湖倉存儲系統設計剖析和性能優化
一、湖倉系統 阿里云EMR湖倉系統

相較于傳統的數倉、數據湖來講,湖倉系統是一種新的數據管理系統。上圖展示了阿里云EMR湖倉系統的整體架構,它是圍繞著Delta Lake、Iceberg、Hudi等開源數據湖格式構建的,它同時具備數倉的高性能和數據湖的低成本、開放性。這些數據湖格式基于開源的Parquet和ORC構建,能夠在AWS S3、阿里OSS等低成本存儲系統上運行,它還具備ACID事務、批流一體以及Upsert等能力,可以對接多種商業或開源的查詢計算引擎。這些能力使得湖倉體系逐步成為了一種趨勢。
湖倉系統有一定的學習成本,比如合理配置、小文件、清理策略、性能調優等等。下面將從湖倉系統設計上入手,了解三種格式的差異。以Spark計算引擎為例,去分析讀寫計算過程中的一些主要的鏈路和影響性能的關鍵點。
二、核心設計
Delta Lake、Iceberg、Hudi三個數據湖格式在功能、特性、支持程度上基本一致,但是在具體設計上各有利弊和權衡,這些設計形成了支撐湖格式特性的基石,下文將主要分析元數據、MOR讀取這兩塊核心設計。
1、元數據
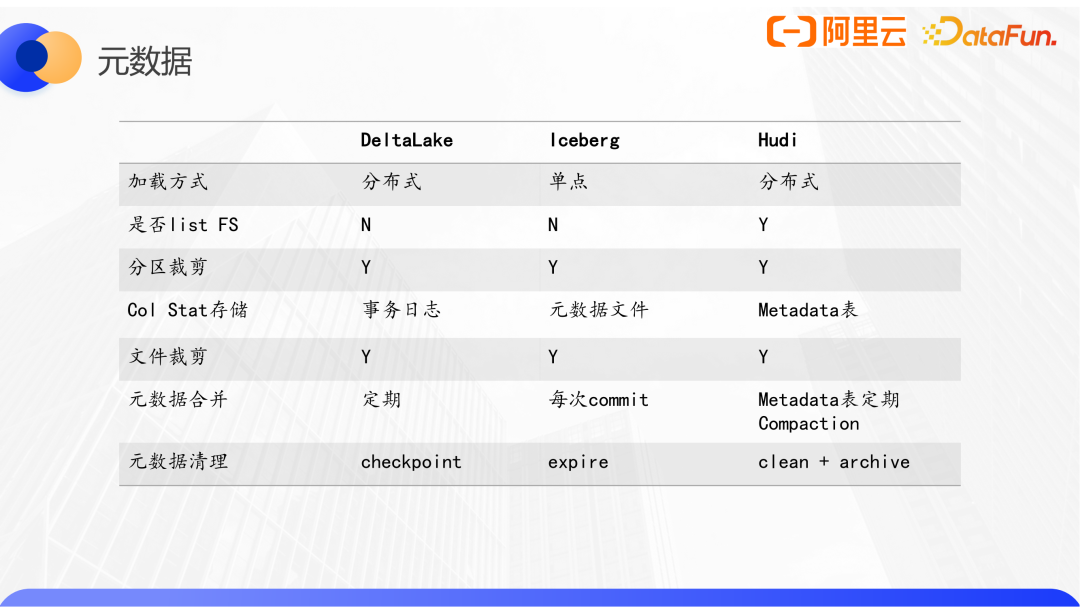
元數據由schema、配置、有效的數據文件列表三個主要部分構成。傳統數倉系統有單獨服務來管理原數據和事務,三個數據湖格式都是將自己的元數據以自定義的數據結構持久化到了文件系統中,放置在表的路徑下,但又和表數據分開存儲。Hive表路徑或分區路徑下的所有數據文件都是有效的,而數據湖格式引入了多版本的概念,所以當前版本的有效數據文件列表需要從元數據中挑選出來。三個湖格式都封裝了自身元數據的加載和更新的能力,這些可以方便的嵌入到不同的引擎,由各個引擎Plan和Execute自己的查詢。
以Spark為例來看看Delta Lake的元數據設計,它的元數據算是三個系統中最簡潔的:每次對Delta Lake的寫操作,或者添加字段等DDL操作,會生成一個新版本的json deltalog文件,這里面會記錄元數據的變更,包含一些schema的配置和file的信息,多次commit之后,會自動產生一個checkpoint的parquet文件,這個parquet文件會包括前面所有版本的元數據信息,用于優化查詢加載。

