模型壓縮95%,MIT韓松等人提出新型Lite Transformer
Transformer 的高性能依賴于極高的算力,這讓移動(dòng)端 NLP 嚴(yán)重受限。在不久之前的 ICLR 2020 論文中,MIT 與上海交大的研究人員提出了一種高效的移動(dòng)端 NLP 架構(gòu) Lite Transformer,向在邊緣設(shè)備上部署移動(dòng)級(jí) NLP 應(yīng)用邁進(jìn)了一大步。
雖然推出還不到 3 年,Transformer 已成為自然語(yǔ)言處理(NLP)領(lǐng)域里不可或缺的一環(huán)。然而這樣流行的算法卻需要極高的算力才能實(shí)現(xiàn)足夠的性能,這對(duì)于受到算力和電池嚴(yán)格限制的移動(dòng)端來說有些力不從心。
在 MIT 最近的研究《Lite Transformer with Long-Short Range Attention》中,MIT 與上海交大的研究人員提出了一種高效的移動(dòng)端 NLP 架構(gòu) Lite Transformer,向在邊緣設(shè)備上部署移動(dòng)級(jí) NLP 應(yīng)用邁進(jìn)了一大步。該論文已被人工智能頂會(huì) ICLR 2020 收錄。
該研究是由 MIT 電氣工程和計(jì)算機(jī)科學(xué)系助理教授韓松領(lǐng)導(dǎo)的。韓松的研究廣泛涉足深度學(xué)習(xí)和計(jì)算機(jī)體系結(jié)構(gòu),他提出的 Deep Compression 模型壓縮技術(shù)曾獲得 ICLR2016 最佳論文,論文 ESE 稀疏神經(jīng)網(wǎng)絡(luò)推理引擎 2017 年曾獲得芯片領(lǐng)域頂級(jí)會(huì)議——FPGA 最佳論文獎(jiǎng),引領(lǐng)了世界深度學(xué)習(xí)加速研究,對(duì)業(yè)界影響深遠(yuǎn)。

論文地址:
https://arxiv.org/abs/2004.11886v1
GitHub 地址:
https://github.com/mit-han-lab/lite-transformer
Transformer 在自然語(yǔ)言處理任務(wù)(如機(jī)器翻譯、問答)中應(yīng)用廣泛,但它需要大量計(jì)算去實(shí)現(xiàn)高性能,而這不適合受限于硬件資源和電池嚴(yán)格限制的移動(dòng)應(yīng)用。
這項(xiàng)研究提出了一種高效的移動(dòng)端 NLP 架構(gòu)——Lite Transformer,它有助于在邊緣設(shè)備上部署移動(dòng) NLP 應(yīng)用。其核心是長(zhǎng)短距離注意力(Long-Short Range Attention,LSRA),其中一組注意力頭(通過卷積)負(fù)責(zé)局部上下文建模,而另一組則(依靠注意力)執(zhí)行長(zhǎng)距離關(guān)系建模。
這樣的專門化配置使得模型在三個(gè)語(yǔ)言任務(wù)上都比原版 transformer 有所提升,這三個(gè)任務(wù)分別是機(jī)器翻譯、文本摘要和語(yǔ)言建模。
