NeurIPS 2024 | 哈工深提出新型智能體Optimus-1,橫掃Minecraft長序列任務
本篇論文的工作已被 NeurlPS(Conference on Neural Information Processing Systems)2024 會議接收。本文主要作者來自哈爾濱工業大學 (深圳) ,合作單位為鵬城實驗室。其中,第一作者李在京就讀于哈爾濱工業大學 (深圳) 計算機學院,研究方向為開放世界智能體和多模態學習。
在 Minecraft 中構造一個能完成各種長序列任務的智能體,頗有挑戰性。現有的工作利用大語言模型 / 多模態大模型生成行動規劃,以提升智能體執行長序列任務的能力。然而,由于這些智能體缺乏足夠的知識和經驗,面對 Minecraft 中復雜的環境仍顯得力不從心。為此,本文提出了一個新穎的智能體框架 ——Optimus-1,該框架結合結構化知識與多模態經驗,旨在賦能智能體更好地執行長序列任務。

- 論文題目:Optimus-1: Hybrid Multimodal Memory Empowered Agents Excel in Long-Horizon Tasks
- 論文鏈接:https://arxiv.org/abs/2408.03615
- 項目主頁:https://cybertronagent.github.io/Optimus-1.github.io/
- 代碼倉庫:https://github.com/JiuTian-VL/Optimus-1
現有的 Minecraft Agents 有哪些局限性?
1. 對結構化知識缺乏探索。Minecraft 中充滿了豐富的結構化知識,例如工具的合成規則(一根木棍和兩塊鐵錠可以合成一把鐵劍),以及不同層級的科技樹(木材 → 石器 → 鐵器 → 金器 → 鉆石)等。這些知識有助于智能體做出合理的規劃,一步一步獲取完成任務所需的材料和工具。然而,現有的智能體缺乏必要的知識,導致他們做出長序列規劃的能力受限。
2. 缺乏充足的多模態經驗。過往的經驗對幫助人類完成未曾遇見的任務具有重要作用,同樣,智能體也能借助歷史經驗在面對新任務時作出更加精準的判斷與決策。然而,現有的智能體在多模態經驗的積累與總結上存在缺陷,未能有效整合視覺、語言、動作等多方面的經驗,限制了其在復雜任務中的決策能力和適應性。
為了解決上述挑戰,我們設計了一個混合多模態記憶模塊,將結構化知識和多模態經驗整合到智能體的記憶機制中。類似于知識與經驗在指導人類完成復雜任務中的重要作用,智能體在規劃階段借助結構化知識生成可行的任務計劃,而在反思階段則利用多模態經驗對當前狀態進行判斷,并做出更加合理的決策。在此基礎上,我們提出了智能體框架 Optimus-1。在混合多模態記憶的賦能下,Optimus-1 在 67 個長序列任務上實現了當前最先進的性能,并縮小了與人類水平基線的差距。
研究方法
Optimus-1 的框架如下圖所示。它由混合多模態記憶模塊,知識引導的規劃器,經驗驅動的反思器,以及行動控制器組成。給定一個長序列任務,知識引導的規劃器首先從混合多模態記憶中檢索任務相關的知識,并基于這些知識生成一系列可執行的子目標。這些子目標依次輸入到行動控制器中,生成行動信號以完成任務。在執行任務過程中,經驗驅動反思器會定期激活,檢索與當前子目標相關的多模態經驗作為參考,以此判斷智能體當前狀態,從而做出更為合理的決策。

圖 1:Optimus-1 的整體框架
1. 混合多模態記憶(Hybrid Multimodal Memory)