Delta Lake元數據加載流程:
- 定位最新的checkp元數據文件
- List后面的delta log json文件
- 按版本號依次解析,得到表的schema、配置和有效數據文件列表
Iceberg也有一個統一的元數據集,與Delta Lake不同的是,Iceberg是三層的架構。

其中metadata文件很像Delta Lake的checkpoint文件,包含了全部的信息,但是不同的是,metadata文件還包括了前幾個快照的信息,并且Iceberg是三層架構,其manifest file能夠對局部的數據文件做統計信息收集,因此也能用于分區之下、文件之上的裁剪。
Iceberg元數據加載流程:
- 定位到當前metadata文件,得到表的schema和配置,和當前數據文件快照snapshot的manifest list文件
- 解析manifest list文件,得到一組manifest文件
- 解析manifest文件,得到有效數據文件列表
Hudi和前面兩個很不一樣,其一是它沒有統一的元數據結構,其二Hudi會對數據文件進行分組,并對文件名進行編碼,這是Hudi特有的file group概念。Hudi的數據必須有主鍵,主鍵可以映射到一個file group,后續對于這些主鍵所有的更新,都會寫到這個file group,直到顯式的調用修改表的文件布局。也就是說,一個file group隨著多次的commit,會產生多個版本。獲取當前有效數據文件列表時,會先列出當前分區下的所有文件,按照file group分組,取出每個group的最新文件,再按照timeline篩選掉已經被刪除的group,最后得到一個有效的文件列表。

Hudi元數據加載流程:
- 解析hoodie.Properties
得到表的schema和配置
- 獲取有效文件列表
- 未開啟metadata:List filesystem + timeline