在資源有限的情況下(500M/100M MACs),Lite Transformer 在 WMT’14 英法數(shù)據(jù)集上的 BLEU 值比分別比 transformer 高 1.2/1.7。Lite Transformer 比 transformer base 模型的計(jì)算量減少了 60%,而 BLEU 分?jǐn)?shù)卻只降低了 0.3。結(jié)合剪枝和量化技術(shù),研究者進(jìn)一步將 Lite Transformer 模型的大小壓縮到原來的 5%。
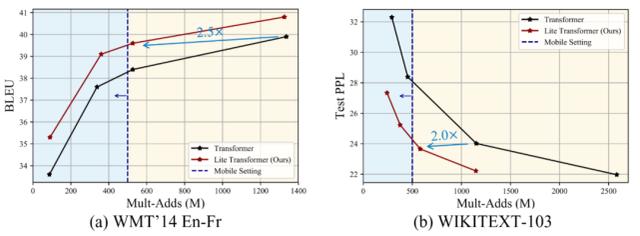
對(duì)于語(yǔ)言建模任務(wù),在大約 500M MACs 上,Lite Transformer 比 transformer 的困惑度低 1.8。
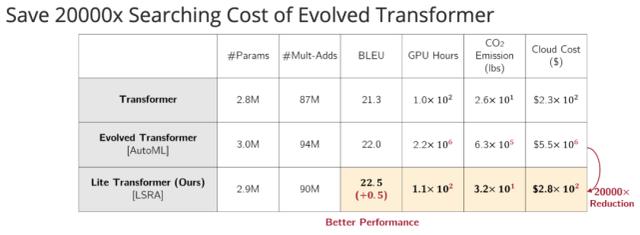
值得注意的是,對(duì)于移動(dòng) NLP 設(shè)置,Lite Transformer 的 BLEU 值比基于 AutoML 的 Evolved Transformer 高 0.5,而且它不需要使用成本高昂的架構(gòu)搜索。
從 Lite Transformer 與 Evolved Transformer、原版 transformer 的比較結(jié)果中可以看出,Lite Transformer 的性能更佳,搜索成本相比 Evolved Transformer 大大減少。
那么,Lite Transformer 為何能夠?qū)崿F(xiàn)高性能和低成本呢?接下來我們來了解其核心思想。
長(zhǎng)短距離注意力(LSRA)
NLP 領(lǐng)域的研究人員試圖理解被注意力捕捉到的上下文。Kovaleva 等人 (2019) 和 Clark 等人 (2020) 對(duì) BERT 不同層的注意力權(quán)重進(jìn)行了可視化。
如下圖 3b 所示,權(quán)重 w 表示源句單詞與目標(biāo)句單詞之間的關(guān)系(自注意力也是如此)。隨著權(quán)重 w_ij 的增加(顏色加深),源句中的第 i 個(gè)詞更加注意目標(biāo)句中的第 j 個(gè)詞。注意力圖通常有很強(qiáng)的模式化特征:稀疏和對(duì)角線。它們代表了一些特定單詞之間的關(guān)系:稀疏表示長(zhǎng)距離信息間的關(guān)系,對(duì)角線表示近距離信息間的關(guān)系。研究者將前者稱為「全局」關(guān)系,將后者稱為「局部」關(guān)系。
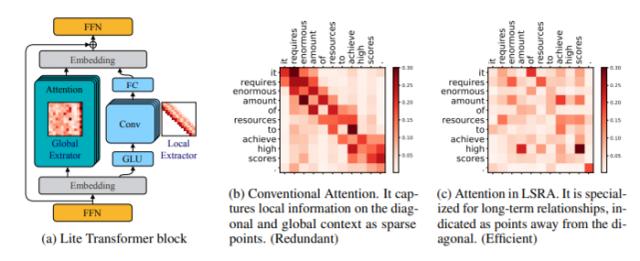
圖 3:Lite Transformer 架構(gòu) (a) 和注意力權(quán)重的可視化。傳統(tǒng)的注意力 (b) 過于強(qiáng)調(diào)局部關(guān)系建模(參見對(duì)角線結(jié)構(gòu))。該研究使用卷積層專門處理局部特征提取工作,以高效建模局部信息,從而使注意力分支可以專門進(jìn)行全局特征提取 (c)。
