開源數(shù)據(jù)湖方案選型:Hudi、Delta、Iceberg深度對比
目前市面上流行的三大開源數(shù)據(jù)湖方案分別為:delta、Apache Iceberg和Apache Hudi。
其中,由于Apache Spark在商業(yè)化上取得巨大成功,所以由其背后商業(yè)公司Databricks推出的delta也顯得格外亮眼。
Apache Hudi是由Uber的工程師為滿足其內(nèi)部數(shù)據(jù)分析的需求而設計的數(shù)據(jù)湖項目,它提供的fast upsert/delete以及compaction等功能可以說是精準命中廣大人民群眾的痛點,加上項目各成員積極地社區(qū)建設,包括技術細節(jié)分享、國內(nèi)社區(qū)推廣等等,也在逐步地吸引潛在用戶的目光。
Apache Iceberg目前看則會顯得相對平庸一些,簡單說社區(qū)關注度暫時比不上delta,功能也不如Hudi豐富,但卻是一個野心勃勃的項目,因為它具有高度抽象和非常優(yōu)雅的設計,為成為一個通用的數(shù)據(jù)湖方案奠定了良好基礎。
很多用戶會想,看著三大項目異彩紛呈,到底應該在什么樣的場景下,選擇合適數(shù)據(jù)湖方案呢?今天我們就來解構(gòu)數(shù)據(jù)湖的核心需求,深度對比三大產(chǎn)品,幫助用戶更好地針對自身場景來做數(shù)據(jù)湖方案選型。
首先,我們來逐一分析為何各技術公司要推出他們的開源數(shù)據(jù)湖解決方案,他們碰到的問題是什么,提出的方案又是如何解決問題的。我們希望客觀地分析業(yè)務場景,來理性判斷到底哪些功能才是客戶的痛點和剛需。
Databricks和Delta
以Databricks推出的delta為例,它要解決的核心問題基本上集中在下圖 :
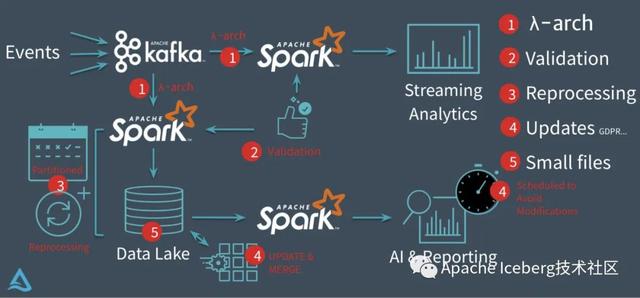
圖片來源:https://www.slideshare.net/databricks/making-apache-spark-better-with-delta-lake
在沒有delta數(shù)據(jù)湖之前,Databricks的客戶一般會采用經(jīng)典的lambda架構(gòu)來構(gòu)建他們的流批處理場景。
以用戶點擊行為分析為例,點擊事件經(jīng)Kafka被下游的Spark Streaming作業(yè)消費,分析處理(業(yè)務層面聚合等)后得到一個實時的分析結(jié)果,這個實時結(jié)果只是當前時間所看到的一個狀態(tài),無法反應時間軸上的所有點擊事件。