- 開啟metadata:讀取metadata表
Delta Lake、Iceberg、Hude元數據對比如下:
2、Merge-On-Read(MOR)
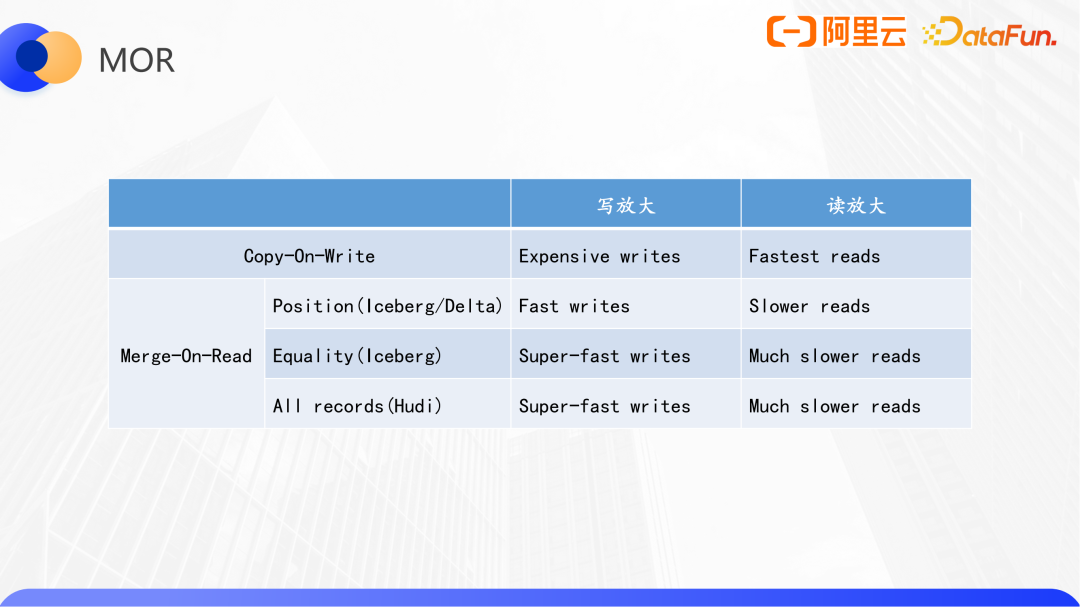
在一般情況下,在更新一個Copy-On-Write表時,即使我們只想執行一條更新操作,也需要將所有涉及到的數據文件加載進來,然后應用更新表達式,再將所有數據一起寫出,這里就包含一些沒有更新的數據,這就是寫放大的現象。為了解決寫放大現象,三個數據湖格式中Hudi第一個實現了Merge-On-Read表。
MOR的設計思想是,只持久化需要寫出的數據,再通過某種方式標識出來,原來的數據文件里的數據成為過期數據,讀的時候進行合并;為了提高效率,會定期進行合并(Compaction),通常是按照Copy-On-Write的方式寫一遍。不同的MOR實現的寫入、合并策略會有所不同。
Hudi定義了一個filegroup概念,每個group包括最多1個原始數據文件和多個日志文件,數據文件運行不存在。
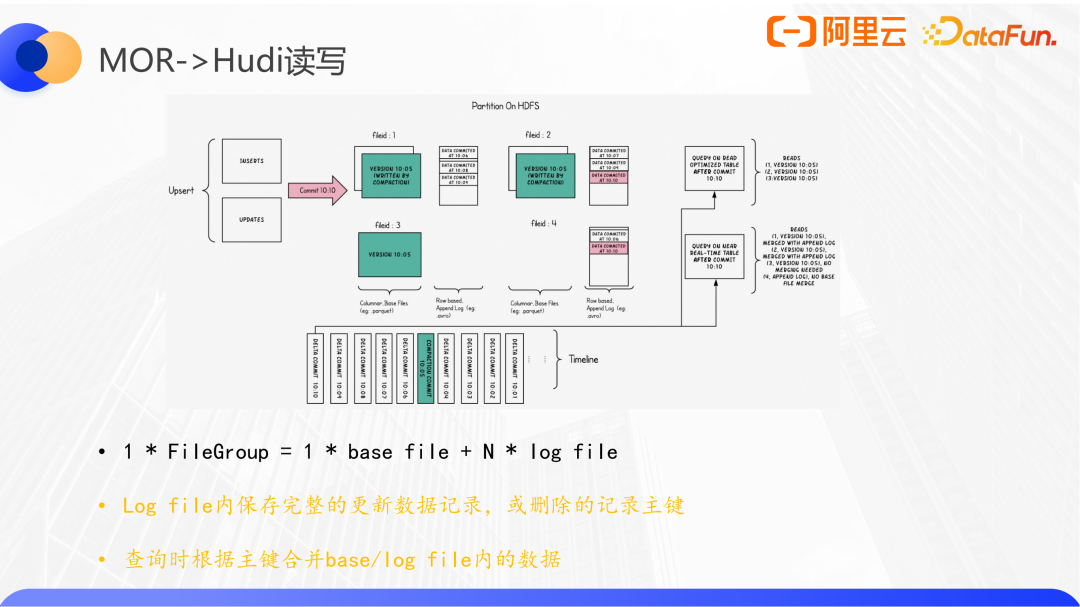
數據通過主鍵映射到filegroup,如果更新數據將會追加寫到映射到filegroup內的日志文件,如果是刪除,則只需要做一個主鍵記錄,在合并的時候,首先讀取原始的數據,然后按照這部分數據的主鍵去判斷在增量日志中有沒有相關的記錄,如果存在就做合并。
Delta Lake通過Deletion Vector的設計解決寫放大的問題。Delta Lake將需要更新、刪除的數據在原數據文件中的offset標識出來,寫入一個輔助文件。Iceberg V2表有兩個MOR的實現,其中基于position的設計和Delta Lake的DV是基本一樣,僅在具體實現上有些區別。DV的寫入僅兩步:1)根據update或者delete的condition,找到文件中匹配的記錄,記錄他們在文件中的offset。持久化到一個bin文件中;2)將更新后的數據,寫到普通的一個新文件中。