在翻譯任務(wù)中,注意力模塊必須捕獲全局和局部上下文,這需要很大的容量。與專門化的設(shè)計(jì)相比,這并非最佳選擇。以硬件設(shè)計(jì)為例,CPU 等通用硬件的效率比 FPGA 等專用硬件低。研究者認(rèn)為應(yīng)該分別捕捉全局和局部上下文。模型容量較大時(shí),可以容忍冗余,甚至可以提供更好的性能。但是在移動(dòng)應(yīng)用上,由于計(jì)算和功率的限制,模型應(yīng)該更加高效。因此,更需要專門化的上下文捕獲。
為了解決該問題,該研究提出一個(gè)更專門化的架構(gòu),即長(zhǎng)短距離注意力(LSRA),而不是使用處理 “一般” 信息的模塊。該架構(gòu)分別捕獲局部和全局上下文。
如圖 3a 所示,LSRA 模塊遵循兩分支設(shè)計(jì)。左側(cè)注意力分支負(fù)責(zé)捕獲全局上下文,右側(cè)卷積分支則建模局部上下文。研究者沒有將整個(gè)輸入饋送到兩個(gè)分支,而是將其沿通道維度分為兩部分,然后由后面的 FFN 層進(jìn)行混合。這種做法將整體計(jì)算量減少了 50%。
左側(cè)分支是正常的注意力模塊(Vaswani et al. (2017)),不過通道維度減少了一半。至于處理局部關(guān)系的右分支,一個(gè)自然的想法是對(duì)序列應(yīng)用卷積。使用滑動(dòng)窗口,模塊可以輕松地覆蓋對(duì)角線組。為了進(jìn)一步減少計(jì)算量,研究者將普通卷積替換為輕量級(jí)的版本,該版本由線性層和深度卷積組成。通過這種方式,研究者將注意力模塊和卷積模塊并排放置,引導(dǎo)它們對(duì)句子進(jìn)行全局和局部的不同角度處理,從而使架構(gòu)從這種專門化設(shè)置中受益,并實(shí)現(xiàn)更高的效率。
實(shí)驗(yàn)設(shè)置
數(shù)據(jù)集和評(píng)估
研究者在機(jī)器翻譯、文本摘要和語(yǔ)言建模三個(gè)任務(wù)上進(jìn)行了實(shí)驗(yàn)和評(píng)估。
具體而言,機(jī)器翻譯任務(wù)使用了三個(gè)基準(zhǔn)數(shù)據(jù)集:IWSLT’14 德語(yǔ) - 英語(yǔ) (De-En)、WMT 英語(yǔ) - 德語(yǔ) (En-De)、WMT 英語(yǔ) - 法語(yǔ)(En-Fr)。
文本摘要任務(wù)使用的是 CNN-DailyMail 數(shù)據(jù)集。
語(yǔ)言建模任務(wù)則在 WIKITEXT-103 數(shù)據(jù)集上進(jìn)行。
架構(gòu)
模型架構(gòu)是基于序列到序列學(xué)習(xí)的編碼器 - 解碼器。在機(jī)器翻譯任務(wù)中,針對(duì) WMT 數(shù)據(jù)集,基線模型基于 Vaswani 等人提出的模型。對(duì)于 IWSLT 數(shù)據(jù)集,基線模型遵循 Wu 等人的設(shè)置。對(duì)于文本摘要任務(wù),研究者采用了與 WMT 相同的模型。至于語(yǔ)言建模任務(wù),模型與 Baevski & Auli (2019) 一致,但模型尺寸較小。
