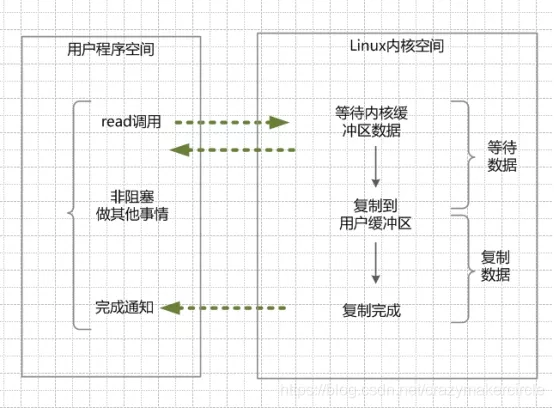
在這里插入圖片描述
(1) 當用戶線程調用了read系統調用,立刻就可以開始去做其它的事,用戶線程不阻塞。
(2) 內核(kernel)就開始了IO的第一個階段:準備數據。當kernel一直等到數據準備好了,它就會將數據從kernel內核緩沖區,拷貝到用戶緩沖區(用戶內存)。
(3) kernel會給用戶線程發送一個信號(signal),或者回調用戶線程注冊的回調接口,告訴用戶線程read操作完成了。
(4) 用戶線程讀取用戶緩沖區的數據,完成后續的業務操作。
異步IO模型的特點:
- 在內核kernel的等待數據和復制數據的兩個階段,用戶線程都不是block(阻塞)的。用戶線程需要接受kernel的IO操作完成的事件,或者說注冊IO操作完成的回調函數,到操作系統的內核。所以說,異步IO有的時候,也叫做信號驅動 IO 。
異步IO模型缺點:
- 需要完成事件的注冊與傳遞,這里邊需要底層操作系統提供大量的支持,去做大量的工作。
目前來說, Windows 系統下通過 IOCP 實現了真正的異步 I/O。但是,就目前的業界形式來說,Windows 系統,很少作為百萬級以上或者說高并發應用的服務器操作系統來使用。
而在 Linux 系統下,異步IO模型在2.6版本才引入,目前并不完善。所以,這也是在 Linux 下,實現高并發網絡編程時都是以 IO 復用模型模式為主。
小結一下:
四種IO模型,理論上越往后,阻塞越少,效率也是最優。在這四種 I/O 模型中,前三種屬于同步 I/O,因為其中真正的 I/O 操作將阻塞線程。只有最后一種,才是真正的異步 I/O 模型,可惜目前Linux 操作系統尚欠完善。


















