賭你看不懂:分布式存儲系統的數據強一致性挑戰
自從 Google 發布 Spanner 論文后,國內外相繼推出相關數據庫產品或服務來解決數據庫的可擴展問題。字節跳動在面對海量數據存儲需求時,也采用了相關技術方案。本次分享將介紹我們在構建此類系統中碰到的問題,解決方案以及技術演進。
一、背景
互聯網產品中存在很多種類的數據,不同種類的數據對于存儲系統的一致性,可用性,擴展性的要求是不同的。比如,金融、賬號相關的數據對一致性要求比較高,社交類數據例如點贊對可用性要求比較高。
還有一些大規模元數據存儲場景,例如對象存儲的索引層數據,對一致性,擴展性和可用性要求都比較高,這就需要底層存儲系統在能夠保證數據強一致的同時,也具有良好的擴展性。在數據模型上,有些數據比如關系,KV 模型足夠用;有些數據比如錢包、賬號可能又需要更豐富的數據模型,比如表格。
分布式存儲系統對數據分區一般有兩種方式:Hash 分區和 Range 分區。Hash 分區對每條數據算一個哈希值,映射到一個邏輯分區上,然后通過另外一層映射將邏輯分區映射到具體的機器上,很多數據庫中間件、緩存中間件都是這樣做的。這種方式的優點是數據寫入一般不會出現熱點,缺點是原本連續的數據經過 Hash 后散落在不同的分區上變成了無序的,那么,如果需要掃描一個范圍的數據,需要把所有的分區都掃描一遍。
相比而言,Range 分區對數據進行范圍分區,連續的數據是存儲在一起的,可以按需對相鄰的分區進行合并,或者中間切一刀將一個分區一分為二。業界典型的系統像 HBase。這種分區方式的缺點是一、對于追加寫處理不友好,因為請求都會打到最后一個分片,使得最后一個分片成為瓶頸。優點是更容易處理熱點問題,當一個分區過熱的時候,可以切分開,遷移到其他的空閑機器上。
從實際業務使用的角度來說,提供數據強一致性能夠大大減小業務的負擔。另外 Range 分區能夠支持更豐富的訪問模式,使用起來更加靈活。基于這些考慮,我們使用 C++ 自研了一套基于 Range 分區的強一致 KV 存儲系統 ByteKV,并在其上封裝一層表格接口以提供更為豐富的數據模型。
二、架構介紹
1、系統組件
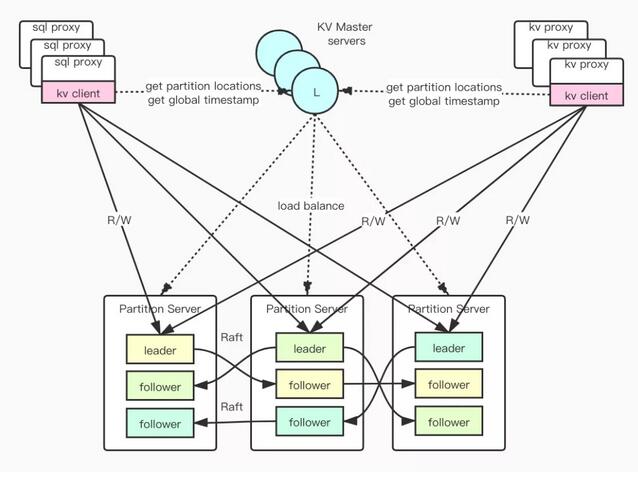
整個系統主要分為 5 個組件:SQLProxy, KVProxy, KVClient, KVMaster 和 PartitionServer。其中,SQLProxy 用于接入 SQL 請求,KVProxy 用于接入 KV 請求,他們都通過 KVClient 來訪問集群。KVClient 負責和 KVMaster、PartitionServer 交互,KVClient 從 KVMaster 獲取全局時間戳和副本位置等信息,然后訪問相應的 PartitionServer 進行數據讀寫。PartitionServer 負責存儲用戶數據,KVMaster 負責將整個集群的數據在 PartitionServer 之間調度。
集群中數據會按照 range 切分為很多 Partition,每個 Partition 有多個副本,副本之間通過 Raft 來保證一致性。這些副本分布在所有的 PartitionServer 中,每個 PartitionServer 會存儲多個 Partition 的副本,KVMaster 負責把所有副本均勻的放置在各個 PartitionServer 中。
各個 PartitionServer 會定期匯報自身存儲的副本的信息給 KVMaster,從而 KVMaster 有全局的副本位置信息。Proxy 接到 SDK 請求后,會訪問 KVMaster 拿到副本位置信息,然后將請求路由到具體的 PartitionServer,同時 Proxy 會緩存一部分副本位置信息以便于后續快速訪問。由于副本會在 PartitionServer 之間調度,故 Proxy 緩存的信息可能是過期的,這時當 PartitionServer 給 Proxy 回應副本位置已經變更后,Proxy 會重新向 KVMaster 請求副本位置信息。
2、分層結構
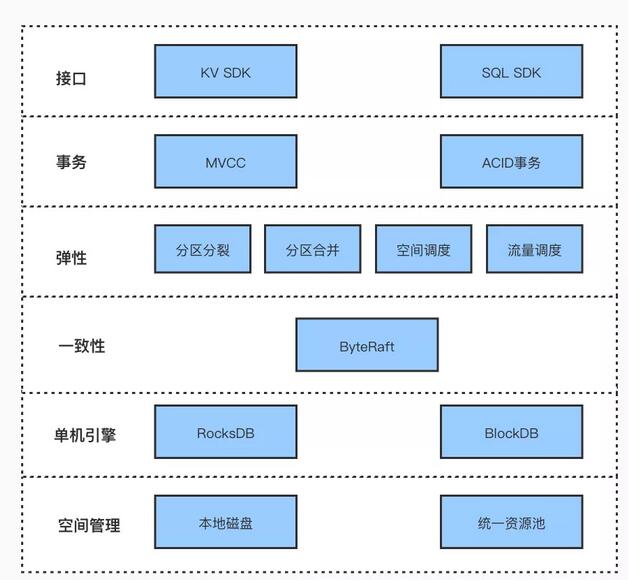
如上圖所示是 ByteKV 的分層結構。
接口層對用戶提供 KV SDK 和 SQL SDK,其中 KV SDK 提供簡單的 KV 接口,SQL SDK 提供更加豐富的 SQL 接口,滿足不同業務的需求。
事務層提供全局一致的快照隔離級別(Snapshot Isolation),通過全局時間戳和兩階段提交保證事務的 ACID 屬性。
彈性伸縮層通過 Partition 的自動分裂合并以及 KVMaster 的多種調度策略,提供了很強的水平擴展能力,能夠適應業務不同時期的資源需求。
一致性協議層通過自研的 ByteRaft 組件,保證數據的強一致性,并且提供多種部署方案,適應不同的資源分布情況。
存儲引擎層采用業界成熟的解決方案 RocksDB,滿足前期快速迭代的需求。并且結合系統未來的演進需要,設計了自研的專用存儲引擎 BlockDB。
空間管理層負責管理系統的存儲空間,數據既可以存儲在物理機的本地磁盤,也可以接入其他的共享存儲進行統一管理。
三、對外接口
1、KV 接口
ByteKV 對外提供兩層抽象,首先是 namespace,其次是 table,一個 namespace 可以有多個 table。具體到一個 table,支持單條記錄的 Put、Delete 和 Get 語義。其中 Put 支持 CAS 語義,僅在滿足某種條件時才寫入這條記錄,如僅在當前 key 不存在的情況下才寫入這條記錄,或者僅在當前記錄為某個版本的情況下才寫入這條記錄等,同時還支持 TTL 語義。Delete 也類似。
除了這些基本的接口外,還提供多條記錄的原子性寫入接口 WriteBatch, 分布式一致性快照讀 MultiGet, 非事務性寫入 MultiWrite 以及掃描一段區間的數據 Scan 等高級接口。WriteBatch 可以提供原子性保證,即所有寫入要么全部成功要么全部失敗,而 MultiWrite 不提供原子性保證,能寫成功多少寫成功多少。
MultiGet 提供的是分布式一致性快照讀的語義:MultiGet 不會讀到其他已提交事務的部分修改。Scan 也實現了一致性快照讀的語義,并且支持了前綴掃描,逆序掃描等功能。
2、表格接口
表格接口在 KV 的基礎上提供了更加豐富的單表操作語義。用戶可以使用基本的 Insert,Update,Delete,Select SQL 語句來讀寫數據,可以在 Query 中使用過濾(Where/Having)排序(OrderBy),分組(GroupBy),聚合(Count/Max/Min/Avg)等子句。同時在 SDK 端我們也提供了 ORM 庫,方便用戶的業務邏輯實現。