該研究提出的架構(gòu)首先將 transformer base 模型中的 bottleneck 拉平,然后用 LSRA 替換自注意力。更具體地說,是使用兩個(gè)專門的模塊,一個(gè)注意力分支和一個(gè)卷積分支。
實(shí)驗(yàn)結(jié)果
機(jī)器翻譯
表 1 展示了 Lite Transformer 在 IWSLT’14 De-En 數(shù)據(jù)集上的定量結(jié)果,并與 transformer 基線方法和 LightConv 做了對(duì)比。在大約 100M Mult-Adds 時(shí),Lite Transformer 模型的 BLEU 值比 transformer 高出 1.6。
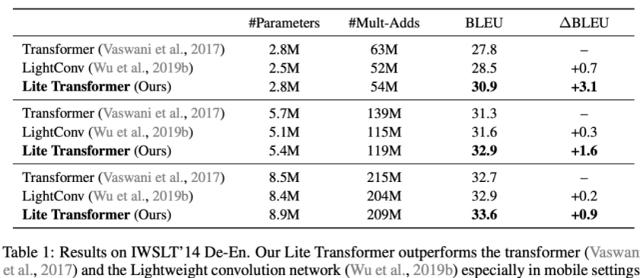
表 1:IWSLT’14 De-En 上的結(jié)果。
表 2 中的定量結(jié)果表明,在 100M Mult-Adds 設(shè)置下,Lite Transformer 在 WMT En-De 數(shù)據(jù)集和 WMT En-Fr 數(shù)據(jù)集上的 BLEU 值分別比 Transformer 高出 1.2 和 1.7,在 300M Mult-Adds 設(shè)置下,也有 0.5 和 1.5 分的提升。
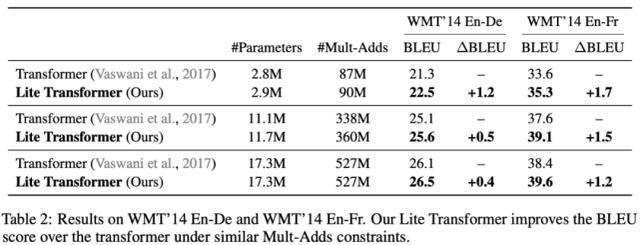
表 2:在 WMT’14 En-De 和 WMT’14 En-Fr 上的結(jié)果。
研究者還提供了模型在 WMT En-Fr 上的權(quán)衡曲線,如圖 4a 所示,Lite Transformer 一直優(yōu)于原版 transformer。
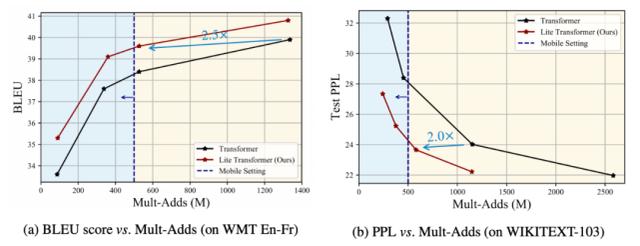
圖 4:在 WMT En-Fr 數(shù)據(jù)集上的機(jī)器翻譯權(quán)衡曲線,以及在 WIKITEXT-103 數(shù)據(jù)集上的語(yǔ)言建模權(quán)衡曲線。兩個(gè)曲線都說明了在移動(dòng)設(shè)置下,Lite Transformer 比 transformer 性能更佳(藍(lán)色區(qū)域)。
與自動(dòng)化設(shè)計(jì)模型的對(duì)比
與基于 AutoML 的 Evolved Transformer(ET)相比,Lite Transformer 在移動(dòng)設(shè)置中也有明顯的改進(jìn)。此外,在 100M 和 300M 的 Mult-Adds 下,Lite Transformer 的 BLEU 值分別比 ET 高 0.5 和 0.2,詳見表 3。
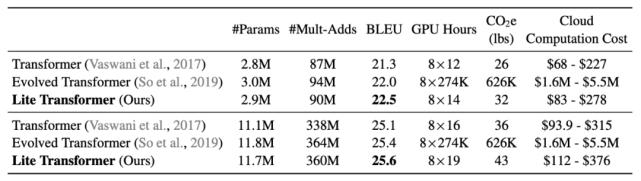
表 3:不同 NMT 模型的性能和訓(xùn)練成本。
文本摘要

表 4:在 CNN-DailyMail 數(shù)據(jù)集上的文本摘要結(jié)果。
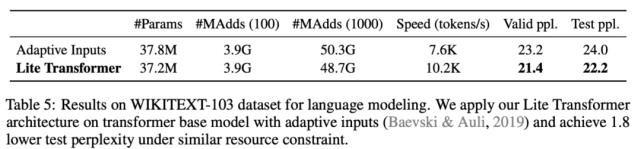
表 5:在 WIKITEXT-103 數(shù)據(jù)集上的語(yǔ)言建模結(jié)果。