大數據Hadoop之—Apache Hudi 數據湖實戰操作
一、概述
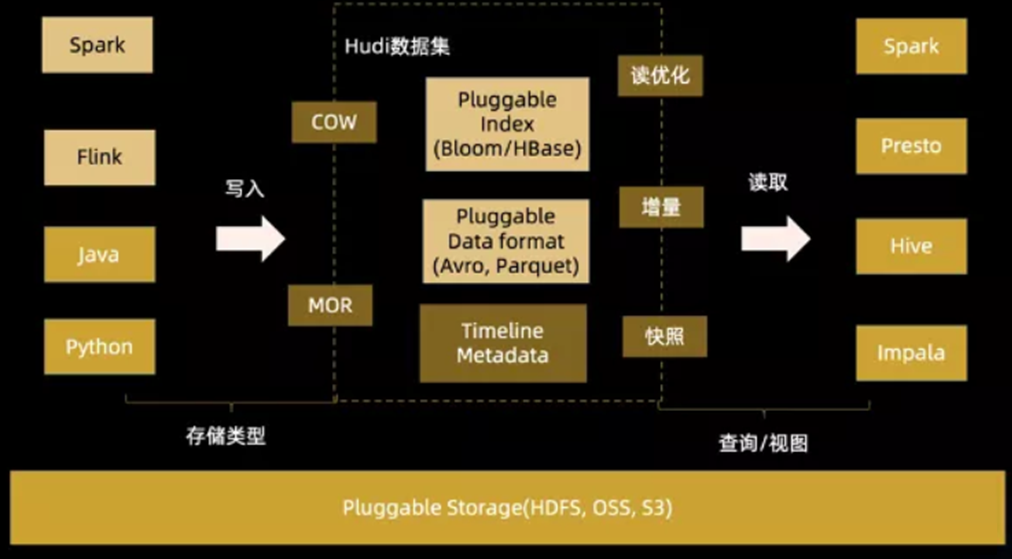
Hudi(Hadoop Upserts Deletes and Incrementals),簡稱Hudi,是一個流式數據湖平臺,支持對海量數據快速更新,內置表格式,支持事務的存儲層、 一系列表服務、數據服務(開箱即用的攝取工具)以及完善的運維監控工具,它可以以極低的延遲將數據快速存儲到HDFS或云存儲(S3)的工具,最主要的特點支持記錄級別的插入更新(Upsert)和刪除,同時還支持增量查詢。