四、關鍵技術
1、自研 ByteRaft
作為一款分布式系統,容災能力是不可或缺的。冗余副本是最有效的容災方式,但是它涉及到多個副本間的一致性問題。
ByteKV 采用 Raft[1]作為底層復制算法來維護多個副本間的一致性。由于 ByteKV 采用 Range 分片,每個分片對應一個 Raft 復制組,一個集群中會存在非常多的 Raft Group。組織、協調好 Raft Group 組之間的資源利用關系,對實現一個高性能的存儲系統至關重要;同時在正確實現 Raft 算法基礎上,靈活地為上層提供技術支持,能夠有效降低設計難度。因此我們在參考了業界優秀實現的基礎上,開發了一款 C++ 的 Multi-Raft 算法庫 ByteRaft。
日志復制是 Raft 算法的最基本能力,ByteKV 將所有用戶寫入操作編碼成 RedoLog,并通過 Raft Leader 同步給所有副本;每個副本通過回放具有相同序列的 RedoLog,保證了一致性。有時服務 ByteKV 的機器可能因為硬件故障、掉電等原因發生宕機,只要集群中仍然有多數副本存活,Raft 算法就能在短時間內自動發起選舉,選出新的 Leader 進行服務。最重要的是,動態成員變更也被 Raft 算法所支持,它為 ByteKV 的副本調度提供了基礎支持。ByteKV 的 KVMaster 會對集群中不同機器的資源利用率進行統計匯總,并通過加減副本的方式,實現了數據的遷移和負載均衡;此外,KVMaster 還定期檢查機器狀態,將長時間宕機的副本,從原有的復制組中摘除。
ByteRaft 在原有 Raft 算法的基礎上,做了很多的工程優化。如何有效整合不同 Raft Group 之間的資源利用,是實現有效的 Multi-Raft 算法的關鍵。ByteRaft 在各種 IO 操作路徑上做了請求合并,將小粒度的 IO 請求合并為大塊的請求,使其開銷與單 Raft Group 無異;同時多個 Raft Group 可以橫向擴展,以充分利用 CPU 的計算和 IO 帶寬資源。ByteRaft 網絡采用 Pipeline 模式,只要網絡通暢,就按照最大的能力進行日志復制;同時 ByteRaft 內置了亂序隊列,以解決網絡、RPC 框架不保證數據包順序的問題。ByteRaft 會將即將用到的日志都保留在內存中,這個特性能夠減少非常多不必要的 IO 開銷,同時降低同步延遲。
ByteRaft 不單單作為一個共識算法庫,還提供了一整套的解決方案,方便各類場景快速接入,因此除了 ByteKV 使用外,還被字節內部的多個存儲系統使用。
除了上述功能外,ByteRaft 還為一些其他企業場景提供了技術支持。
1)Learner
數據同步是存儲系統不可或缺的能力。ByteKV 提供了一款事務粒度的數據訂閱方案。這種方案保證數據訂閱按事務的提交順序產生,但不可避免的導致擴展性受限。在字節內部,部分場景的數據同步并不需要這么強的日志順序保證,為此 ByteRaft 提供了 Learner 支持,我們在 Learner 的基礎上設計了一款松散的按 Key 有序復制的同步組件。
同時,由于 Learner 不參與日志提交的特性,允許一個新的成員作為 Learner 加入 Raft Group,等到日志差距不大時再提升為正常的跟隨者。這個過程可以使得 KVMaster 的調度過程更為平滑,不會降低集群可用性。
2)Witness
在字節內部,ByteKV 的主要部署場景為三中心五副本,這樣能夠保證在單機房故障時集群仍然能夠提供服務,但是這種方式對機器數量要求比較大,另外有些業務場景只能提供兩機房部署。因此需要一種不降低集群可用性的方案來降低成本。Witness 作為一個只投票不保存數據的成員,它對機器的資源需求較小,因此 ByteRaft 提供了 Witness 功能。
有了 Witness,就可以將傳統的五副本部署場景中的一個副本替換為 Witness,在沒有降低可用性的同時,節省出了部分機器資源。另外一些只有兩機房的場景中,也可以通過租用少量的第三方云服務,部署上 Witness 來提供和三中心五副本對等的容災能力。更極端的例子場景,比如業務有主備機房的場景下,可以通過增加 Witness 改變多數派在主備機房的分布情況,如果主備機房隔離,少數派的機房可以移除 Witness 降低 quorum 數目從而恢復服務。
2、存儲引擎
1)RocksDB
和目前大多數存儲系統一樣,我們也采用 RocksDB 作為單機存儲引擎。RocksDB 作為一個通用的存儲引擎,提供了不錯的性能和穩定性。RocksDB 除了提供基礎的讀寫接口以外,還提供了豐富的選項和功能,以滿足各種各樣的業務場景。然而在實際生產實踐中,要把 RocksDB 用好也不是一件簡單的事情,所以這里我們給大家分享一些經驗。
①Table Properties
Table Properties 是我們用得比較多的一個功能。RocksDB 本身提供一些內置的 SST 統計信息,并且支持用戶自定義的 Table Properties Collector,用于在 Flush/Compaction 過程中收集統計信息。具體來說,我們利用 Table Properties 解決了以下幾個問題:
- 我們的系統是采用 Range 切分數據的,當一個 Range 的數據大小超過某個閾值,這個 Range 會被分裂。這里就涉及到分裂點如何選取的問題。一個簡單的辦法是把這個 Range 的數據掃一遍,根據數據大小找到一個中點作為分裂點,但是這樣 IO 開銷會比較大。所以我們通過 Table Properties Collector 對數據進行采樣,每隔一定的數據條數或者大小記錄一個采樣點,那么分裂的時候只需要根據這些采樣點來估算出一個分裂點即可。
- 多版本數據進行啟發式垃圾回收的過程,也是通過 Table Properties 的采樣來實現的。在存儲引擎中,一條用戶數據可能對應有一條或多條不同版本的數據。我們在 Table Properties Collector 中采集了版本數據的條數和用戶數據的條數。在垃圾回收的過程中,如果一個 Range 包含的版本數據的條數和用戶數據的條數差不多,我們可以認為大部分用戶數據只有一個版本,那么就可以選擇跳過這個 Range 的垃圾回收。另外,垃圾回收除了要考慮多版本以外,還需要考慮 TTL 的問題,那么在不掃描數據的情況下如何知道一個 Range 是否包含已經過期的 TTL 數據呢?同樣是在 Table Properties Collector 中,我們計算出每條數據的過期時間,然后以百分比的形式記錄不同過期時間的數據條數。那么,在垃圾回收的過程中,給定一個時間戳,我們就能夠估算出某一個 Range 里面包含了多少已經過期的數據了。