相較于Hudi允許存在多個日志文件, Delta Lake在查詢性能做了權衡,一個普通數據文件只允許伴隨至多一個DV文件,當對一個已存在DV文件的數據文件再做一個更新的時候,最終寫出時會把兩個DV合并的。由于DV文件中offset信息是通過位圖(RoaringBitMap)來保存的,合并操作是比較高效的。另外Hudi是將更新的數據也寫入日志文件,Delta Lake是直接寫入普通的parquet文件,然后在bin文件中做一個標記。以及hudi日志文件是行存格式,Delta Lake的DV采用自定義的格式,而數據使用的parquet的列存。

Delta Lake在DV下的查詢方式我們可以直接看LogicalPlan,會更加清晰,即將原本的DeltaScan轉換成Project + Filter + Delta Scan的組合。在Parquet Scan某個數據文件時,追加了_skip_row的輔助字段,上層應用_skip_row = false的過濾,然后通過Project的投影保證僅了無輔助字段的額外輸出。
顯然核心就是_skip_row的標記,DeltaLake自定義了ParquetFileFormat,在讀取parquet文件后,對每個數據判斷roaringBitMap是否包含該offset,有標記為true,沒有就是false。這樣就完成了Deletion Vector模式下DeltaLake表的查詢。
Delta Lake、Hudi、Iceberg的MOR實現對比:
基于offset或者position的MOR實現,由于會通過掃描文件來確定位置,因此寫性能上會慢于iceberg的equality或hudi mor的實現,而由于該方案不需要類似hash join的讀時合并策略,查詢性能會好一些。
三、性能優化
1、查詢
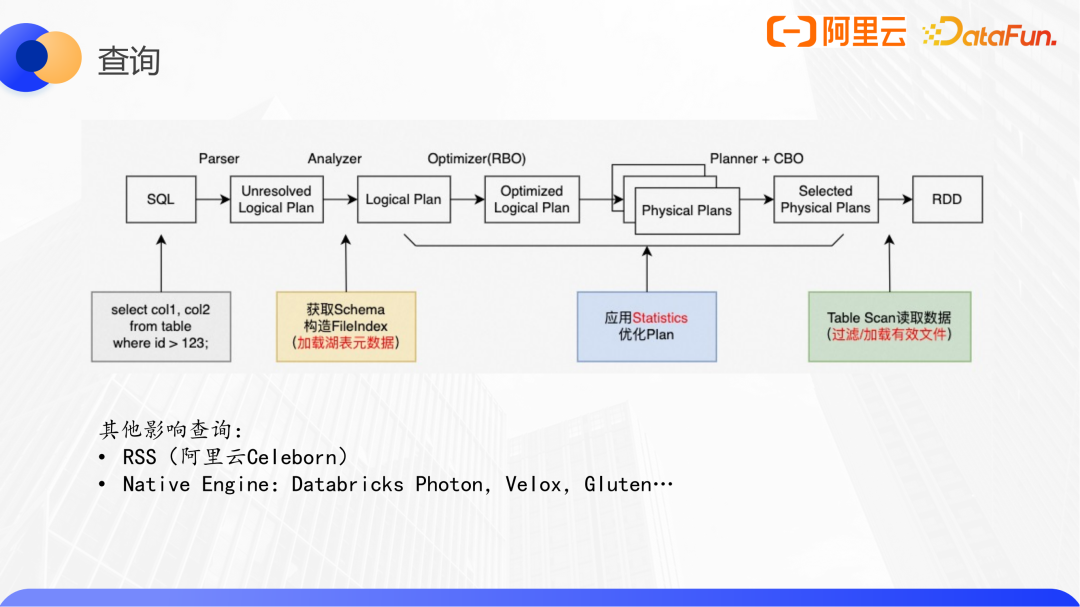
以Spark為例,一個完整的query鏈路如下:
其中與數據湖相關的有三點:元數據加載、優化plan、Table Scan。
(1)元數據加載