所以為了保存全量點擊行為,Kafka還會被另外一個Spark Batch作業(yè)分析處理,導入到文件系統(tǒng)上(一般就是parquet格式寫HDFS或者S3,可以認為這個文件系統(tǒng)是一個簡配版的數(shù)據(jù)湖),供下游的Batch作業(yè)做全量的數(shù)據(jù)分析以及AI處理等。
這套方案其實存在很多問題 :
第一、批量導入到文件系統(tǒng)的數(shù)據(jù)一般都缺乏全局的嚴格schema規(guī)范,下游的Spark作業(yè)做分析時碰到格式混亂的數(shù)據(jù)會很麻煩,每一個分析作業(yè)都要過濾處理錯亂缺失的數(shù)據(jù),成本較大。
第二、數(shù)據(jù)寫入文件系統(tǒng)這個過程沒有ACID保證,用戶可能讀到導入中間狀態(tài)的數(shù)據(jù)。所以上層的批處理作業(yè)為了躲開這個坑,只能調(diào)度避開數(shù)據(jù)導入時間段,可以想象這對業(yè)務方是多么不友好;同時也無法保證多次導入的快照版本,例如業(yè)務方想讀最近5次導入的數(shù)據(jù)版本,其實是做不到的。
第三、用戶無法高效upsert/delete歷史數(shù)據(jù),parquet文件一旦寫入HDFS文件,要想改數(shù)據(jù),就只能全量重新寫一份的數(shù)據(jù),成本很高。事實上,這種需求是廣泛存在的,例如由于程序問題,導致錯誤地寫入一些數(shù)據(jù)到文件系統(tǒng),現(xiàn)在業(yè)務方想要把這些數(shù)據(jù)糾正過來;線上的MySQL binlog不斷地導入update/delete增量更新到下游數(shù)據(jù)湖中;某些數(shù)據(jù)審查規(guī)范要求做強制數(shù)據(jù)刪除,例如歐洲出臺的GDPR隱私保護等等。
第四、頻繁地數(shù)據(jù)導入會在文件系統(tǒng)上產(chǎn)生大量的小文件,導致文件系統(tǒng)不堪重負,尤其是HDFS這種對文件數(shù)有限制的文件系統(tǒng)。
所以,在Databricks看來,以下四個點是數(shù)據(jù)湖必備的:
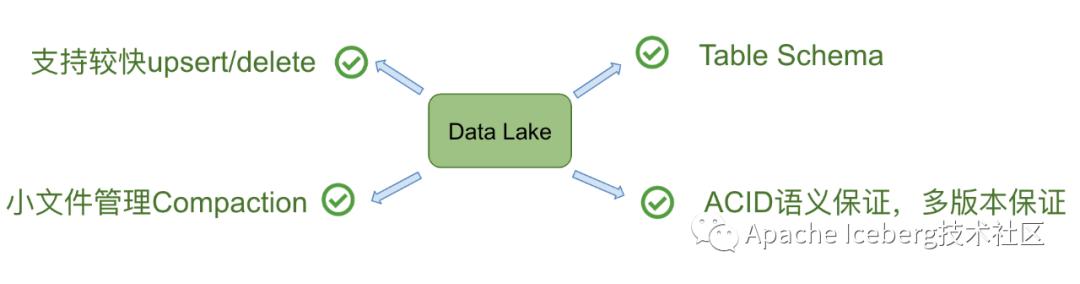
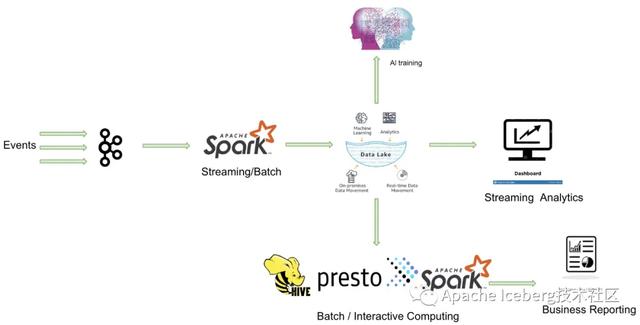
