關于分布式系統的數據一致性問題(一)
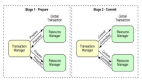
現在先拋出問題,假設有一個主數據中心在北京M,然后有成都A,上海B兩個地方數據中心,現在的問題是,假設成都上海各自的數據中心有記錄變更,需要先同步到主數據中心,主數據中心更新完成之后,在把最新的數據分發到上海,成都的地方數據中心A,地方數據中心更新數據,保持和主數據中心一致性(數據庫結構完全一致)。數據更新的消息是通過一臺中心的MQ進行轉發。

先把問題簡單化處理,假設A增加一條記錄Message_A,發送到M,B增加一條記錄 MESSAGE_B發送到M,都是通過MQ服務器進行轉發,那么M系統接收到條消息,增加兩條數據,那么M在把增加的消息群發給A,B,A和B找到自己缺失的數據,更新數據庫。這樣就完成了一個數據的同步。
從正常情況下來看,都沒有問題,邏輯完全合理,但是請考慮以下三個問題
1 如何保證A->M的消息,M一定接收到了,同樣,如何保證M->A的消息,M一定接收到了
2 如果數據需要一致性更新,比如A發送了三條消息給M,M要么全部保存,要么全部不保存,不能夠只保存其中的幾條記錄。我們假設更新的數據是一條條發送的。
3 假設同時A發送了多條更新請求,如何保證順序性要求?
這兩個問題就是分布式環境下數據一致性的問題
對于第一個問題,比較好解決,我們先看看一個tcp/ip協議鏈接建立的過程

我們的思路可以從這個上面出發,在簡化一下,就一個請求,一個應答。
簡單的通信模型是這樣的
A->M : 你收到我的一條消息沒有,消息的ID是12345
M->A: 我收到了你的一條消息數據,消息數據是ID;12345
這樣就一個請求,一個應答,就完成了一次可靠性的傳輸。如果A一致沒有收到M的應答,就不斷的重試。這個時候M就必須保證冪等性。不能重復的處理消息。那么最極端的情況是,怎么也收不到M的應答,這個時候是系統故障。自己檢查一下吧。
這么設計就要求,A在發送消息的時候持久化這個消息的數據內容,然后不斷的重試,一旦接收到M的應答,就刪除這條消息。同樣,M端也是一樣的。不要相信MQ的持久化機制,不是很靠譜的。
那么M給A發送消息也采取類似的原理就可以了。
下面在看看第二個問題,如何保持數據的一致性更新,這個還是可以參考TCP/IP的協議。
首先A發送一條消息給M:我要發送一批消息數據給你,批次號是10000,數據是5條。
M發送一條消息給A:ok,我準備好了,批次號是10000,發送方你A
接著A發送5條消息給M,消息ID分別為1,2,3,4,5 ,批次號是10000,
緊接著,A發送一個信息給M:我已經完成5小消息的發送,你要提交數據更新了
接下來可能發送兩種情況
1 那么M發送消息給A:ok,我收到了5條消息,開始提交數據
2 那么M也可以發送給A:我收到了5條消息,但是還缺少,請你重新發送,那么A就繼續發送,直到A收到M成功的應答。
整個過程相當復雜。這個也就是數據一旦分布了,帶來最大的問題就是數據一致性的問題。這個成本非常高。
對于第三個問題,這個就比較復雜了
這個最核心的問題就是消息的順序性,我們只能在每個消息發一個消息的序列號,但是還是沒有最好解決這個問題的辦法。因為消息接收方不知道順序。因為即使給他了序列號,也沒有辦法告訴他,這個應該何時處理。最好的辦法是在第二種方式的基礎作為一個批次來更新。
這個只是以最簡單的例子來說明一下分布式系統的要保證數據一致性是一件代價很大的事情。當然有的博主會說,這個何必這么復雜,直接數據庫同步不就可以了。這個例子當然是沒有問題的,萬一這個幾個庫的模型都不一樣,我發送消息要處理的事情不一樣的。怎么辦?
原文鏈接:http://www.cnblogs.com/aigongsi/archive/2012/09/21/2696773.html
【編輯推薦】