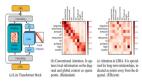
圖 2:摘要化多模態經驗池和層次化有向知識圖的構建流程
如上圖所示,混合多模態記憶由摘要化多模態經驗池(AMEP)和層次化有向知識圖(HDKG)組成。對于 AMEP,視頻流首先通過 Video Buffer 和 Image Buffer 過濾,得到固定窗口大小的幀序列,并與文本通過 MineCLIP 計算相似度,若超過閾值,則保存幀序列、文本及環境信息等內容作為多模態經驗。這些經驗為智能體反思階段提供細粒度的多模態信息,同時通過摘要化降低了存儲開銷。
對于 HDKG,任務執行過程中獲取的知識被轉化為圖結構。例如,“兩根木棍和三塊木板可以合成一把木鎬” 被表示為有向圖 {2 sticks, 3 planks} → {1 wooden pickaxe},為智能體的規劃階段提供必要的知識支持,幫助其做出合理的任務規劃。
2. 知識引導的規劃器(Knowledge-Guided Planner)
給定任務 t,當前的視覺觀察 o,知識引導的規劃器從 HDKG 中檢索相關知識,生成子目標序列 :
:

其中, 表示多模態大模型,
表示多模態大模型, 表示從 HDKG 中檢索的有向圖。
表示從 HDKG 中檢索的有向圖。
3. 行動控制器(Action Controller)
行動控制器 以當前的視覺觀察 o,以及子目標
以當前的視覺觀察 o,以及子目標 作為輸入,生成行動
作為輸入,生成行動 :
:

4. 經驗驅動的反思器(Experience-Driven Reflector)
經驗驅動的反思器會定期被啟動,以當前的視覺觀察 o,子目標 ,以及從 AMEP 中檢索的 case
,以及從 AMEP 中檢索的 case  作為輸入,生成反思 r:
作為輸入,生成反思 r:

反思 r 分為三類:COMPLETE 表示當前子目標已完成,可以執行下一子目標;CONTINUE 表示當前子目標未完成,需要繼續執行;REPLAN 表示當前子目標無法繼續執行,需要知識引導的規劃器重新規劃。
實驗結果
本文在開放世界環境 Minecraft 中選取了 67 個長序列任務進行評估,涵蓋木材,石器 ,鐵器,金器,鉆石,紅石,裝備七個任務組。每次執行任務,智能體都隨機在任意環境中,初始裝備為空,這顯著增加了任務的挑戰性。此外,本文還構建了一個人類水平的基線,以評估現有的智能體與人類水平之間的差距。

表 1:Optimus-1 在 7 個任務組上的平均成功率
實驗結果如上表所示,Optimus-1 在所有任務組的成功率都顯著高于先前的方法。廣泛的消融實驗也證明了知識和經驗對智能體執行長序列任務的重要性。

表 2:消融實驗結果。其中,P,R,K,E 分別代表規劃,反思,知識,以及經驗。
值得注意的是,本文還探索了將任務失敗的 case 應用于 in-context learning 所帶來的影響。實驗結果顯示,將成功和失敗的 case 都納入智能體的反思階段,能夠顯著提升任務的成功率。

表 3:對多模態經驗的消融實驗結果。其中,zero,suc,Fai 分別代表 zero-shot,僅使用成功 case,以及僅使用失敗 case。
通用性
雖然基于 GPT-4V 構建的 Optimus-1 性能卓越,但調用商用大模型的成本不容忽視。因此,本文進行了更廣泛的實驗,探索一個重要問題:使用現有的開源多模態大模型構建 Optimus-1,性能表現如何?

圖 3:不同多模態大模型作為 backbone 的性能對比
如上圖所示,在沒有混合多模態記憶模塊的情況下,各種多模態大模型在長序列任務上的表現較差,尤其是在具有挑戰性的鉆石任務組中,成功率接近 0。而在混合多模態記憶模塊賦能下,開源多模態大模型也和 GPT-4V 有了可比的性能。這揭示了混合多模態記憶模塊的通用性。
結論
在本文中,我們提出了混合多模態記憶模塊,由 HDKG 和 AMEP 組成。HDKG 為智能體的規劃階段提供必要的世界知識,而 AMEP 則為反思階段提供精煉的歷史經驗。在此基礎上,我們在 Minecraft 中構建了智能體 Optimus-1。廣泛的實驗結果表明,Optimus-1 在長序列任務中的表現超越了現有的智能體。此外,我們還驗證了混合多模態記憶模塊的通用性,開源多模態大模型在其賦能下,與 GPT-4V 也有可比的性能。