事實上,Databricks在設計delta時,希望做到流批作業(yè)在數(shù)據(jù)層面做到進一步的統(tǒng)一(如下圖)。業(yè)務數(shù)據(jù)經(jīng)過Kafka導入到統(tǒng)一的數(shù)據(jù)湖中(無論批處理,還是流處理),上層業(yè)務可以借助各種分析引擎做進一步的商業(yè)報表分析、流式計算以及AI分析等等。
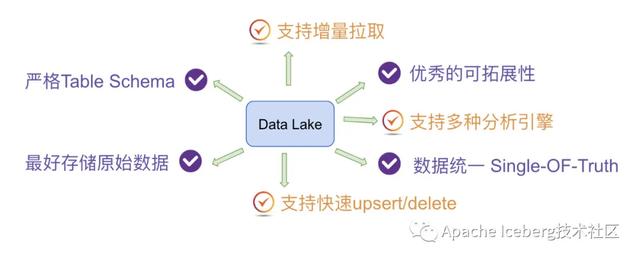
所以,總結(jié)起來,我認為databricks設計delta時主要考慮實現(xiàn)以下核心功能特性:
Uber和Apache Hudi
Uber的業(yè)務場景主要為:將線上產(chǎn)生的行程訂單數(shù)據(jù),同步到一個統(tǒng)一的數(shù)據(jù)中心,然后供上層各個城市運營同事用來做分析和處理。
在2014年的時候,Uber的數(shù)據(jù)湖架構(gòu)相對比較簡單,業(yè)務日志經(jīng)由Kafka同步到S3上,上層用EMR做數(shù)據(jù)分析;線上的關系型數(shù)據(jù)庫以及NoSQL則會通過ETL(ETL任務也會拉去一些Kakfa同步到S3的數(shù)據(jù))任務同步到閉源的Vertica分析型數(shù)據(jù)庫,城市運營同學主要通過Vertica SQL實現(xiàn)數(shù)據(jù)聚合。當時也碰到數(shù)據(jù)格式混亂、系統(tǒng)擴展成本高(依賴收Vertica商業(yè)收費軟件)、數(shù)據(jù)回填麻煩等問題。
后續(xù)遷移到開源的Hadoop生態(tài),解決了擴展性問題等問題,但依然碰到Databricks上述的一些問題,其中最核心的問題是無法快速upsert存量數(shù)據(jù)。
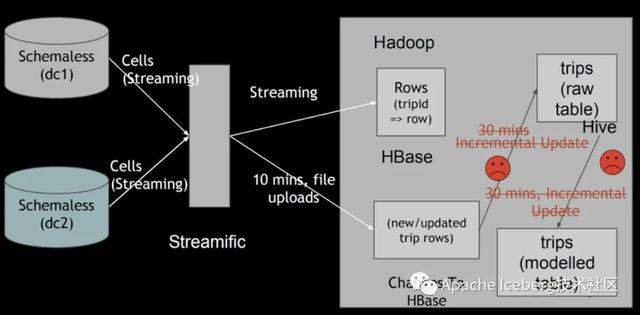
如上圖所示,ETL任務每隔30分鐘定期地把增量更新數(shù)據(jù)同步到分析表中,全部改寫已存在的全量舊數(shù)據(jù)文件,導致數(shù)據(jù)延遲和資源消耗都很高。
此外,在數(shù)據(jù)湖的下游,還存在流式作業(yè)會增量地消費新寫入的數(shù)據(jù),數(shù)據(jù)湖的流式消費對他們來說也是必備的功能。所以,他們就希望設計一種合適的數(shù)據(jù)湖方案,在解決通用數(shù)據(jù)湖需求的前提下,還能實現(xiàn)快速的upsert以及流式增量消費。
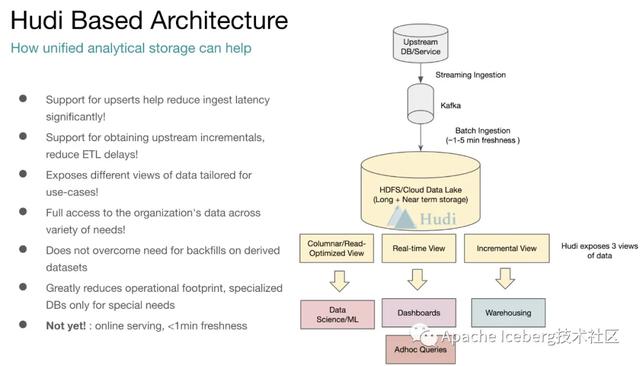
Uber團隊在Hudi上同時實現(xiàn)了Copy On Write和Merge On Read的兩種數(shù)據(jù)格式,其中Merge On Read就是為了解決他們的fast upsert而設計的。