- 雖然 RocksDB 提供了一些參數能夠讓我們根據不同的業務場景對 compaction 的策略進行調整,比如 compaction 的優先級等,但是實際上業務類型多種多樣,很難通過一套單一的配置能夠滿足所有的場景。這時候其實我們也可以根據統計信息來對 compaction 進行一定的“干預”。比方說有的數據區間經常有頻繁的刪除操作,會留下大量的 tombstone。如果這些 tombstone 不能被快速的 compaction 清除掉,會對讀性能造成很大,并且相應的空間也不能釋放。針對這個問題,我們會在上層根據統計信息(比如垃圾數據比例)及時發現并主動觸發 compaction 來及時處理。
②遇到的問題和解決辦法
除了上面提到的幾個用法以外,這里我們再給大家分享 RocksDB 使用過程中可能遇到的一些坑和解決辦法:
- 你是否遇到過數據越刪越多或者已經刪除了很多數據但是空間長時間不能釋放的問題呢?我們知道 RocksDB 的刪除操作其實只是寫入了一個 tombstone 標記,而這個標記往往只有被 compact 到最底層才能被丟掉的。所以這里的問題很可能是由于層數過多或者每一層之間的放大系數不合理導致上面的層的 tombstone 不能被推到最底層。這時候大家可以考慮開啟 level_compaction_dynamic_level_bytes這個參數來解決。
- 你是否遇到過 iterator 的抖動導致的長尾問題呢?這個可能是因為 iterator 在釋放的時候需要做一些清理工作的原因,嘗試開啟 avoid_unnecessary_blocking_io 來解決。
- 你是否遇到過 ingest file 導致的抖動問題?在 ingest file 的過程中,RocksDB 會阻塞寫入,所以如果 ingest file 的某些步驟耗時很長就會帶來明顯的抖動。例如如果 ingest 的 SST 文件跟 memtable 有重疊,則需要先把 memtable flush 下來,而這個過程中都是不能寫入的。所以為了避免這個抖動問題,我們會先判斷需要 ingest 的文件是否跟 memtable 有重疊,如果有的話會在 ingest 之前先 flush,等 flush 完了再執行 ingest。而這個時候 ingest 之前的 flush 并不會阻塞寫,所以也就避免了抖動問題。
- 你是否遇到過某一層的一個文件跟下一層的一萬個文件進行 compaction 的情況呢?RocksDB 在 compaction 生成文件的時候會預先判斷這個文件跟下一層有多少重疊,來避免后續會產生過大的 compaction 的問題。然而,這個判斷對 range deletion 是不生效的,所以有可能會生成一個范圍非常廣但是實際數據很少的文件,那么這個文件再跟下一層 compact 的時候就會涉及到非常多的文件,這種 compaction 可能需要持續幾個小時,期間所有文件都不能被釋放,磁盤很容易就滿了。由于我們需要 delete range 的場景很有限,所以目前我們通過 delete files in range + scan + delete 的方式來替換 delete range。雖然這種方式比 delete range 開銷更大,但是更加可控。雖然也可以通過 compaction filter 來進一步優化,但是實現比較復雜,我們暫時沒有考慮。
由于篇幅有限,上面只是提了幾個可能大家都會遇到的問題和解決辦法。這些與其說是使用技巧,還不如說是“無奈之舉”。很多問題是因為 RocksDB 是這么實現的,所以我們只能這么用,即使給 RocksDB 做優化往往也只能是一些局部調整,畢竟 RocksDB 是一個通用的存儲引擎,而不是給我們系統專用的。因此,考慮到以后整個系統的演進的需要,我們設計了一個專用的存儲引擎 BlockDB。
2)BlockDB
①功能需求
BlockDB 需要解決的一個核心需求是數據分片。我們每個存儲節點會存儲幾千上萬個數據分片,目前這些單節點的所有分片都是存儲在一個 RocksDB 實例上的。這樣的存儲方式存在以下缺點:
- 無法對不同數據分片的資源使用進行隔離,這一點對于多租戶的支持尤為重要。
- 無法針對不同數據分片的訪問模式做優化,比如有的分片讀多寫少,有的分片寫多讀少,那么我們希望對前者采取對讀更加友好的 compaction 策略,而對后者采取對寫更加友好的 compaction 策略,但是一個 RocksDB 實例上我們只能選擇一種單一的策略。
- 不同數據分片的操作容易互相影響,一些對數據分片的操作在 RocksDB 中需要加全局鎖(比如上面提到的 ingest file),那么數據分片越多鎖競爭就會越激烈,容易帶來長尾問題。
- 不同數據分片混合存儲會帶來一些不必要的寫放大,因為我們不同業務的數據分片是按照前綴來區分的,不同數據分片的前綴差別很大,導致寫入的數據范圍比較離散,compaction 的過程中會有很多范圍重疊的數據。
雖然 RocksDB 的 Column Family 也能夠提供一部分的數據切分能力,但是面對成千上萬的數據分片也顯得力不從心。而且我們的數據分片還需要支持一些特殊的操作,比如分片之間的分裂合并等。因此,BlockDB 首先會支持數據分片,并且在數據分片之上增加資源控制和自適應 compaction 等功能。
除了數據分片以外,我們還希望減少事務的開銷。目前事務數據的存儲方式相當于在 RocksDB 的多版本之上再增加了一層多版本。RocksDB 內部通過 sequence 來區分不同版本的數據,然后在 compaction 的時候根據 snapshot sequence 來清除不可見的垃圾數據。我們的事務在 RocksDB 之上通過 timestamp 來區分不同版本的用戶數據,然后通過 GC 來回收對用戶不可見的垃圾數據。這兩者的邏輯是非常相似的,目前的存儲方式顯然存在一定的冗余。因此,我們會把一部分事務的邏輯下推到 BlockDB 中,一方面可以減少冗余,另一方面也方便在引擎層做進一步的優化。
采用多版本并發控制的存儲系統有一個共同的痛點,就是頻繁的更新操作會導致用戶數據的版本數很多,范圍查找的時候需要把每一條用戶數據的所有版本都掃一遍,對讀性能帶來很大的影響。實際上,大部分的讀請求只會讀最新的若干個版本的數據,如果我們在存儲層把新舊版本分離開來,就能夠大大提升這些讀請求的性能。所以我們在 BlockDB 中也針對這個問題做了設計。
