六項任務、多種數據類型,谷歌、DeepMind提出高效Transformer評估基準
-
基準項目地址:https://github.com/google-research/long-range-arena
-
論文地址:https://arxiv.org/pdf/2011.04006.pdf
Transformer 在多個模態(語言、圖像、蛋白質序列)中獲得了 SOTA 結果,但它存在一個缺點:自注意力機制的平方級復雜度限制了其在長序列領域中的應用。目前,研究人員提出大量高效 Transformer 模型(「xformer」),試圖解決該問題。其中很多展示出了媲美原版 Transformer 的性能,同時還能有效降低自注意力機制的內存復雜度。
谷歌和DeepMind的研究人員對比了這些論文的評估和實驗設置,得到了以下幾點發現:
-
首先,高效 Transformer 缺少統一的基準測試,使用的任務類型也多種多樣:每個模型在不同的任務和數據集上進行評估。
-
其次,評估所用基準通常是隨意選擇的,未充分考慮該任務是否適用于長程建模評估。
-
第三,很多論文將歸納偏置的效果和預訓練的優點混為一談,這會模糊模型的真正價值:預訓練本身是計算密集型的,將歸納偏置和預訓練分離開來可降低 xformer 研究的門檻。
于是,谷歌和DeepMind的研究人員提出了一個新基準Long-Range Arena (LRA),用來對長語境場景下的序列模型進行基準測試。該基準包括合成任務和現實任務,研究人員在此基準上對比了十個近期提出的高效 Transformer 模型,包括 Sparse Transformers、 Reformer 、Linformer、Longformer、Sinkhorn Transformer、 Performer 、Synthesizer、Linear Transformer 和 BigBird 模型。
該基準主要關注模型在長語境場景下的能力,不過研究人員對 xformer 架構在不同數據類型和條件下的能力也很感興趣。因此,該基準選擇了具備特定先驗結構的數據集和任務。例如,這些架構可以建模層級結構長序列或包含某種空間結構形式的長序列嗎?這些任務的序列長度從 1K 到 16K token 不等,還包括大量數據類型和模態,如文本、自然圖像、合成圖像,以及需要類似度、結構和視覺 - 空間推理的數學表達式。該基準主要面向高效 Transformer,但也可作為長程序列建模的基準。
除了對比模型質量以外,該研究還進行了大量效率和內存使用分析。研究者認為,并行性能基準測試對于社區是有益且珍貴的,能夠幫助大家深入了解這些方法的實際效率。總之,該研究提出了一個統一框架,既能對高效 Transformer 模型進行簡單的并行對比分析,還能對長程序列模型進行基準測試。該框架使用 JAX/FLAX1 編寫。
高效 Transformer 評估新基準:Long-Range Arena (LRA)
基準需求
在創建 LRA基準之前,研究者先列舉了一些需求:
-
1. 通用性:適用于所有高效 Transformer 模型。例如,并非所有 xformer 模型都能執行自回歸解碼,因此該基準中的任務僅需要編碼。
-
2. 簡潔性:任務設置應簡單,移除所有令模型對比復雜化的因素,這可以鼓勵簡單模型而不是笨重的 pipeline 方法。
-
3. 挑戰性:任務應該對目前模型有一定難度,以確保未來該方向的研究有足夠的進步空間。
-
4. 長輸入:輸入序列長度應該足夠長,因為評估不同模型如何捕獲長程依賴是 LRA基準的核心關注點。