GitHub地址:https://github.com/apache/hudi
官方文檔:https://hudi.apache.org/cn/docs/overview
關于Apache Hudi 數據湖 也可以參考我這篇文章:大數據Hadoop之——新一代流式數據湖平臺 Apache Hudi
二、Hudi CLI
構建hudi后,可以通過cd hudi cli&&./hudi-cli.sh啟動shell。一個hudi表駐留在DFS上的一個稱為basePath的位置,我們需要這個位置才能連接到hudi表。Hudi庫有效地在內部管理此表,使用.hoodie子文件夾跟蹤所有元數據。
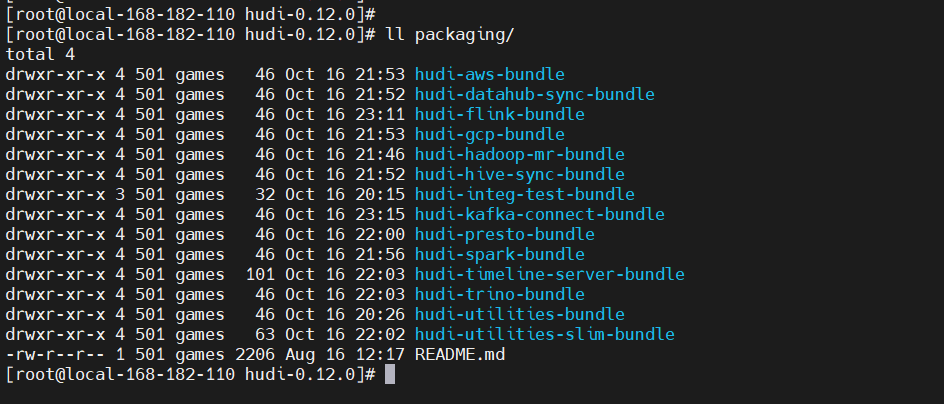
編譯生成的包如下:
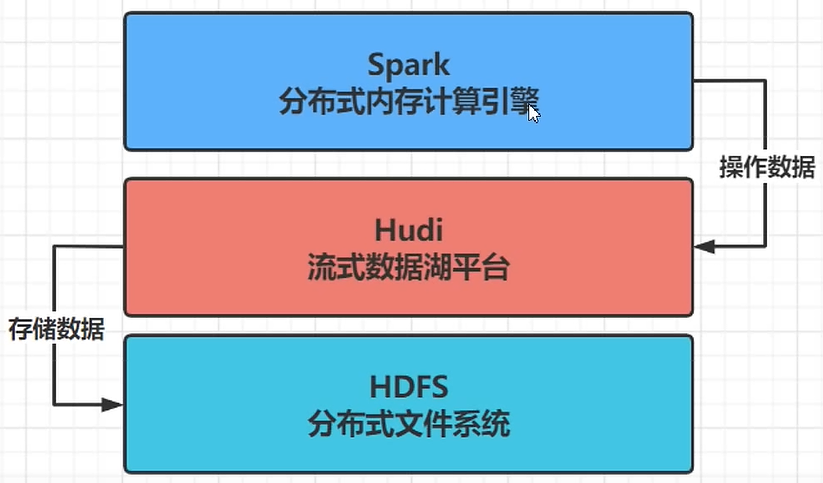
三、Spark 與 Hudi 整合使用
Hudi 流式數據湖平臺,協助管理數據,借助HDFS文件系統存儲數據,使用Spark操作數據。
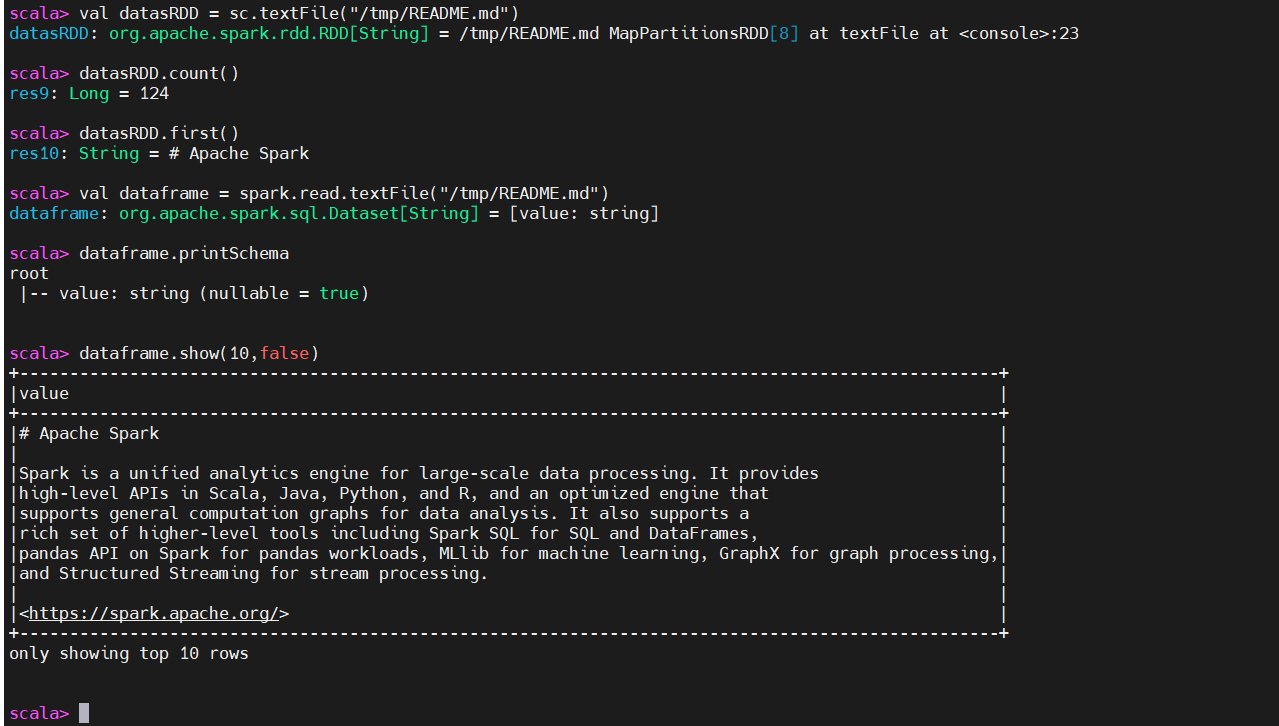
1)Spark 測試
2)Spark 與 Hudi 整合使用
官方示例:https://hudi.apache.org/docs/quick-start-guide/在spark-shell