②性能需求
除了功能需求以外,BlockDB 還希望進一步發揮高性能 SSD(如 NVMe)隨機 IO 的特性,降低成本。RocksDB 的數據是以文件單位進行存儲的,所以 compaction 的最小單位也是文件。如果一個文件跟下一層完全沒有重疊,compaction 可以直接把這個文件 move 到下一層,不會產生額外的 IO 開銷。可以想象,如果一個文件越小,那么這個文件跟下一層重疊的概率也越小,能夠直接復用這個文件的概率就越大。
但是在實際使用中,我們并不能把文件設置得特別小,因為文件太多對文件系統并不友好。基于這一想法,我們在 BlockDB 中把數據切分成 Block 進行存儲,而 Block 的粒度比文件小得多,比如 128KB。這里的 Block 可以類比為 SST 文件里的 Block,只是我們把 SST 文件的 Block 切分開來,使得這些 Block 能夠單獨被復用。但是以 Block 為單位進行存儲對范圍掃描可能不太友好,因為同一個范圍的數據可能會分散在磁盤的各個地方,掃描的時候需要大量的隨機讀。不過在實際測試中,只要控制 Block 的粒度不要太小,配合上異步 IO 的優化,隨機讀依然能夠充分發揮磁盤的性能。
另外,為了進一步發揮磁盤性能,減少文件系統的開銷,BlockDB 還設計了一個 Block System 用于 Block 的存儲。Block System 類似于一個輕量級的文件系統,但是是以 Block 為單位進行數據存儲的。Block System 既可以基于現有的文件系統來實現,也可以直接基于裸盤來實現,這一設計為將來接入 SPDK 和進一步優化 IO 路徑提供了良好的基礎。
3、分布式事務
前面在介紹接口部分時,提到了 ByteKV 原子性的 WriteBatch 和滿足分布式一致性快照讀的 MultiGet。WriteBatch 意味著 Batch 內的所有修改要么都成功,要么都失敗,不會出現部分成功部分失敗的情況。MultiGet 意味著不會讀取到其他已提交事務的部分數據。
ByteKV 大致采用了以下幾種技術來實現分布式事務:
- 集群提供一個全局遞增的邏輯時鐘,每個讀寫請求都通過該模塊分配一個時間戳,從而給所有請求都分配一個全局的順序。
- 一個 Key 的每次更新都在系統中產生一個新的版本,保證新的寫入不會影響到舊的讀的快照。
- 在寫請求的流程中引入兩階段提交,保證寫入可以有序、原子性的提交。
1)全局授時服務
毫無疑問,給所有的事件定序,能讓分布式系統中的很多問題都得以簡化。我們也總是見到各種系統在各種各樣的物理時鐘、邏輯時鐘、混合邏輯時鐘中取舍。ByteKV 從性能、穩定性和實現難度的角度綜合考慮,在 KVMaster 服務中實現了一個提供全局遞增時間戳分配的接口,供集群所有的讀寫模塊使用,該接口保證吐出的時間戳是全局唯一且遞增的。
之所以采用這樣的架構,是因為我們覺得:
- 時鐘分配的邏輯非常簡單,即便是由一個單機模塊來提供,也能得到穩定的延時和足夠的吞吐。
- 我們可以使用 Raft 協議來實現時鐘分配模塊的高可用,單機的失敗絕不會成為系統的單點。
在具體實現上,為了保證時鐘的穩定、高效和易用,我們也做了一些工程上的努力和優化:
- 同一個客戶端拿時鐘的邏輯是有 Batch 的,這樣可以有效減少 RPC 的次數。
- 時鐘的分配要用獨立的 TCP Socket,避免受到其他的 RPC 請求的干擾。
- 時鐘的分配用原子操作,完全規避鎖的使用。
- 時鐘要盡量接近真實的物理時間,非常有利于一些問題的調試。
2)多版本
幾乎所有的現代數據庫系統都會采用多版本機制來作為事務并發控制機制的一部分,ByteKV 也不例外。多版本的好處是讀寫互不阻塞。對一行的每次寫入都會產生一個新的版本,而讀取通常是讀一個已經存在的版本。邏輯上的數據組織如下:
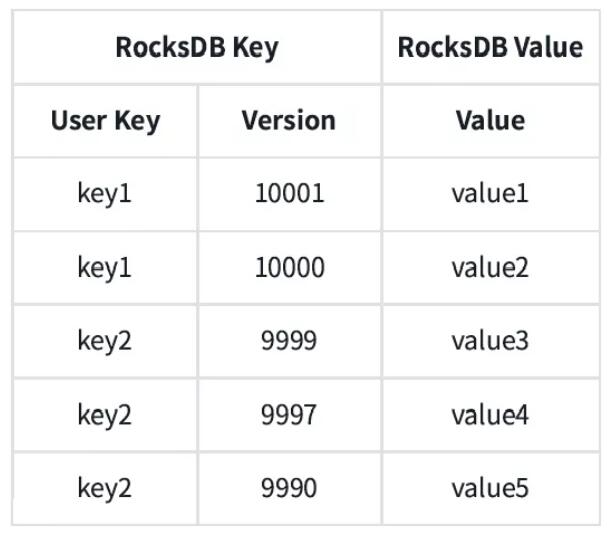
相同的 Key 的多個版本會連續存儲在一起,方便具體版本的定位,同時版本降序排列以減少查詢的開銷。
為了保證編碼后的數據能夠按我們期望的方式排序,對 RocksDB Key 我們采用了內存可比較編碼[2],這里之所以沒有自定義 RocksDB 的 compare 函數,是因為:
- Key 比較大小是在引擎讀寫中非常高頻的,而默認的 memcmp 對性能非常友好。
- 減少對 RocksDB 的特殊依賴,提高架構的靈活性。
- 為了避免同一個 Key 的多個版本持續堆積而導致空間無限膨脹,ByteKV 有一個后臺任務定期會對舊版本、已標記刪除的數據進行清理。在上篇中,存儲引擎章節做了一些介紹。
3)兩階段提交
ByteKV 使用兩階段提交來實現分布式事務,其大致思想是整個過程分為兩個階段:第一個階段叫做 Prepare 階段,這個階段里協調者負責給參與者發送 Prepare 請求,參與者響應請求并分配資源、進行預提交(預提交數據我們叫做 Write Intent);第一個階段中的所有參與者都執行成功后,協調者開始第二個階段即 Commit 階段,這個階段協調者提交事務,并給所有參與者發送提交命令,參與者響應請求后把 Write Intent 轉換為真實數據。
在 ByteKV 里,協調者由 KVClient 擔任,參與者是所有 PartitionServer。接下來我們從原子性和隔離性角度來看看 ByteKV 分布式事務實現的一些細節。
①首先是如何保證事務原子性對外可見?
這個問題本質上是需要有持久化的事務狀態,并且事務狀態可以被原子地修改。業界有很多種解法,ByteKV 采用的方法是把事務的狀態當作普通數據,單獨保存在一個內部表中。我們稱這張表為事務狀態表,和其他業務數據一樣,它也分布式地存儲在多臺機器上。事務狀態表包括如下信息:
- 事務狀態:包括事務已開始,已提交,已回滾等狀態。事務狀態本身就是一個 KV,很容易做到原子性。
- 事務版本號:事務提交時,從全局遞增時鐘拿到的時間戳,這個版本號會被編碼進事務修改的所有 Key 中。
- 事務 TTL:事務的超時時間,主要為了解決事務夯死,一直占住資源的情況。其他事務訪問到該事務修改的資源時,如果發現該事務已超時,可以強行殺死該事務。
在事務狀態表的輔助下,第二階段中協調者只需要簡單地修改事務狀態就能完成事務提交、回滾操作。一旦事務狀態修改完成,即可響應客戶端成功, Write Intent 的提交和清理操作則是異步地進行。
②第二個問題是如何保證事務間的隔離和沖突處理?