簡單來說,就是每次把增量更新的數(shù)據(jù)都寫入到一批獨立的delta文件集,定期地通過compaction合并delta文件和存量的data文件。同時給上層分析引擎提供三種不同的讀取視角:僅讀取delta增量文件、僅讀取data文件、合并讀取delta和data文件。滿足各種業(yè)務方對數(shù)據(jù)湖的流批數(shù)據(jù)分析需求。
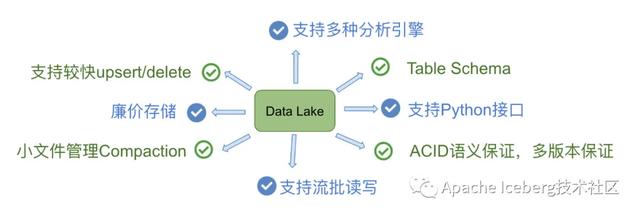
最終,我們可以提煉出Uber的數(shù)據(jù)湖需求為如下圖,這也正好是Hudi所側(cè)重的核心特性:
Netflix和Apache Iceberg
Netflix的數(shù)據(jù)湖原先是借助Hive來構(gòu)建,但發(fā)現(xiàn)Hive在設計上的諸多缺陷之后,開始轉(zhuǎn)為自研Iceberg,并最終演化成Apache下一個高度抽象通用的開源數(shù)據(jù)湖方案。
Netflix用內(nèi)部的一個時序數(shù)據(jù)業(yè)務的案例來說明Hive的這些問題,采用Hive時按照時間字段做partition,他們發(fā)現(xiàn)僅一個月會產(chǎn)生2688個partition和270萬個數(shù)據(jù)文件。他們執(zhí)行一個簡單的select查詢,發(fā)現(xiàn)僅在分區(qū)裁剪階段就耗費數(shù)十分鐘。

他們發(fā)現(xiàn)Hive的元數(shù)據(jù)依賴一個外部的MySQL和HDFS文件系統(tǒng),通過MySQL找到相關的parition之后,需要為每個partition去HDFS文件系統(tǒng)上按照分區(qū)做目錄的list操作。在文件量大的情況下,這是一個非常耗時的操作。
同時,由于元數(shù)據(jù)分屬MySQL和HDFS管理,寫入操作本身的原子性難以保證。即使在開啟Hive ACID情況下,仍有很多細小場景無法保證原子性。另外,Hive Metastore沒有文件級別的統(tǒng)計信息,這使得filter只能下推到partition級別,而無法下推到文件級別,對上層分析性能損耗無可避免。
最后,Hive對底層文件系統(tǒng)的復雜語義依賴,使得數(shù)據(jù)湖難以構(gòu)建在成本更低的S3上。
于是,Netflix為了解決這些痛點,設計了自己的輕量級數(shù)據(jù)湖Iceberg。在設計之初,作者們將其定位為一個通用的數(shù)據(jù)湖項目,所以在實現(xiàn)上做了高度的抽象。
