













“非深度網絡”12層打敗50層,普林斯頓+英特爾:更深不一定更好
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
“深度”是深度神經網絡(DNN)的關鍵詞。但網絡越深也就意味著,訓練時反向傳播的鏈條更長,推理時順序計算步驟更多、延遲更高。
而深度如果不夠,神經網絡的性能往往又不好。
這就引出了一個問題:是否有可能構建高性能的“非深度”神經網絡?
普林斯頓大學和英特爾最新的論文證明,確實能做到。
他們只用了12層網絡ParNet就在ImageNet上達到了接近SOTA的性能。
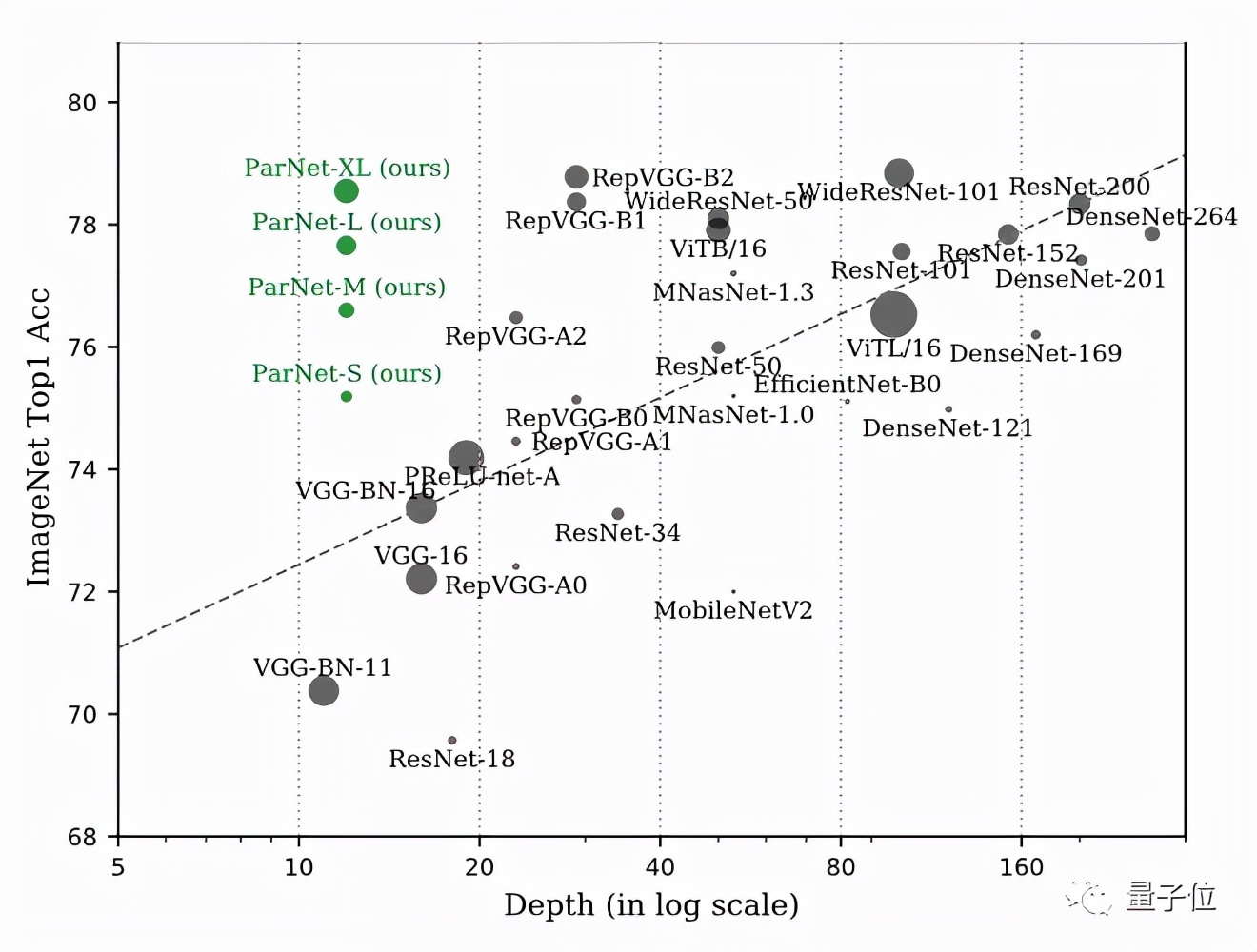
ParNet在ImageNet上準確率超過80%、在CIFAR10上超過 96%、在CIFAR100上top-1準確率 達到了81%,另外在MS-COCO上實現了48%的AP。
他們是如何在網絡這么“淺”的情況下做到的?