ByteKV 會對執行中的事務按照先到先得的原則進行排序,后到的事務讀取到 Write Intent 后進行等待,直到之前的事務結束并清理掉 Write Intent 。Write Intent 對于讀請求不可見,如果 Write Intent 指向的事務 Prepare 時間大于讀事務時間,那么 Write Intent 會被忽略;否則讀請求需要等待之前的事務完成或回滾,才能知道這條數據是否可讀。
等待事務提交可能會影響讀請求的延遲,一種簡單的優化方式是讀請求將還未提交的事務的提交時間戳推移到讀事務的時間戳之后。前面說了這么多 Write Intent,那么 Write Intent 到底是如何編碼的使得處于事務運行中還沒有提交的數據無法被其他事務讀到?這里也比較簡單,只需要把 Write Intent 的版本號設置為無窮大即可。
除了上述問題外,分布式事務需要解決容錯的問題。這里只討論協調者故障的場景,協調者故障后事務可能處于已經提交狀態,也可能處于未提交狀態;部分 PartitionServer 中的 Write Intent 可能已經提交或清理,也可能還保留在那里。
如果事務已經提交,隨后的讀寫事務碰到遺留的 Write Intent 時,會根據事務狀態表中的狀態來輔助之前的事務提交或清理 Write Intent;如果事務還未提交,后續事務會在之前的事務超時(事務 TTL)后修改事務狀態為已回滾,并異步地清理 Write Intent。
由于 Write Intent 本身也包含著事務的相關信息,如果我們把參與者列表也記錄在 Write Intent 中,就可以把事務提交的標志從原子的修改完事務狀態修改為所有 Write Intent 都完成持久化,從而降低一次提交延遲;而后續的操作碰到 Write Intent 后可以根據參與者列表還原出事務狀態。
4、分區自動分裂和合并
前面提到 ByteKV 采用 Range 分區的方式提供擴展性,這種分區方式帶來的一個問題是:隨著業務發展,原有的分區結構不再適用于新的業務模式。比如業務寫入熱點變化,熱點從一個分區漂移到另一個分區。為了解決這個問題,ByteKV 實現了自動分裂的功能:通過對用戶寫入進行采樣,當數據量超過一定閾值后,從中間將 Range 切分為兩個新的 Range。分裂功能配合上調度,提供了自動擴展的能力。
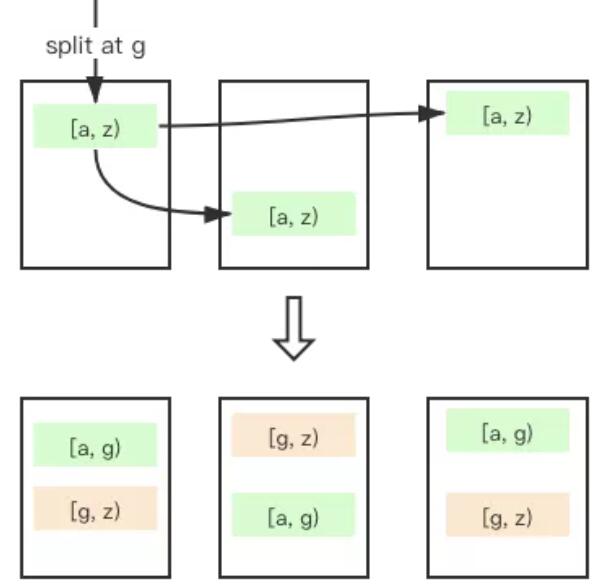
ByteKV 實現的分裂過程比較簡單,當某個 Range 發現自己已經達到分裂條件,便向 KVMaster 申請執行一次分裂并拿到新分區的相關元信息,然后在 Range 內部執行分裂操作。分裂命令和普通的操作一樣,作為一條日志,發送給本 Range 的 Raft Leader;當日志提交后,狀態機根據日志攜帶的信息,在原地拉起一個新的 Raft 副本,這些新副本共同服務分裂后的一半分區,原來的副本服務另一半分區。
在另外一些場景,比如大量的 TTL,大量的先寫后刪,會自動地分裂出大量的分區。當 TTL 過期、數據被 GC 后,這些分裂出來的分區就形成了大量的數據碎片:每個 Raft Group 只服務少量的數據。這些小分區會造成無意義的開銷,同時維護它們的元信息也增加了 KVMaster 的負擔。針對這種情況,ByteKV 實現了自動合并功能,將一些較小的區間和與之相鄰的區間合并。
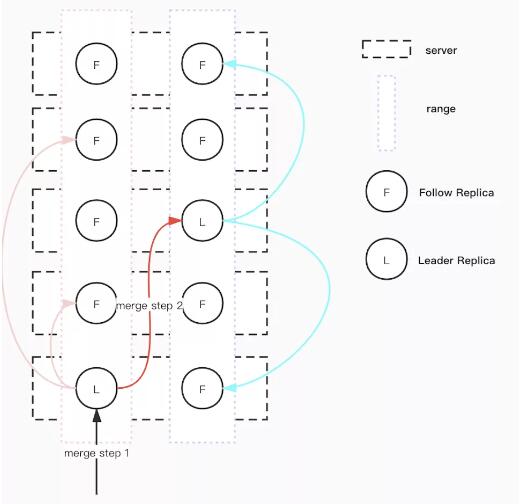
合并的過程比分裂復雜,master 將待合并的兩個相鄰區間調度到一塊,然后發起一次合并操作。如上圖所示,這個過程分為兩步:首先左區間發起一次操作,拿到一個同步點,然后在右區間發起合并操作;右區間會進行等待,只要當前 Server 中左區間同步點前的數據都同步完成,就能夠安全地修改左右區間的元信息,完成合并操作。
5、負載均衡
負載均衡是所有分布式系統都需要的重要能力之一。無法做到負載均衡的系統不僅不能充分利用集群的計算和存儲資源,更會因為個別節點因負載過重產生抖動進而影響服務質量。設計一個好的負載均衡策略會面對兩個難點,一是需要均衡的資源維度很多,不僅有最基本的磁盤空間,還有 CPU、IO、網絡帶寬、內存空間等,二是在字節跳動內部,機器規格非常多樣,同一個集群內的不同節點,CPU、磁盤、內存都可能不同。我們在設計負載均衡策略時采取了循序漸進的辦法,首先只考慮單一維度同構機型的場景,然后擴展到多個維度異構機型。下面介紹一下策略的演進過程。
1)單維度調度策略
以磁盤空間單一維度為例,并假設所有節點的磁盤容量完全相同。每個節點的磁盤空間使用量等于這個節點上所有副本的數據量之和。將所有副本一一分配并放置在某一個節點上就形成了一個副本分配方案。一定有一個方案,各節點的數據量的方差值最低,這種狀態我們稱之為“絕對均衡”。
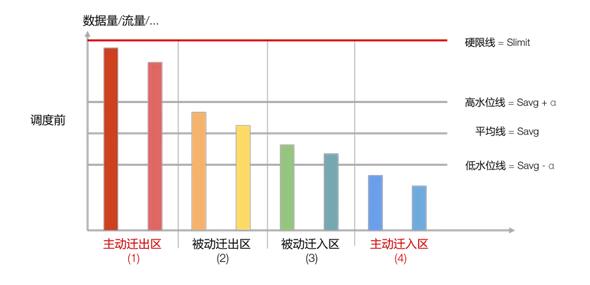
隨著數據的持續寫入,節點的數據量也會持續發生變化,如果要讓集群始終保持“絕對均衡”狀態,就需要不斷的進行調度,帶來大量的數據遷移開銷。不僅如此,某個維度的絕對均衡會使得其它維度的絕對均衡無法實現。從成本和可行性的角度,我們定義了一種更弱的均衡狀態,稱之為“足夠均衡”,它放松了均衡的標準,一方面降低了調度的敏感度,少量的數據量變化不會引起頻繁調度,另一方面也讓多個維度同時達到這種弱均衡狀態成為可能。為了直觀表達“足夠均衡”的定義,我們畫這樣一個示意圖進行說明:
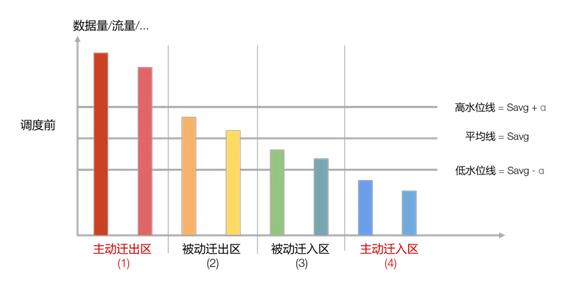
- 每個節點是一根柱子,柱子的高度是它的數據量,所有節點由高到低依次排列
- 計算出所有節點的平均數據量 Savg,并畫一條橫線,叫做平均線
- 平均數據量分別加、減一個 alpha 值得到高水位值和低水位值,alpha 可以取 Savg 的 10%或 20%,它決定了均衡的松緊程度,根據水位值畫出高水位線和低水位線
根據節點數據量與三條線的關系,將它們劃分為四個區:
- 高負載區/主動遷出區:節點數據量高于高水位值
- 高均衡區/被動遷出區:節點數據量低于高水位值且高于平均值
- 低均衡區/被動遷入區:節點數據量高于低水位值且低于平均值
- 低負載區/主動遷入區:節點數據量低于低水位值
當節點位于高負載區時,需要主動遷出副本,目標節點位于遷入區;當節點位于低負載區時,需要主動遷入副本,來源節點是遷出區
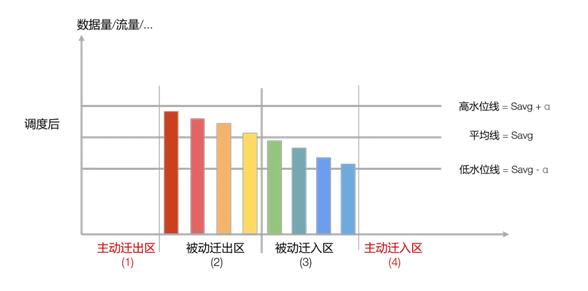
當所有節點都位于兩個均衡區時,集群達到“足夠均衡”狀態,下面這個圖就是一種“足夠均衡”狀態
2)多維度調度策略
以前面的單維度調度為基礎,多維度調度的目標是使集群在多個維度上同時或盡量多地達到足夠均衡的狀態。