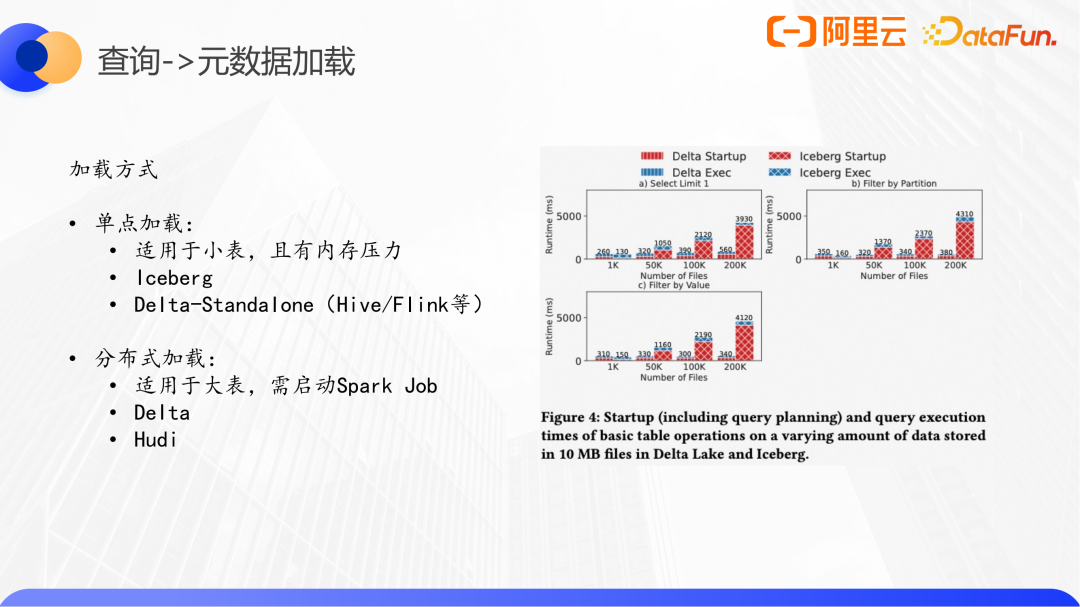
元數據加載包括獲取schema、構造fileindex等,分為單點加載和分布式加載兩種。單點加載的代表有Iceberg、Delta Lake-Standalone,適用于小表,有內存壓力。分布式加載的實現有Hudi、Delta Lake,適用于大表,需提交Spark Job。
這里我們給出LHBench做了一個測試結果:使用的是TPC-H的store-sales表,設置的filesize都是10MB,單個圖表內表的文件數量從1千到20W,三個圖表對應的僅讀取一行,讀取一個分區,和普通字段作為過濾條件的三個場景。從趨勢上三個場景是一致的。我們分析第一個,最左側小表Iceberg的單點模式要稍好些,但與Delta Lake的分布式元數據加載差距不大。最右側單點方式整個Query的執行時間中藍色執行部分基本一致,很明顯被紅色startup部分限制,這部分在plan是一致的情況下可等同于元數據加載的時間。可見,如何智能的選擇合適的加載模式,是一個可選的優化方向。
以下是兩個EMR的優化案例。
案例1:EMR Manifest,是一個無服務化的優化元數據加載方案。
阿里云EMR一客戶的核心ODS表,通過Spark Streaming寫入Delta Lake,每天增量數據3TB,目前全表2.2PB,1500萬個數據文件,僅元數據10GB。在正常情況下使用Hive/Presto查詢,使用的Delta-Standalone的單機加載方式,會完全卡住或者需要超高內存。

該優化方案是將數據文件的元數據按照分區結構提前持久化到一個manifest文件,同時記錄manifest的元數據版本。在用戶查詢的時候,根據filter做分區裁剪,直接去讀分區下面的manifest文件,解析出本次查詢的有效數據文件,跳過了所有元數據加載的步驟。如果emr_manifest的版本有滯后,我們也會拿到滯后的元數據,合并得到正確的數據快照。另外manifest文件中還會保存一些size、stats這些信息,會應用于一些文件級別的data-skipping優化。該方案在該表體量僅為300TB時提供,當時需要10GB內存90s加載完整的元數據,優化后可以實現秒級返回,且內存不需要額外調整。