雖然目前從功能上看不如前面兩者豐富,但由于它牢固堅實的底層設計,一旦功能補齊,將成為一個非常有潛力的開源數(shù)據(jù)湖方案。
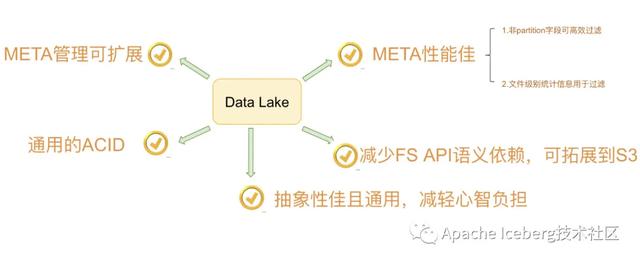
總體來說,Netflix設計Iceberg的核心訴求可以歸納為如下:
痛點小結(jié)
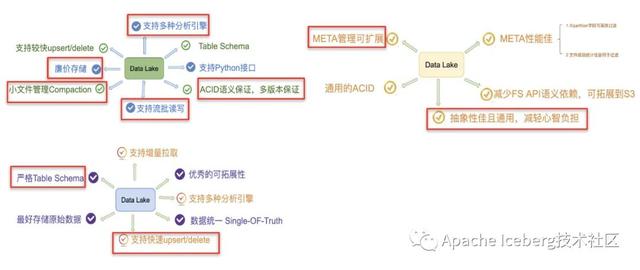
我們可以把上述三個項目針對的痛點,放到一張圖上來看。可以發(fā)現(xiàn)標紅的功能點,基本上是一個好的數(shù)據(jù)湖方案應該去做到的功能點:
七大維度對比
在理解了上述三大方案各自設計的初衷和面向的痛點之后,接下來我們從7個維度來對比評估三大項目的差異。通常人們在考慮數(shù)據(jù)湖方案選型時,Hive ACID也是一個強有力的候選人,因為它提供了人們需要的較為完善功能集合,所以這里我們把Hive ACID納入到對比行列中。
第一、ACID和隔離級別支持
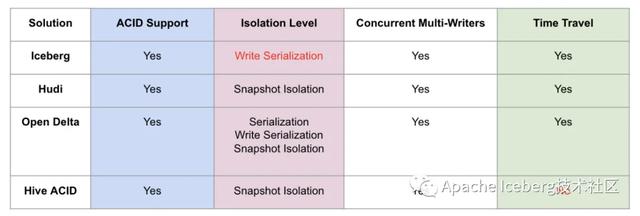
這里主要解釋下,對數(shù)據(jù)湖來說三種隔離分別代表的含義:
- Serialization是說所有的reader和writer都必須串行執(zhí)行;
- Write Serialization: 是說多個writer必須嚴格串行,reader和writer之間則可以同時跑;
- Snapshot Isolation: 是說如果多個writer寫的數(shù)據(jù)無交集,則可以并發(fā)執(zhí)行;否則只能串行。Reader和writer可以同時跑。
綜合起來看,Snapshot Isolation隔離級別的并發(fā)性是相對比較好的。
第二、Schema變更支持和設計
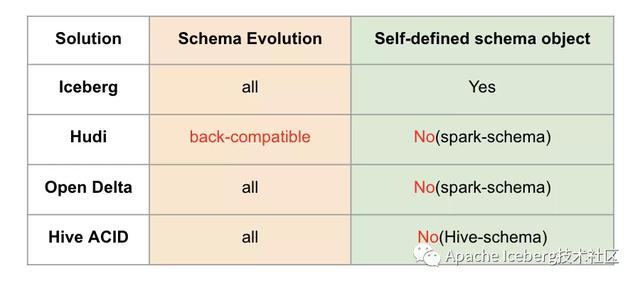
這里有兩個對比項,一個是schema變更的支持情況,我的理解是hudi僅支持添加可選列和刪除列這種向后兼容的DDL操作,而其他方案則沒有這個限制。另外一個是數(shù)據(jù)湖是否自定義schema接口,以期跟計算引擎的schema解耦。這里iceberg是做的比較好的,抽象了自己的schema,不綁定任何計算引擎層面的schema。
第三、流批接口支持
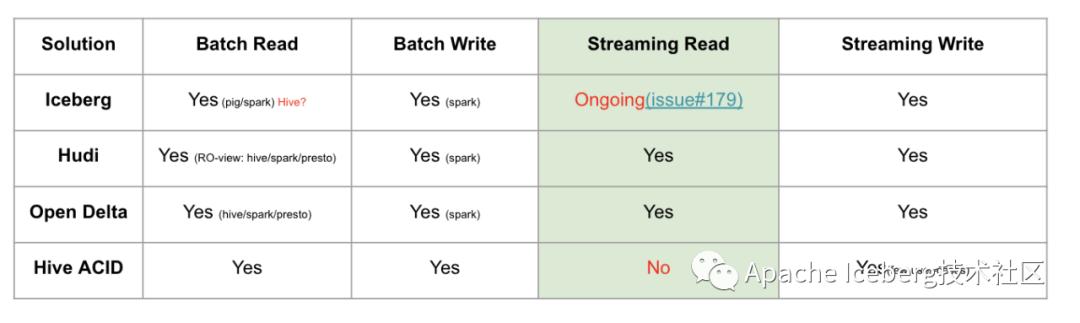
目前Iceberg和Hive暫時不支持流式消費,不過Iceberg社區(qū)正在issue 179上開發(fā)支持。
第四、接口抽象程度和插件化