我們先想象一下,每個維度都有前面提到的示意圖表示它的均衡狀態,N 個維度就存在 N 個圖。當一個副本發生遷移的時候,會同時改變所有維度的均衡狀態,也就是說所有的示意圖都會發生改變。
如果所有維度都變得更加均衡(均衡區的節點數變多了),或者一部分維度更均衡而另一部分維度不變(均衡區的節點數不變),那么這個遷移是一個好的調度;反正,如果所有維度都變得更加不均衡(均衡區的節點數變少了),或者一部分維度更不均衡而另一部分維度不變,那么這個遷移是一個不好的調度。
還有第三種情況,一部分維度更均衡同時也有一部分維度更不均衡了,這是一個中性的調度,往往這種中性的調度是不可避免的,例如集群中只有 A、B 兩個節點,A 的流量更高而 B 的數據量更高,由 A 向 B 遷移副本會使流量更均衡而數據量更不均衡,由 B 向 A 遷移副本則相反。
為了判斷這種中性的調度能否被允許,我們引入了優先級的概念,為每個維度賦予一個唯一的優先級,犧牲低優維度的均衡度換來高優維度更加均衡是可被接受的,犧牲高優維度的均衡度換來低優維度更加均衡則不可被接受。
仍然考慮前面的例子,因為流量過高會影響讀寫響應時間進而影響服務質量,我們認為流量的優先級高于數據量優先級,因此由 A 向 B 遷移可被接受。但是也存在一個例外,假設 B 節點的剩余磁盤空間已經接近 0,并且連集群中最小的副本都無法容納時,即使流量的優先級更好,也不應該允許向 B 遷移任何副本了。為了直觀表達這種資源飽和狀態,我們在示意圖上增加一條硬限線:
配合這個示意圖,多維度的負載均衡策略如下:
- 將多個維度按照優先級排序,從高優維度到低優維度依次執行上文描述的單維度調度策略,僅對流程做少量修改;
- 源節點上最接近Sbest但小于Sbest的副本為候選遷移對象,如果它導致任一下列情況出現,則將它排除,選擇下一個副本作為候選對象,直到找到合適的副本為止;
- 遷移之后,目標機器在更高優維度上將處于高水位線以上
- 遷移之后,目標機器在更低優維度上將處于硬限線以上
- 如果對于某一目標節點,源節點上無法選出遷移對象,將排在目標節點前一位的節點作為新的目標節點,重復上述過程
- 如果對于所有目標節點,源節點上仍然無法選出遷移對象,將該源節點從排序列表中剔除,重復上述過程
3)異構機型調度策略
對于同構機型,一個單位的負載在每個節點上都會使用同樣比例的資源,我們可以僅根據負載值進行調度,而不必這些負載使用了多少機器資源,但在異構機型上這是不成立的。
舉個例子,同樣是從磁盤上讀取 1MB 的數據,在高性能服務器上可能只占用 1%的 IO 帶寬和 1%的 CPU cycle,而在虛擬機上可能會占用 5%的 IO 帶寬和 3%的 CPU cycle。在不同性能的節點上,同樣的負載將產生不同的資源利用率。
要將前面的調度策略應用到異構機型的場景中,首先要將按負載值進行調度修改為按資源利用率進行調度。對于數據量來說,要改為磁盤空間利用率;對于流量來說,要改為 CPU 利用率、IO 利用率等等。為了簡化策略,我們將內存、磁盤 IO、網絡 IO 等使用情況全部納入到 CPU 利用率中。解釋一下為什么這么做:
- 對內存來說,我們的進程內存使用量的上限是通過配置項控制的,在部署時,我們會保證內存使用量一定不會超過物理內存大小,剩余物理內存全部用于操作系統的 buffer/cache,實際上也能夠被我們利用。內存大小會通過影響諸如 MemTable、BlockCache 的大小而影響節點性能,而這種影響最終會通過 CPU 和 IO 的使用量反映出來,所以我們考察 CPU 和 IO 的利用率就能把內存的使用情況納入進來。
- 對于磁盤 IO 來說,IO 利用率最終也會反映在 CPU 利用率上(同步 IO 體現在 wa 上,異步 IO 體現在 sys 上),因此我們考察 CPU 利用率就能把磁盤 IO 的使用情況納入進來。
- CPU 中有三級 cache,也有寄存器,在考慮 CPU 利用率時,會把它當作一個整體,不會單獨分析 cache 或是寄存器的使用情況。內存和磁盤可以想象成 CPU 的第四、五級 cache,內存越小、磁盤 IO 越慢,CPU 的利用率越高,可以將它們視為一個整體。
異構調度要解決的第二個問題是,資源利用率和負載值之間的轉換關系。舉個例子,A、B 兩個節點的 CPU 利用率分別是 50%和 30%,節點上每個副本的讀寫請求也是已知的,如何從 A 節點選擇最佳的副本遷移到 B 節點,使 A、B 的 CPU 利用率差距最小,要求我們必須計算出每個副本在 A、B 節點上分別會產生多少 CPU 利用率。為了做到這一點,我們盡可能多的收集了每個副本的讀寫請求信息,例如:
- 讀寫請求的 key、value 大小
- 讀的 cache 命中率
- 更新的隨機化程度、刪除的比例
根據這些信息,將每個讀寫請求轉換成 N 個標準流量。例如,一個 1KB 以內的請求是一個標準流量,一個 1~2KB 的請求是 2 個標準流量;命中 cache 的請求是一個標準流量,未命中 cache 的請求是 2 個標準流量。知道節點上總的標準流量值,就能根據 CPU 利用率算出這個節點上一個標準流量對應的 CPU 利用率,進而能夠算出每個副本在每個節點上對應的 CPU 利用率了。
綜上,異構機型調度策略只需要在多維度調度策略的基礎上做出如下修改:
- 節點按照資源利用率排序,而不是負載值
- 每個副本的負載值要分別轉換成源節點的資源利用率和目標節點的資源利用率,在異構機型上,同一個副本的資源利用率會有較大的不同
4)其它調度策略
KVMaster 中,有一個定時任務執行上述的負載均衡策略,叫做“負載均衡調度器”,這里不再贅述;同時,還有另一個定時任務,用來執行另一類調度,叫做“副本放置調度器”,除了副本安全級別(datacenter/rack/server)、節點異常檢測等基本策略之外,它還實現了下面幾種調度策略:
- 業務隔離策略:不同 namespace/table 可以存放在不同的節點上。每個 namespace/table 可指定一個字符串類型的 tag,每個節點可指定一個或多個 tag,副本所在 namespace/table 的 tag 與某節點 tag 相同時,才可放置在該節點上。調度器會對不滿足 tag 要求的副本進行調度。
- 熱點檢測:當某個數據分片的數據量達到一定閾值時會發生分裂,除此之外,當它的讀寫流量超過平均值的某個倍數后,也會發生分裂。當分裂發生后,其中一個新產生的分片(左邊或右邊)的所有副本都會遷移至其他節點,避免節點成為訪問熱點。
- 碎片檢測:當某個數據分片的數據量和讀寫流量都小于平均值的一定比例時,會與它所相鄰的分片進行合并。合并前會將小分片的所有副本遷移至相鄰分片所在的節點上。
五、表格層
前面提到,KV 數據模型過于簡單,很難滿足一些復雜業務場景的需求。比如:
- 字段數量和類型比較多