命令行,對Hudi表數據進行操作,需要運行spark-shell命令是,添加相關的依賴包,命令如下:
- 啟動spark-shell
【第一種方式】在線聯網下載相關jar包
【第二種方式】離線使用已經下載好的jar包。
- 導入park及Hudi相關包
- 定義變量
- 模擬生成Trip乘車數據
其中,DataGenerator可以用于生成測試數據,用來完成后續操作。
- 將模擬數據List轉換為DataFrame數據集
- 將數據寫入到hudi
本地存儲
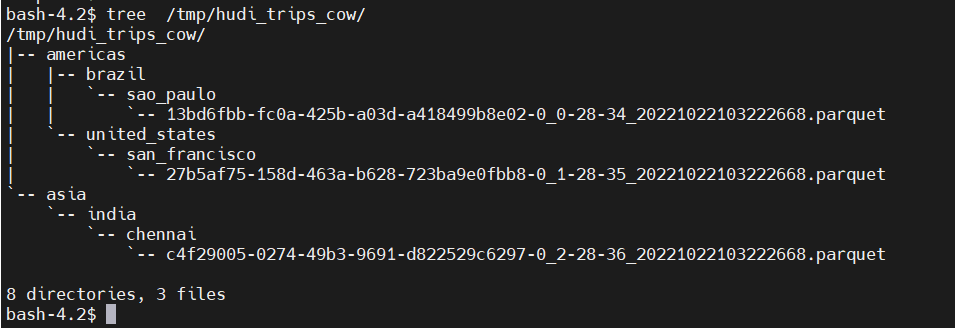