并行子網提升性能
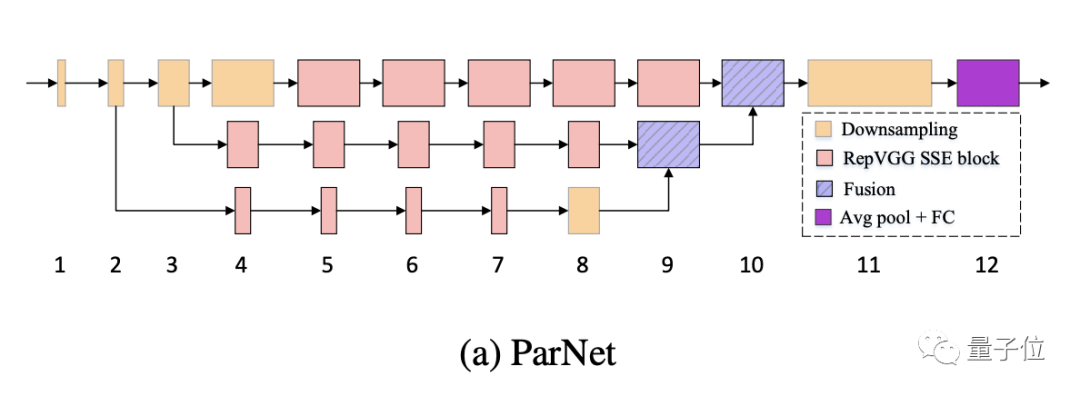
ParNet 中的一個關鍵設計選擇是使用并行子網,不是按順序排列層,而是在并行子網中排列層。
ParNet由處理不同分辨率特征的并行子結構組成。我們將這些并行子結構稱為流(stream)。來自不同流的特征在網絡的后期融合,這些融合的特征用于下游任務。
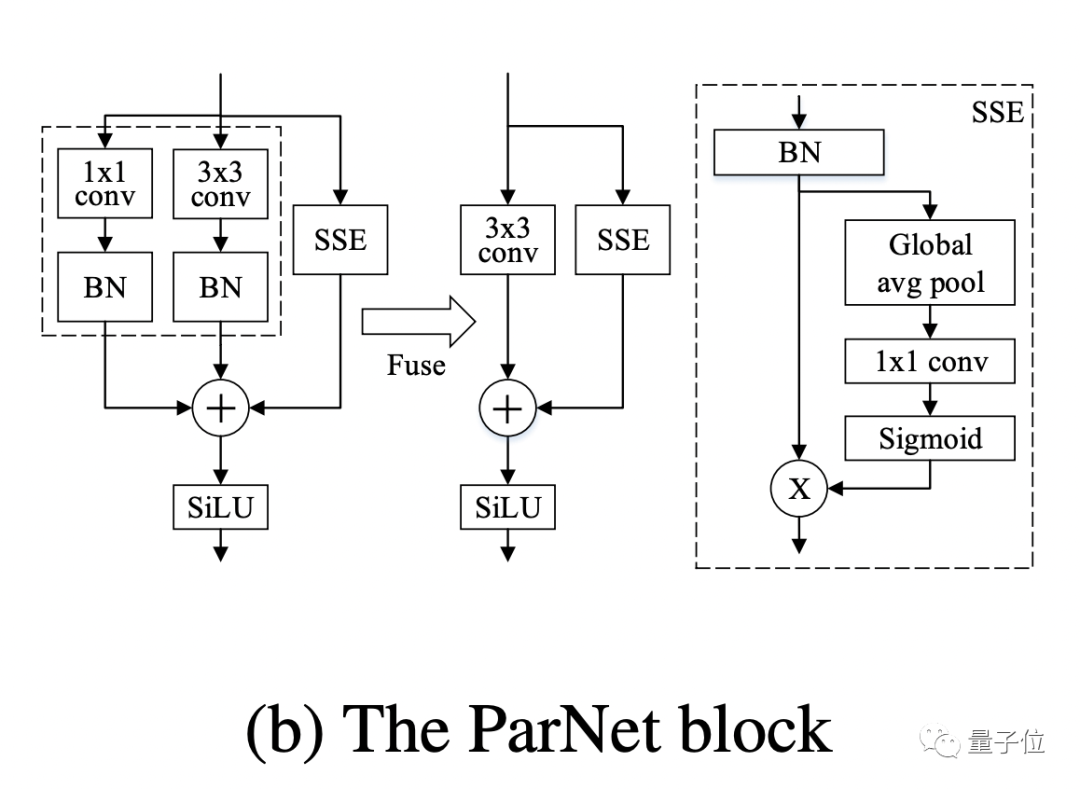
在 ParNet 中,作者使用VGG樣式的塊。但是對于非深度網絡來說,只有3×3卷積感受野比較有限。
為了解決這個問題,作者構建了一個基于Squeeze-and-Excitation設計的 Skip-Squeeze-Excitation (SSE) 層。使用SSE模塊修改后的Rep-VGG稱之為Rep VGG-SSE。
對于ImageNet等大規模數據集,非深度網絡可能沒有足夠的非線性,從而限制了其表示能力。因此,作者用SiLU激活函數替代了ReLU。
除了RepVGG-SSE塊的輸入和輸出具有相同的大小外,ParNet還包含下采樣和融合塊。