- 需要在不同的字段維度上進行復雜條件的查詢
- 字段或查詢維度經常隨著需求而變化。
我們需要更加豐富的數據模型來滿足這些場景的需求。在 KV 層之上,我們構建了表格層 ByteSQL,由前面提到的 SQLProxy 實現。ByteSQL 支持通過結構化查詢語言(SQL)來寫入和讀取,并基于 ByteKV 的批量寫入(WriteBatch)和快照讀接口實現了支持讀寫混合操作的交互式事務。
1、表格模型
在表格存儲模型中,數據按照數據庫(database), 表(table)兩個邏輯層級來組織和存放。同一個物理集群中可以創建多個數據庫,而每個數據庫內也可以創建多個表。表的 Schema 定義中包含以下元素:
- 表的基本屬性,包括數據庫名稱,表名稱,數據副本數等。
- 字段定義:包含字段的名字,類型,是否允許空值,默認值等屬性。一個表中須至少包含一個字段。
- 索引定義:包含索引名字,索引包含的字段列表,索引類型(Primary Key,Unique Key,Key 等)。一個表中有且僅有一個主鍵索引(Primary Key),用戶也可以加入二級索引(Key 或 Unique Key 類型)來提高 SQL 執行性能。每個索引都可以是單字段索引或多字段聯合索引。
表中的每一行都按照索引被編碼成多個 KV 記錄保存在 ByteKV 中,每種索引類型的編碼方式各不相同。Primary Key 的行中包含表中的所有字段的值,而二級索引的行中僅僅包含定義該索引和 Primary Key 的字段。具體每種索引的編碼方式如下:
- Primary Key: pk_field1, pk_field2,... => non_pk_field1, non_pk_field2...
- Unique Key: key_field1, key_field2,...=> pk_field1, pk_field2...
- NonUnique Key: key_field1, key_field2,..., pk_field1, pk_field2...=>
其中 pk_field 是定義 Primary Key 的字段,non_pk_field 是表中非 Primary Key 的字段,key_field 是定義某個二級索引的字段。=> 前后的內容分別對應 KV 層的 Key 和 Value 部分。Key 部分的編碼依然采用了上述提到的內存可比較編碼,從而保證了字段的自然順序與編碼之后的字節順序相同。而 Value 部分采用了與 protobuf 類似的變長編碼方式,盡量減少編碼后的數據大小。每個字段的編碼中使用 1 byte 來標識該值是否為空值。
2、全局二級索引
用戶經常有使用非主鍵字段做查詢條件的需求,這就需要在這些字段上創建二級索引。在傳統的 Sharding 架構中(如 MySQL Shard 集群),選取表中的某個字段做 Sharding Key,將整個表 Hash 到不同的 Shard 中。
由于不同 Shard 之間沒有高效的分布式事務機制,二級索引需要在每個 Shard 內創建(即局部二級索引)。這種方案的問題在于如果查詢條件不包含 Sharding Key,則需要掃描所有 Shard 做結果歸并,同時也無法實現全局唯一性約束。
為解決這種問題,ByteSQL 實現了全局二級索引,將主鍵的數據和二級索引的數據分布在 ByteKV 的不同的分片中,只根據二級索引上的查詢條件即可定位到該索引的記錄,進一步定位到對應的主鍵記錄。這種方式避免了掃描所有 Shard 做結果歸并的開銷,也可以通過創建 Unique Key 支持全局唯一性約束,具有很強的水平擴展性。
3、交互式事務
ByteSQL 基于 ByteKV 的多版本特性和多條記錄的原子性寫入(WriteBatch),實現了支持快照隔離級別(Snapshot Isolation)的讀寫事務,其基本實現思路如下:
- 用戶發起 Start Transaction 命令時,ByteSQL 從 ByteKV Master 獲取全局唯一的時間戳作為事務的開始時間戳(Start Timestamp),Start Timestamp 既用作事務內的一致性快照讀版本,也用作事務提交時的沖突判斷。
- 事務內的所有寫操作緩存在 ByteSQL 本地的 Write Buffer 中,每個事務都有自己的 Write Buffer 實例。如果是刪除操作,也要在 Write Buffer 中寫入一個 Tombstone 標記。
- 事務內的所有讀操作首先讀 Write Buffer,如果 Write Buffer 中存在記錄則直接返回(若 Write Buffer 中存在 Tombstone 返回記錄不存在);否則嘗試讀取 ByteKV 中版本號小于 Start Timestamp 的記錄。
- 用戶發起 Commit Transaction 命令時,ByteSQL 調用 ByteKV 的 WriteBatch 接口將 Write Buffer 中緩存的記錄提交,此時提交是有條件的:對于 Write Buffer 中的每個 Key,都必須保證提交時不能存在比 Start Timestamp 更大的版本存在。如果條件不成立,則必須 Abort 當前事務。這個條件是通過 ByteKV 的 CAS 接口來實現的。
由上述過程可知,ByteSQL 實現了樂觀模式的事務沖突檢測。這種模式在寫入沖突率不高的場景下非常高效。如果沖突率很高,會導致事務被頻繁 Abort。
4、執行流程優化
ByteSQL 提供了更加豐富的 SQL 查詢語義,但比起 KV 模型中簡單的 Put,Get 和 Delete 等操作卻增加了額外的開銷。SQL 中的 Insert,Update 和 Delete 操作實際都是一個先讀后寫的流程。以 Update 為例,先使用 Get 操作從 ByteKV 讀取舊值,在舊值上根據 SQL 的 Set 子句更新某些字段生成新值,然后用 Put 操作寫入新值到 ByteKV。
在一些場景下,某些字段的值可能是 ByteSQL 內自動生成的(如自動主鍵,以及具有 DEFAULT/ON UPDATE CURRENT_TIMESTAMP 屬性的時間字段)或根據依賴關系計算出來的(如 SET a = a+1),用戶需要在 Insert,Update 或 Delete 操作之后立即獲取實際變更的數據,需要在寫入之后執行一次 Select 操作。總共需要兩次 Get 操作和一次 Put 操作。為了優化執行效率,ByteSQL 中實現了 PostgreSQL/Oracle 語法中的 Returning 語義:在同一個 Query 請求中將 Insert/Update 的新值或 Delete 的舊值返回,節省了一次 Get 開銷。