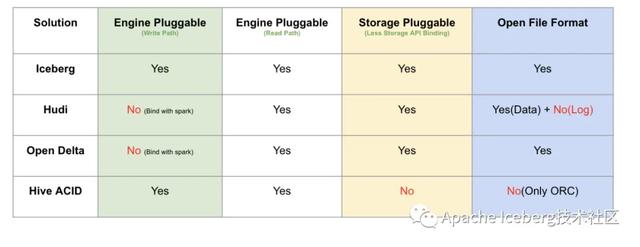
這里主要從計算引擎的寫入和讀取路徑、底層存儲可插拔、文件格式四個方面來做對比。這里Iceberg是抽象程度做得最好的數(shù)據(jù)湖方案,四個方面都做了非常干凈的解耦。delta是databricks背后主推的,必須天然綁定spark;hudi的代碼跟delta類似,也是強綁定spark。
存儲可插拔的意思是說,是否方便遷移到其他分布式文件系統(tǒng)上(例如S3),這需要數(shù)據(jù)湖對文件系統(tǒng)API接口有最少的語義依賴,例如若數(shù)據(jù)湖的ACID強依賴文件系統(tǒng)rename接口原子性的話,就難以遷移到S3這樣廉價存儲上,目前來看只有Hive沒有太考慮這方面的設計;文件格式指的是在不依賴數(shù)據(jù)湖工具的情況下,是否能讀取和分析文件數(shù)據(jù),這就要求數(shù)據(jù)湖不額外設計自己的文件格式,統(tǒng)一用開源的parquet和avro等格式。這里,有一個好處就是,遷移的成本很低,不會被某一個數(shù)據(jù)湖方案給綁死。
第五、查詢性能優(yōu)化
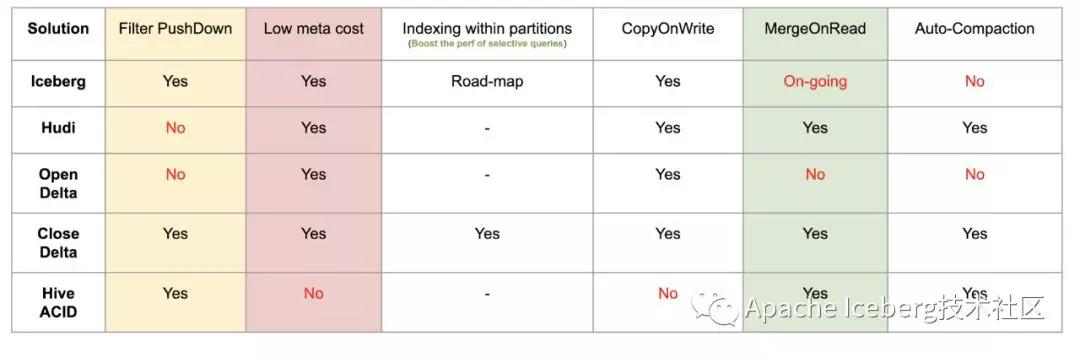
第六、其他功能
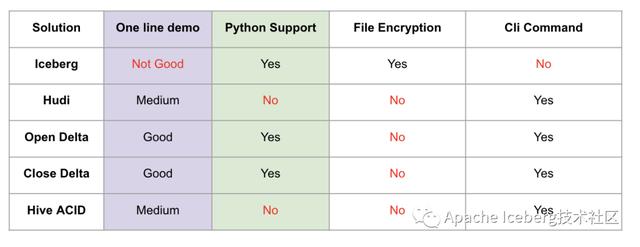
這里One line demo指的是,示例demo是否足夠簡單,體現(xiàn)了方案的易用性,Iceberg稍微復雜一點(我認為主要是Iceberg自己抽象出了schema,所以操作前需要定義好表的schema)。做得最好的其實是delta,因為它深度跟隨spark易用性的腳步。
Python支持其實是很多基于數(shù)據(jù)湖之上做機器學習的開發(fā)者會考慮的問題,可以看到Iceberg和Delta是做的很好的兩個方案。
出于數(shù)據(jù)安全的考慮,Iceberg還提供了文件級別的加密解密功能,這是其他方案未曾考慮到的一個比較重要的點。
第七、社區(qū)現(xiàn)狀(截止到2020-01-08)
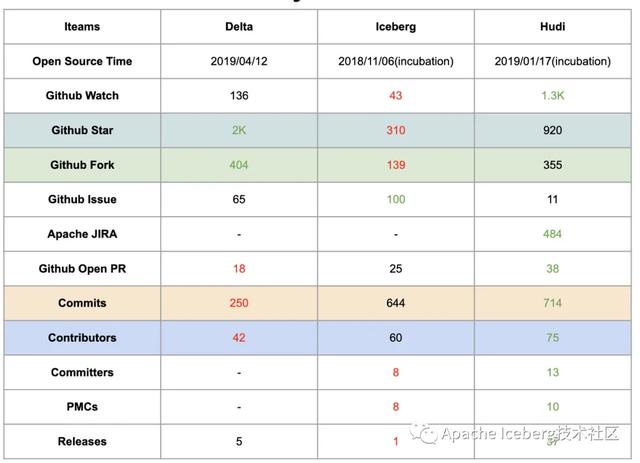
這里需要說明的是,Delta和Hudi兩個項目在開源社區(qū)的建設和推動方面,做的比較好。Delta的開源版和商業(yè)版本,提供了詳細的內(nèi)部設計文檔,用戶非常容易理解這個方案的內(nèi)部設計和核心功能,同時Databricks還提供了大量對外分享的技術視頻和演講,甚至邀請了他們的企業(yè)用戶來分享Delta的線上經(jīng)驗。