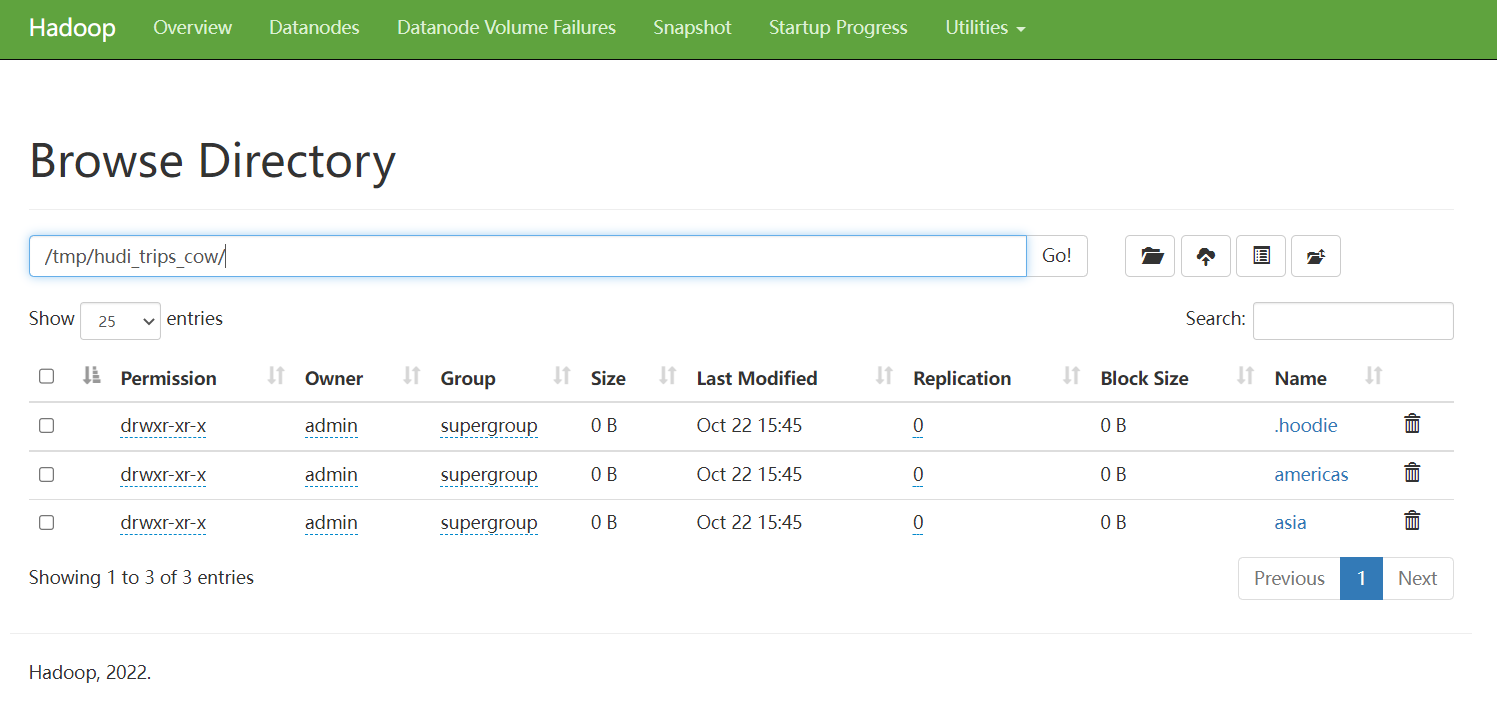
HDFS 存儲
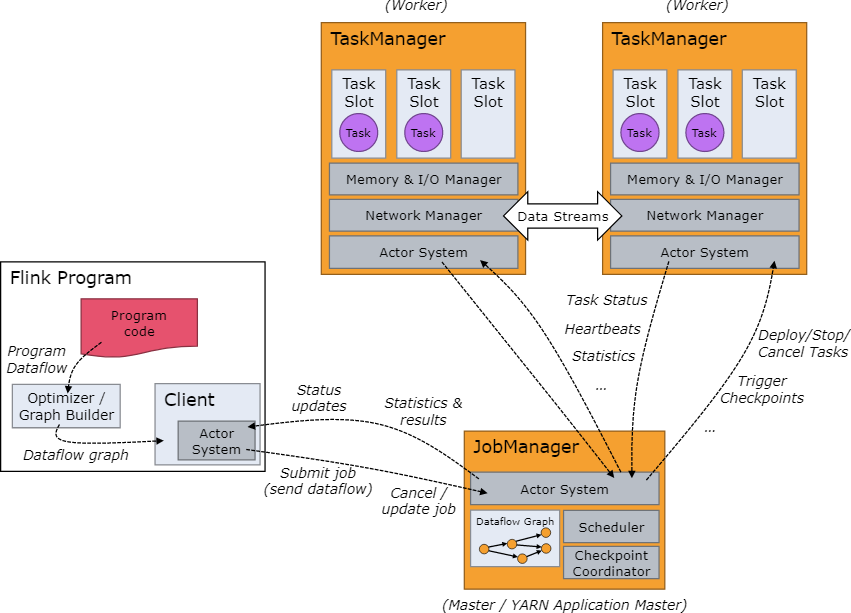
四、Flink 與 Hudi 整合使用
官方示例:https://hudi.apache.org/docs/flink-quick-start-guide
1)啟動flink集群
下載地址:http://flink.apache.org/downloads.html
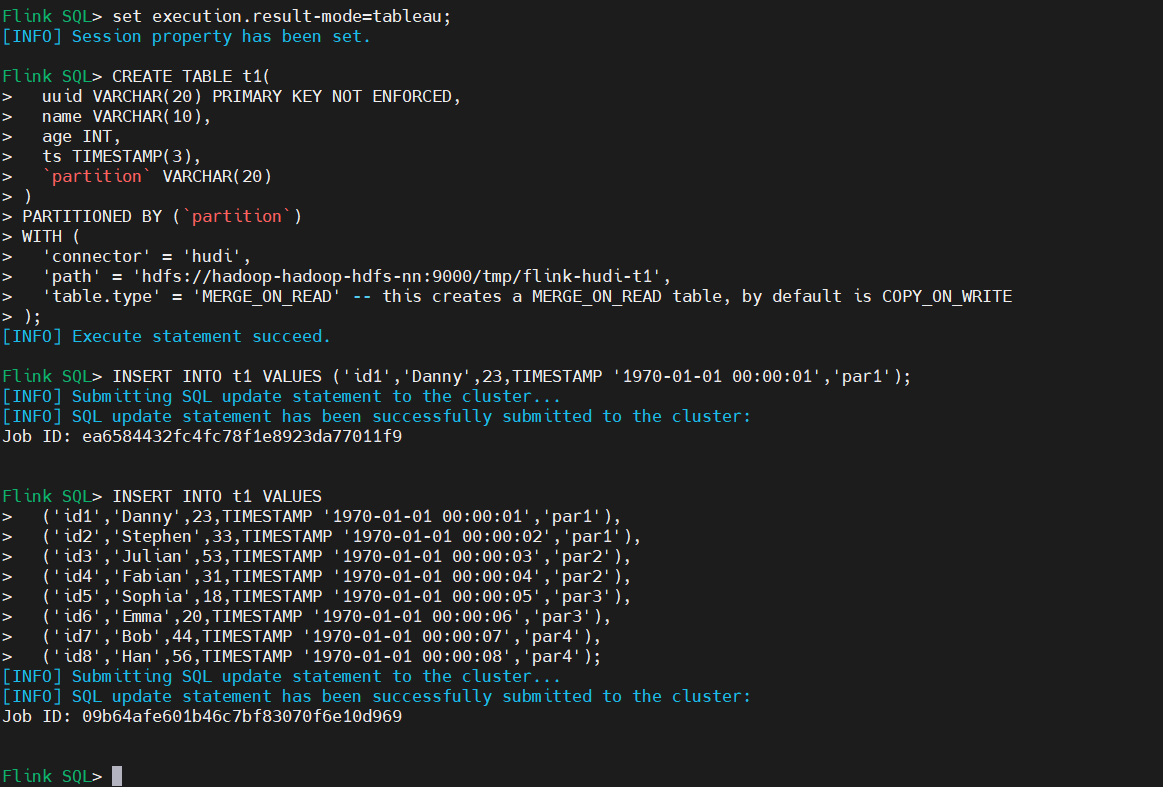
2) 啟動flink SQL 客戶端
3)添加數據
