揭秘分布式系統:日志復制如何保障數據一致性?

大家好,我是你們的老朋友小米!今天我們來聊一聊分布式系統中的一個重要話題——日志復制。這可是保證系統高可用性和數據一致性的關鍵技術哦~
1.前言
在分布式系統中,為了保證數據的一致性和系統的容錯性,我們常常會將數據復制到多個服務器上。而其中一種常見的方法就是日志復制。無論是Raft一致性算法還是Paxos協議,日志復制都是核心的操作。今天,我們就以Raft算法為例,詳細探討一下日志復制的工作流程。
 圖片
圖片
2.Leader是如何添加指令到日志中的?
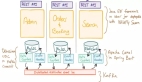
在Raft算法中,集群中的服務器分為三種角色:Leader、Follower和Candidate。在正常運行時,只有一個Leader,其他服務器都是Follower。Leader負責接收客戶端的請求并將這些請求復制到其他Follower的日志中。
當Leader收到一個客戶端的請求(例如要更新某個數據),它會先將這個請求添加到自己的日志中。這個過程可以簡單理解為Leader在自己的筆記本上記了一筆賬。記賬完成后,Leader就要通知其他的服務器了。
3.RPC,消息的傳遞者
為了保證所有服務器上的日志都是一致的,Leader需要將剛才記下的那筆賬復制到所有Follower的日志中。這個過程是通過RPC(遠程過程調用)來實現的。Leader會向每一個Follower發送一個RPC請求,告訴他們“我要加一條日志,你們也要加上哦!”。
具體流程如下:
Leader發起RPC請求:Leader把剛添加到日志中的指令封裝成一個RPC請求,發送給所有的Follower。
Follower接收并處理請求:Follower收到請求后,會將這條指令添加到自己的日志中,并返回一個ACK(確認響應)給Leader,表示自己已經接收到并記錄了這條日志。
Leader等待ACK:Leader會等待所有Follower的ACK,以確保所有的Follower都接收到并記錄了這條日志。
4.Leader的重試機制
在實際的網絡環境中,由于網絡延遲或者其他故障,Follower可能會沒有及時響應Leader的RPC請求。這時,Leader并不會放棄,而是會不斷地重試,直到收到所有Follower的ACK為止。
重試機制的具體實現
Leader在發送RPC請求后,會啟動一個定時器。如果在規定的時間內沒有收到某個Follower的ACK,Leader就會再次發送這個請求,直到這個Follower響應為止。這種重試機制保證了即使某些Follower暫時不可用,當它們恢復后,仍然能夠接收到所有的日志條目,從而保持日志的一致性。
5.提交日志,最終一致性的保證
當Leader收到了所有Follower的ACK后,就意味著這條日志已經被復制到了集群中的大多數服務器上(通常是超過半數的服務器)。這時,Leader就可以認為這條日志是“安全”的,可以提交了。
通知Follower提交日志
Leader會向所有Follower發送一個“提交”消息,告訴他們可以提交這條日志了。提交日志的意思是將這條日志中的指令應用到服務器的狀態機中(比如更新數據庫中的某個數據)。
更新日志狀態
Leader在提交日志后,會更新這條日志的狀態,標記為“已提交”。然后,Leader會將操作的結果返回給客戶端。
整個流程總結
客戶端請求:客戶端向Leader發送一個請求。
Leader添加日志:Leader將請求添加到自己的日志中。
Leader發起RPC:Leader向所有Follower發送RPC請求,復制日志。
Follower響應ACK:Follower接收并記錄日志,返回ACK給Leader。
Leader重試:Leader在未收到所有Follower的ACK前,不斷重試。
Leader提交日志:收到所有Follower的ACK后,Leader提交日志并通知Follower提交。
Leader返回結果:Leader將操作結果返回給客戶端。
6.日志復制中的挑戰
雖然日志復制看起來流程很簡單,但在實際應用中會遇到很多挑戰。
網絡分區
在分布式系統中,網絡分區是不可避免的。當網絡分區發生時,集群可能會被分割成兩個或多個部分,部分服務器之間無法通信。此時,Leader可能無法收到所有Follower的ACK,導致日志無法提交。
解決網絡分區的問題通常有兩種方法:
- 超時機制:Leader在等待ACK時設置一個超時時間,如果超時未收到ACK,則認為Follower不可用,進行重試。
- 領導選舉:如果Leader認為自己與大多數Follower失去了聯系,會觸發領導選舉,選出新的Leader。
日志一致性
在分布式系統中,確保所有服務器的日志一致性是一個重要挑戰。任何一個服務器的日志與其他服務器不一致,都會導致系統狀態的不一致。
為了保證日志一致性,Raft算法采用了以下幾種策略:
- 強制日志匹配:當一個Follower的日志與Leader的日志不一致時,Leader會強制Follower與自己保持一致,丟棄Follower多余的日志條目。
- 日志壓縮:為了防止日志無限增長,系統會定期進行日志壓縮,刪除已經提交并應用到狀態機的日志條目。
END
日志復制是分布式系統中保證數據一致性和系統高可用性的核心技術。通過Leader發起RPC請求,Follower響應ACK,Leader重試機制以及最終提交日志,保證了系統在面對各種網絡故障和服務器故障時,仍能保持一致性和高可用性。
希望今天的分享能讓大家對日志復制有一個更深入的理解。