-
5. 探索不同方面的能力:任務集合應當評估模型的不同能力,如建模關系和層級 / 空間結構、泛化能力等。
-
6. 非資源密集、方便使用:基準應該是輕量級的,方便不具備工業級計算資源的研究者使用。
任務
LRA基準包含多項任務,旨在評估高效 Transformer 模型的不同能力。具體而言,這些任務包括:Long ListOps、比特級文本分類、比特級文檔檢索、基于像素序列的圖像分類、Pathfinder(長程空間依賴性)、Pathfinder-X(極端長度下的長程空間依賴性)。
LRA 任務所需的注意力 范圍
LRA基準的主要目標之一是評估高效 Transformer 模型捕獲長程依賴的能力。為了對注意力機制在編碼輸入時需要考慮的空間范圍進行量化估計,該研究提出了「所需注意力范圍」(required attention span)。給出一個注意力模型和輸入 token 序列,注意力模塊的所需注意力范圍是 query token 和 attended token 間的平均距離。
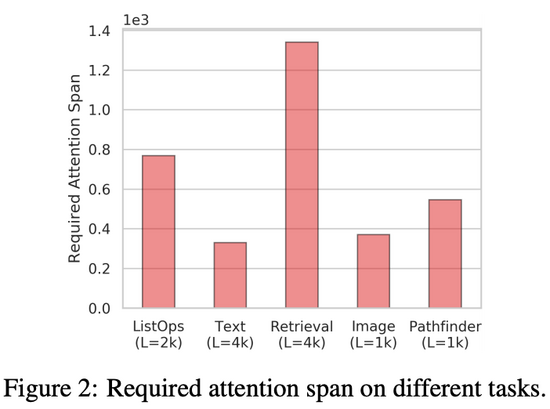
圖 2 總結了 LRA基準中每項任務的所需注意力范圍,從圖中可以看出每項任務的所需注意力范圍都很高。這表明,Transformer 模型不僅僅涉及局部信息,在很多任務和數據集中,注意力機制通常需要結合鄰近位置的信息。
實驗
量化結果
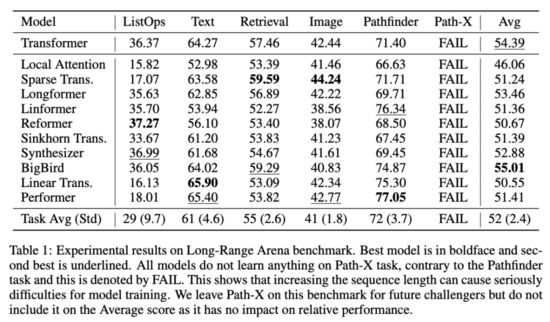
實驗結果表明,LRA 中的所有任務都具備一定的挑戰性,不同 xformer 模型的性能存在一定程度的差異。具體結果參見下表 1:
效率基準
表 2 展示了 xformer 模型的效率基準測試結果:
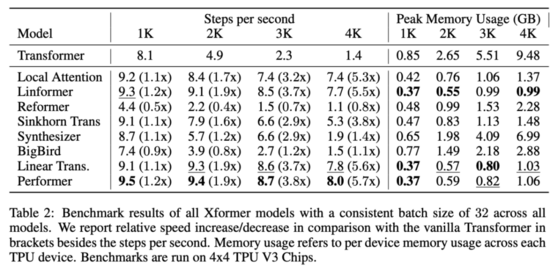
從中可以看出,低秩模型和基于核的模型通常速度最快。整體最快的模型是 Performer,在 4k 序列長度上的速度是 Transformer 的 5.7 倍,Linformer 和 Linear Transformer 緊隨其后。最慢的模型是 Reformer,在 4k 序列長度上的速度是 Transformer 的 80%,在 1k 序列長度上的速度是 Transformer 的一半。
此外,研究者還評估了這些模型的內存消耗情況。結果顯示,內存占用最少的模型是 Linformer,在 4k 序列長度上只使用了 0.99GB per TPU,而原版 Transformer 使用了 9.48GB per TPU,內存占用減少了約 90%。
整體結果:不存在萬能模型
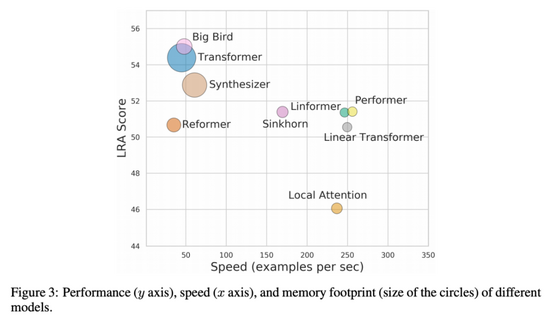
根據研究人員的分析,在 LRA 所有任務中整體性能最好(LRA 分數最高)的模型是 BigBird。但是,BigBird 在每項任務中的性能均不是最好,它只是在所有任務上都能取得不錯的性能。Performer 和 Linear Transformer 在一些任務中表現搶眼,但其平均分被 ListOps 任務拖累。
下圖 3 展示了模型性能、速度和內存占用之間的權衡情況。BigBird 性能最好,但速度幾乎與原版 Transformer 相同。而 Local Attention 模型速度很快,但性能較低。在這些模型中,基于核的模型(如 Performer、Linformer 和 Linear Transformer)能夠在速度和性能之間獲得更好的折中效果,同時內存占用也較為合理。