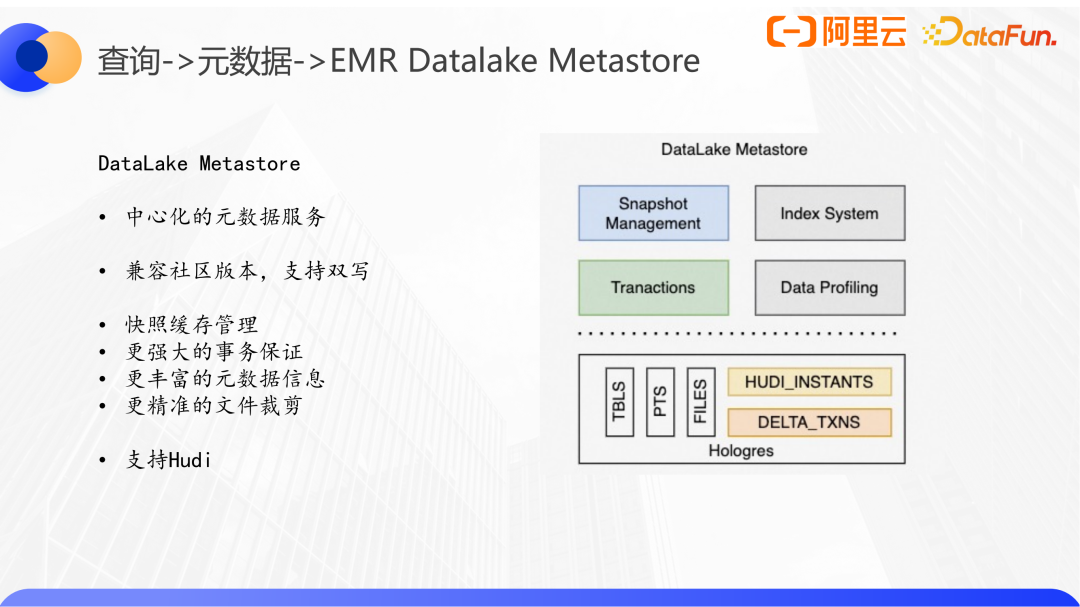
案例2:EMR DataLake Metastore,有服務的中心化的優化元數據加載方案。
這里不得不和HMS做一個對比,HMS僅存儲表的分區級信息,查詢普通表時根據分區位置去list路徑,拿到有效的數據文件列表。而數據湖格式具備多版本概念,所以針對湖格式的Metastore設計必須到文件級別。另外Hudi、Iceberg基于分布式鎖來實現事務性,而Delta則是基于所在文件系統的原子性和持久性,在某些場景下無法提供更強的一致性保障,這也是我們實現DataLake Metastore的另外一個原因。
EMR DataLake Metastore目前已經支持了Hudi格式,完全兼容社區版本和元數據協議,同時支持元數據雙寫。在提供了文件快照和事務的同時,后續也將繼續拓展data profiling和行級索引為查詢提供更精準的裁剪優化。
(2)優化plan
數據湖的第二點優化是plan優化,在前面的Spark查詢例子里,調用Spark sql內核結合各種的狀態統計信息去優化logic plan。比如根據運行時的一些統計信息,通過AQE去改變join的方式,基于表的靜態信息和一些cost模型來優化的CBO等。
統計信息只有表級別和column級別兩類,其中表級別有statistics信息包括bytes、rows等信息,字段級別有min、max等。
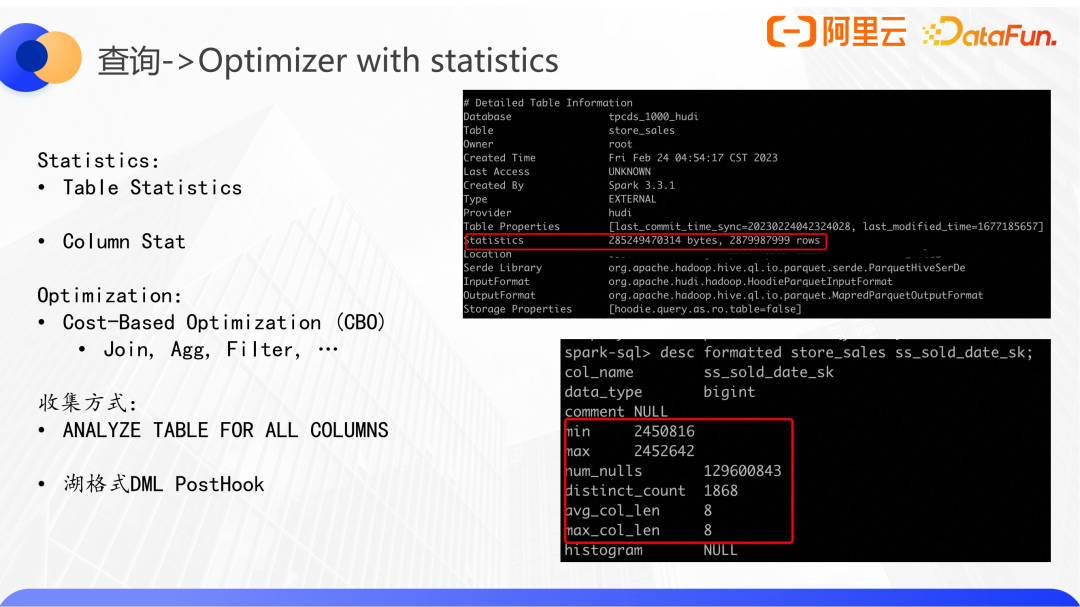
對于一個簡單的join,僅使用表級別的rowcount信息就能夠去調整join順序,使得整體的plan過程中需要join的數據量達到最少。但是如果sql帶有aggregate或者filter,就需要結合列的信息去估算整個scan的cost。
關于通過統計指標來優化查詢,有幾下幾點思考:
- 如何更好的利用statistics來優化查詢。比如Delta Lake中count整表的sql可以直接通過元數據層面的統計信息得到count值,將原本的aggregate操作轉換成LocalRelation,避免Scan全表。
- 如何高效收集/實時更新statistics。
- 如何打通湖格式自身和Spark需要的statistics。spark會從table properties獲取統計信息,而一般情況湖格式的統計信息都是記錄到自己的元數據中,這部分需要更好的打通和復用。
(3)Table Scan
在完整Logical Plan的優化并轉化為Phyiscal Plan后,下一步就要執行具體的數據文件讀取,即Table Scan階段。
這里小文件對查詢的影響是大家所熟悉的。三個湖格式都提供了相應的合并小文件的功能,關鍵問題其一是目標文件設置多大是合適的,其二合并操作執行的時機和方式,這點我們后續再展開。默認情況下parquet在各引擎都是128M左右,但這是否是最優的還要看表的整體規模。過多的文件,將會導致元數據規模變大,影響元數據的讀寫,databricks和阿里云emr都提供了自動調教file size的功能。這里給出databricks的設置文件大小和表規模的映射關系。為了控制元數據的規模,對于10TB的表建議文件大小設置為1G。

在得到表的全部有效數據文件后,我們還是要根據查詢條件來盡可能的進行裁剪,以減少最終讀取Parquet或者ORC文件的體量。Table scan優化分為兩類:一是元數據裁剪,二是行級索引。元數據裁剪又可以分為分區裁剪、Manifest裁剪(Iceberg特有)、File裁剪等不同粒度。

三個數據湖格式都支持Z-Order和DataSkipping:先將min-max信息寫到元數據當中,然后結合查詢過濾條件去實現過濾。
針對點查,傳統數據庫更多是通過行級索引來實現。Databricks商業版Delta Lake支持BloomFilter,使用單獨的目錄文件,保存數據文件的索引信息;Hudi也支持Multi-Modal Index多模索引。EMR也計劃在DataLake Metastore中嵌入Index System來支持點查加速。