- UPDATE table1 SET count = count + 1 WHERE id >= 10 RETURNING id, count;
5、在線 schema 變更
業務需求的不斷演進和變化導致 Schema 變更成為無法逃避的工作,傳統數據庫內置的 Schema 變更方案一般需要阻塞整表的讀寫操作,這是線上應用所無法接受的。ByteSQL 使用了 Google F1 的在線 Schema 變更方案[3],變更過程中不會阻塞線上讀寫請求。
ByteSQL Schema 元數據包含了庫和表的定義,這些元數據都保存在 ByteKV 中。SQLProxy 實例是無狀態的,每個實例定期從 ByteKV 同步 Schema 到本地,用來解析并執行 Query 請求。
同時集群中有一個專門的 Schema Change Worker 實例負責監聽并執行用戶提交的 Schema 變更任務。Schema Change Worker 一旦監聽到用戶提交的 Schema 變更請求,就將其放到一個請求隊列中并按序執行。本節從數據一致性異常的產生和解決角度,闡述了引入 Schema 中間狀態的原因。詳細的正確性證明可以參考原論文。
由于不同的 SQLProxy 實例加載 Schema 的時機并不相同,整個集群在同一時刻大概率會有多個版本的 Schema 在使用。如果 Schema 變更過程處理不當,會造成表中數據的不一致。以創建二級索引為例,考慮如下的執行流程:
- Schema Change Worker 執行了一個 Create Index 變更任務,包括向 ByteKV 中填充索引記錄和寫入元數據。
- SQLProxy 實例 1 加載了包含新索引的 Schema 元數據。
- SQLProxy 實例 2 執行 Insert 請求。由于實例 2 尚未加載索引元數據,Insert 操作不包含新索引記錄的寫入。
- SQLProxy 實例 2 執行 Delete 請求。由于實例 2 尚未加載索引元數據,Delete 操作不包含新索引記錄的刪除。
- SQLProxy 實例 2 加載了包含新索引的 Schema 元數據。
第 3 步和第 4 步都會導致二級索引和主鍵索引數據的不一致的異常:第 3 步導致二級索引記錄的缺失(Lost Write),第 4 步導致二級索引記錄的遺留(Lost Delete)。這些異常的成因在于不同 SQLProxy 實例加載 Schema 的時間不同,導致有些實例認為索引已經存在,而另外一些實例認為索引不存在。具體而言,第 2 步 Insert 的異常是由于索引已經存在,而寫入方認為其不存在;第 3 步的 Delete 異常是由于寫入方感知到了索引的存在,而刪除方未感知到。實際上,Update 操作可能會同時導致上述兩種異常。
為了解決 Lost Write 異常,我們需要保證對于插入的每行數據,寫入實例需要先感知到索引存在,然后再寫入;而對于 Lost Delete 異常,需要保證同一行數據的刪除實例比寫入實例先感知到索引的存在(如果寫入實例先感知索引,刪除實例后感知,刪除時有可能會漏刪索引而導致 Lost Delete)。
然而,我們無法直接控制不同 SQLProxy 實例作為寫入實例和刪除實例的感知順序,轉而使用了間接的方式:給 Schema 定義了兩種控制讀寫的中間狀態:DeleteOnly 狀態和 WriteOnly 狀態,Schema Change Worker 先寫入 DeleteOnly 狀態的 Schema 元數據,待元數據同步到所有實例后,再寫入 WriteOnly 狀態的 Schema 元數據。那些感知到 DeleteOnly 狀態的實例只能刪除索引記錄,不能寫入索引記錄;感知到 WriteOnly 狀態的實例既可以刪除又可以插入索引記錄。這樣就解決了 Lost Delete 異常。
而對于 Lost Write 異常,我們無法阻止尚未感知 Schema WriteOnly 狀態的實例寫入數據(因為整個 Schema 變更過程是在線的),而是將填充索引記錄的過程(原論文中稱之為 Reorg 操作)推遲到了 WriteOnly 階段之后執行,從而既填充了表中存量數據對應的索引記錄,也填充了那些因為 Lost Write 異常而缺失的索引記錄。待填充操作完成后,就可以將 Schema 元數據更新為對外可見的 Public 狀態了。
我們通過引入兩個中間狀態解決了 Schema 變更過程中數據不一致的異常。這兩個中間狀態均是對 ByteSQL 內部而言的,只有最終 Public 狀態的索引才能被用戶看到。這里還有一個關鍵問題:如何在沒有全局成員信息的環境中確保將 Schema 狀態同步到所有 SQLProxy 實例中?解決方案是在 Schema 中維護一個全局固定的 Lease Time,每個 SQLProxy 在 Lease Time 到期前需要重新從 ByteKV 中加載 Schema 來續約。
Schema Change Worker 每次更新 Schema 之后,需要等到所有 SQLProxy 加載成功后才能進行下一次更新。這就需要保證兩次更新 Schema 的間隔需要大于一定時間。至于多長的間隔時間是安全的,有興趣的讀者可以詳細閱讀原論文[3]來得到答案。如果某個 SQLProxy 因為某種原因無法在 Lease Time 周期內加載 Schema,則設置當前 ByteSQL 實例為不可用狀態,不再處理讀寫請求。
六、未來探討
1、更多的一致性級別
在跨機房部署的場景里,總有部分請求需要跨機房獲取事務時間戳,這會增加響應延遲;同時跨機房的網絡環境不及機房內部穩定,跨機房網絡的穩定性直接影響到集群的穩定性。實際上,部分業務場景并不需要強一致保證。在這些場景中,我們考慮引入混合邏輯時鐘 HLC[4]來替代原有的全局授時服務,將 ByteKV 改造成支持因果一致性的系統。同時,我們可以將寫入的時間戳作為同步口令返回給客戶端,客戶端在后續的請求中攜帶上同步口令,以傳遞業務上存在因果關系而存儲系統無法識別的事件之間的 happen-before 關系,即會話一致性。
此外,還有部分業務對延遲極其敏感,又有多數據中心訪問的需求;而 ByteKV 多機房部署場景下無法避免跨機房延遲。如果這部分業務只需要機房之間保持最終一致即可,我們可以進行機房間數據同步,實現類最終一致性的效果。
2、Cloud Native
隨著 CloudNative 的進一步發展,以無可匹敵之勢深刻影響著現有的開發部署模型。ByteKV 也將進一步探索與 CloudNative 的深入結合。探索基于 Kubernetes 的 auto deployment, auto scaling, auto healing。進一步提高資源的利用率,降低運維的成本,增強服務的易用性。提供一個更方便于 CloudNative 用戶使用的 ByteKV。