模塊降低分辨率并增加寬度以實現多尺度處理,而融合塊組合來自多個分辨率的信息,有助于減少推理期間的延遲。
為了在小深度下實現高性能,作者通過增加寬度、分辨率和流數量來擴展ParNet。
作者表示,由于摩爾定律放緩,處理器頻率提升空間也有限,因此并行計算有利于神經網絡實現更快的推理。而并行結構的非深度網絡ParNet在這方面具有優勢。
實際性能如何
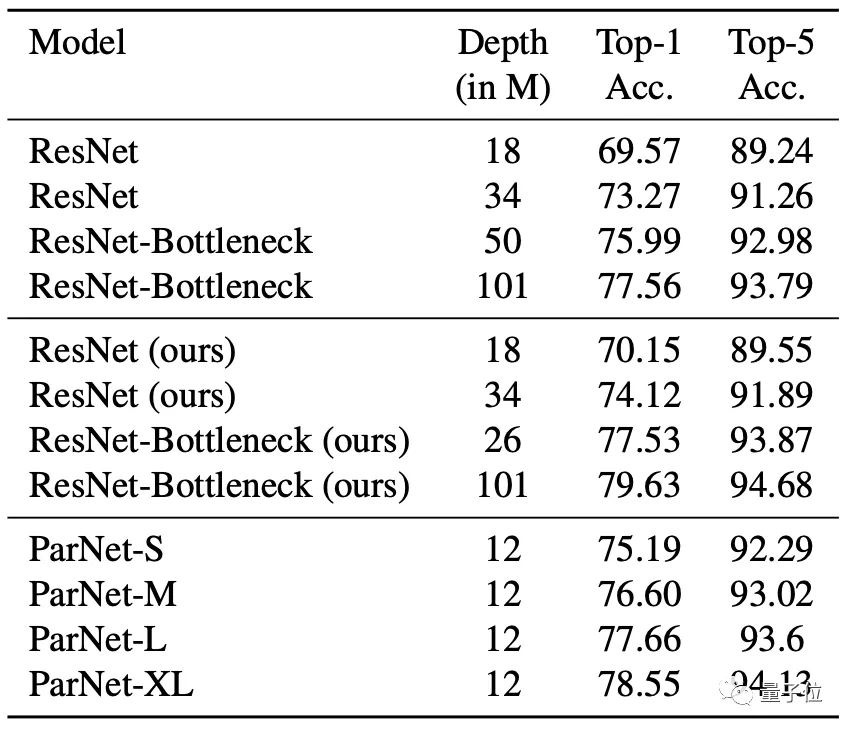
在ImageNet數據集上,無論是Top-1還是Top-5上,ParNet都接近SOTA性能。
在MS-COCO任務中,ParNet在性能最佳的同時,延遲最低。
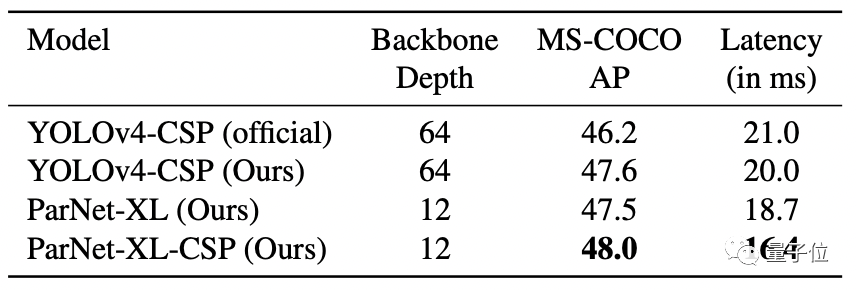
不過也有人質疑“非深度網絡”的實際表現,因為雖然層數少,但網絡寬度變大,實際上ParNet比更深的ResNet50的參數還要多,似乎不太有說服力。
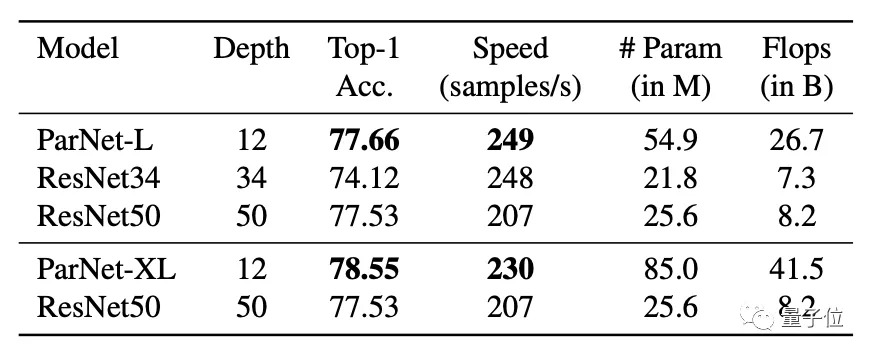
但作者也表示“非深度”網絡在多GPU下能發揮更大的并行計算優勢。
最后,ParNet的GitHub頁已經建立,代碼將在不久后開源。