最后就是實際的Reader來讀取數據文件了。以Parquet為例,各引擎集成parquet之后,讀寫性能已經非常不錯。但是有一些具體的湖格式場景會關閉一些優化參數,相關的比如謂詞下推,向量化等。另外文件的壓縮格式和壓縮比也會影響文件的加載,以及目前一些Native框架支持的Native Parquet Reader(如Arrow,Presto,Velox等)。
2、寫入
以一個帶where條件的update SQL為例,首先要能找到匹配這些查詢條件的所在的數據文件,然后加載文件,對匹配到的數據應用表達式完成更新,并最終寫出。在完成提交后,也許還要執行一些表的table service,包括clean、checkpoint、compaction等。
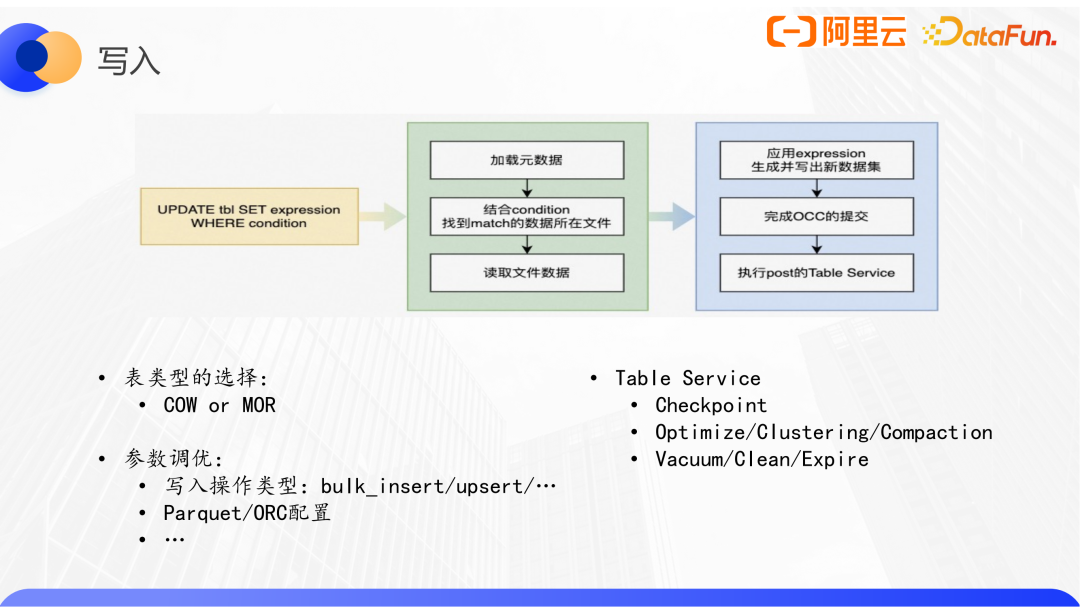
優化寫操作,選擇適合當前場景的表類型(如MOR表),并配置合適的參數。在湖格式場景下,這種后置的追加在湖格式寫入后面的table service其實是逐漸成為了影響效率或者整體作業穩定性的關鍵性因素。要解決這樣的問題,比較通用的做法就是拆成兩個鏈路:一個鏈路就是正常寫入,另外一個鏈路是用離線的方式通過調度一個作業來執行table service任務,包括像clean、Hudi表管理等等。
在阿里云EMR場景下,有些同時使用Flink和Spark引擎的客戶,會采用Flink Hudi入湖和Spark離線管理的方案。另外EMR也提供了中心化的自動化湖表管理,是結合阿里云的DLF服務實現的。如圖所示,湖格式自動將commit信息同步到DLF湖表服務,該服務將根據預定義的策略和實際表的狀態及配置判斷是否要產生湖表管理類的操作。

這里的核心其實是采取怎樣的策略來更好的管理湖表。EMR目前上線了兩大類5個策略。在同一類中,又設置優先級避免多條策略的命中而造成計算資源的浪費。舉個例子,大多數入湖的表是以時間分區的,DLF湖表管理能夠判斷到新分區的到達,而在第一時間對已完成寫入的分區執行小文件合并或者zorder的操作,以便快速提供這部分數據的高效查詢。