Uber的工程師也分享了大量Hudi的技術細節(jié)和內(nèi)部方案落地,研究官網(wǎng)的近10個PPT已經(jīng)能較為輕松理解內(nèi)部細節(jié),此外國內(nèi)的小伙伴們也在積極地推動社區(qū)建設,提供了官方的技術公眾號和郵件列表周報。
Iceberg相對會平靜一些,社區(qū)的大部分討論都在Github的issues和pull request上,郵件列表的討論會少一點,很多有價值的技術文檔要仔細跟蹤issues和PR才能看到,這也許跟社區(qū)核心開發(fā)者的風格有關。
總結(jié)
我們把三個產(chǎn)品(其中delta分為databricks的開源版和商業(yè)版)總結(jié)成如下圖:
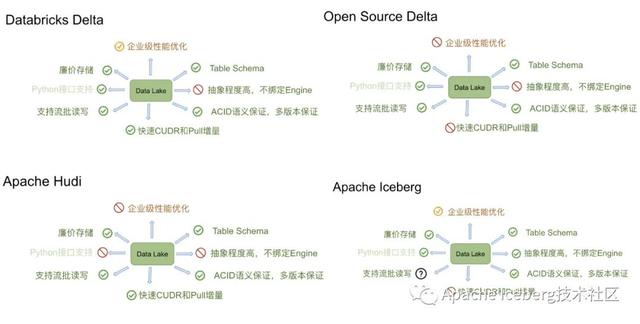
如果用一個比喻來說明delta、iceberg、hudi、hive-acid四者差異的話,可以把四個項目比做建房子。由于開源的delta是databricks閉源delta的一個簡化版本,它主要為用戶提供一個table format的技術標準,閉源版本的delta基于這個標準實現(xiàn)了諸多優(yōu)化,這里我們主要用閉源的delta來做對比。
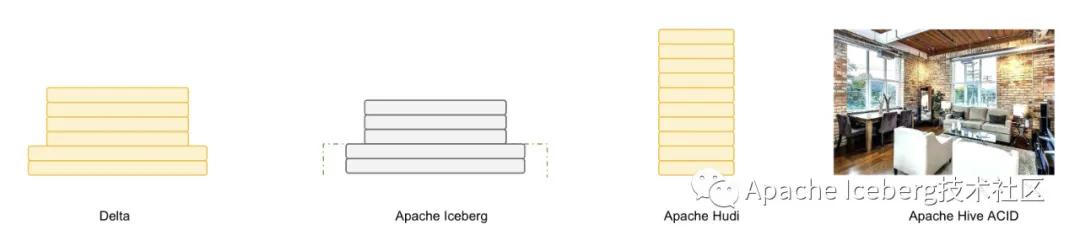
Delta的房子底座相對結(jié)實,功能樓層也建得相對比較高,但這個房子其實可以說是databricks的,本質(zhì)上是為了更好地壯大Spark生態(tài),在delta上其他的計算引擎難以替換Spark的位置,尤其是寫入路徑層面。
Iceberg的建筑基礎非常扎實,擴展到新的計算引擎或者文件系統(tǒng)都非常的方便,但是現(xiàn)在功能樓層相對低一點,目前最缺的功能就是upsert和compaction兩個,Iceberg社區(qū)正在以最高優(yōu)先級推動這兩個功能的實現(xiàn)。
Hudi的情況要相對不一樣,它的建筑基礎設計不如iceberg結(jié)實,舉個例子,如果要接入Flink作為Sink的話,需要把整個房子從底向上翻一遍,把接口抽象出來,同時還要考慮不影響其他功能,當然Hudi的功能樓層還是比較完善的,提供的upsert和compaction功能直接命中廣大群眾的痛點。
Hive的房子,看起來是一棟豪宅,絕大部分功能都有,把它做為數(shù)據(jù)湖有點像靠著豪宅的一堵墻建房子,顯得相對重量級一點,另外正如Netflix上述的分析,細看這個豪宅的墻面是其實是有一些問題的。