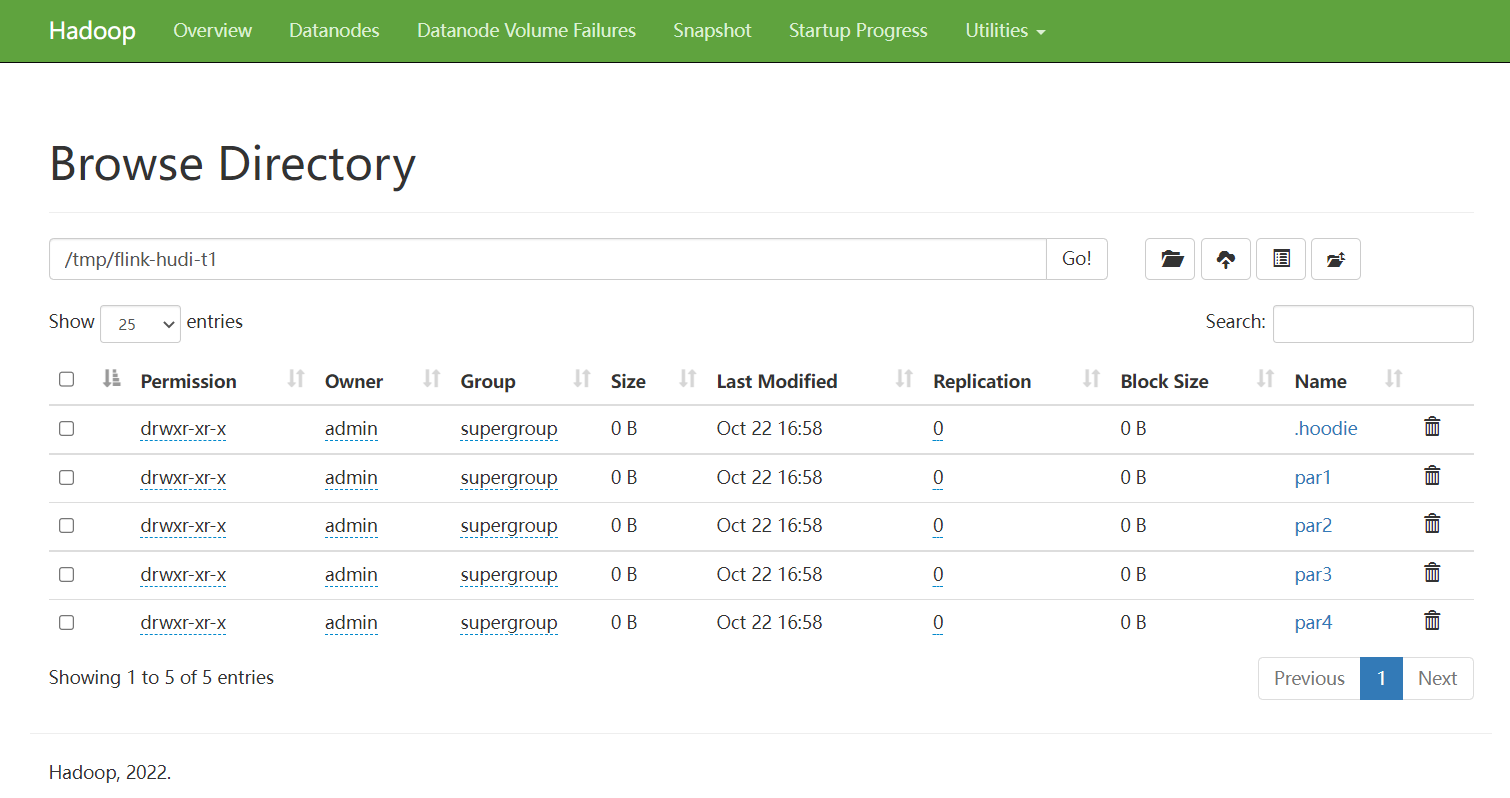
HDFS上查看
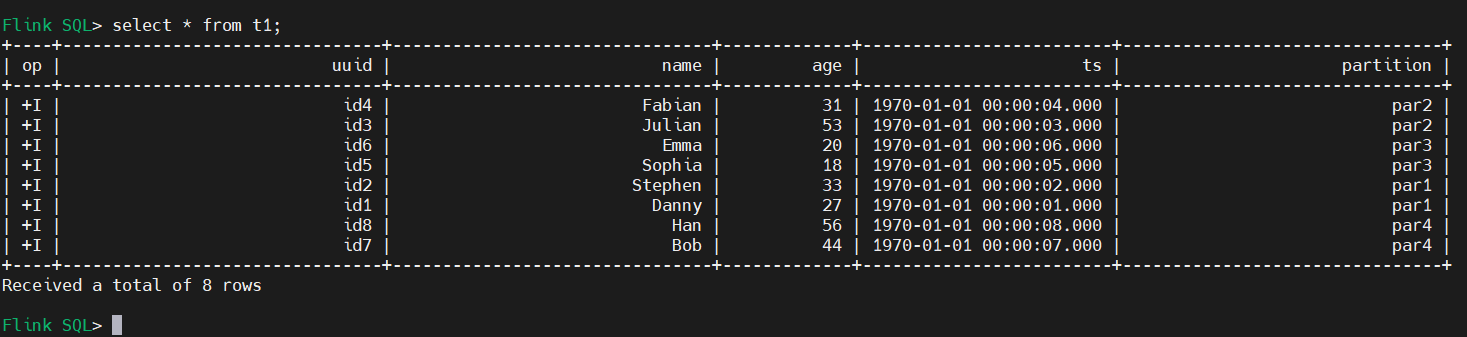
4)查詢數據(批式查詢)
5)更新數據
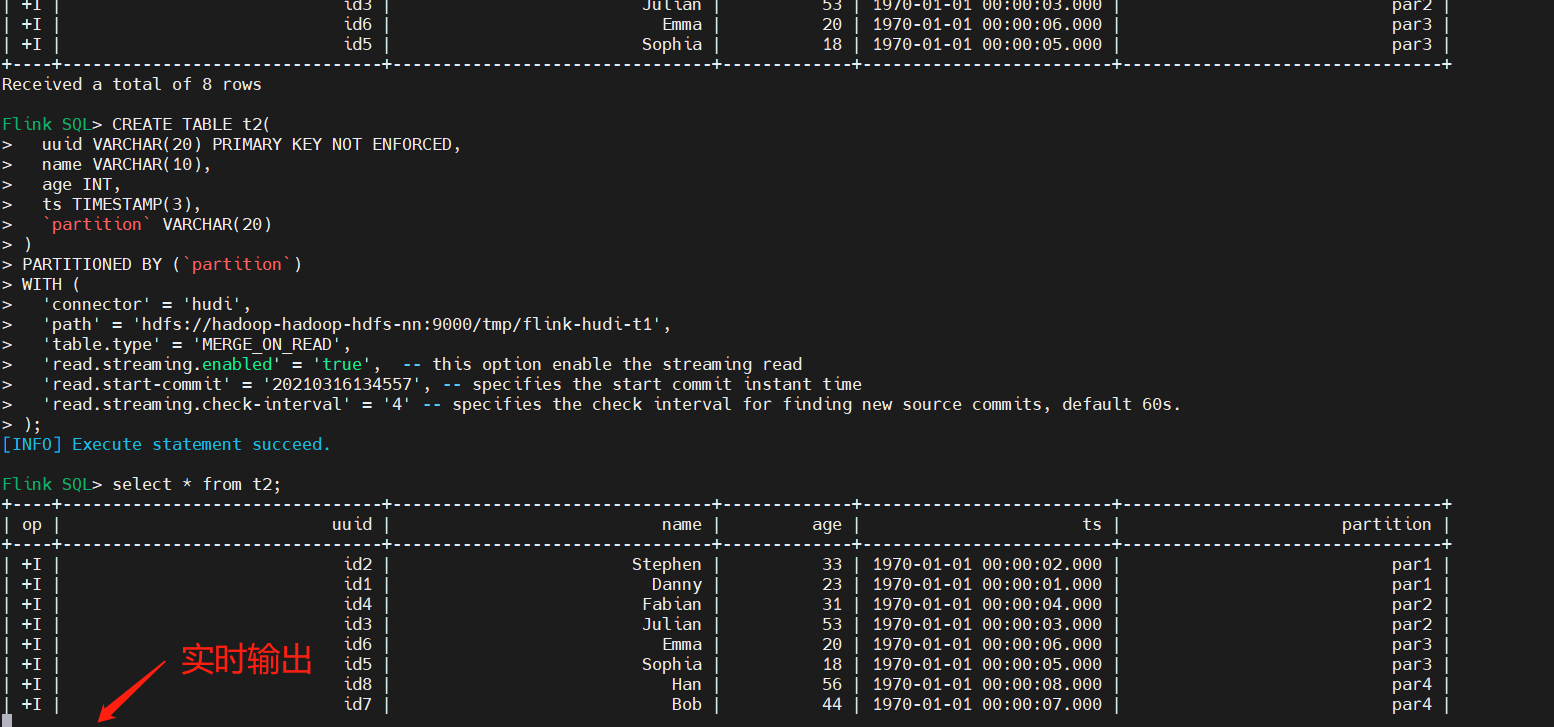
6)Streaming Query(流式查詢)
首先創建表t2,設置相關屬性,以流的方式查詢讀取,映射到上面表:t1。
- read.streaming.enabled設置為true,表明通過streaming的方式讀取表數據;
- read.streaming.check-interval指定了source監控新的commits的間隔時間4s;
- table.type設置表類型為 MERGE_ON_READ;
注意:查看可能會遇到如下錯誤:
[ERROR] Could not execute SQL statement. Reason:
java.lang.ClassNotFoundException:
org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat
【解決】添加hadoop-mapreduce-client-core-xxx.jar和hive-exec-xxx.jar到Flink lib中。