數(shù)據(jù)湖 Iceberg 在小米的應(yīng)用

一、Iceberg 核心特性
Iceberg 是具有 SQL 行為的表的開放式標(biāo)準(zhǔn),此定義由 Ryan Blue 提出。這個定義中包含了兩點:
第一點,Iceberg 有 SQL 行為,意味著 Iceberg 是針對于結(jié)構(gòu)化數(shù)據(jù)的,具有結(jié)構(gòu)化數(shù)據(jù)的特性,如 Schema 等。
第二點,Iceberg 是一個開放性的標(biāo)準(zhǔn),開放性標(biāo)準(zhǔn)體現(xiàn)在兩方面。第一方面體現(xiàn)在設(shè)計上,Iceberg 支持多種文件格式,在存儲介質(zhì)上可以選擇各種分布式存儲或者云存儲(如公有云),在上層應(yīng)用上支持了 Flink、Spark、Hive 和 Trino 等多種查詢引擎。第二方面則體現(xiàn)在社區(qū)上,目前已經(jīng)有多家公司參與設(shè)計和建設(shè)。
接下來介紹 Iceberg 的幾個特點。
1、Iceberg 可以避免意外發(fā)生
Iceberg 表可以放心使用,無需考慮太多不愉快的事情發(fā)生。
(1)Iceberg 提供了事務(wù)性
對表的任何操作都是原子性操作,同時使用多快照提供了讀寫分離的特性。
(2)Iceberg 提供了 Full Schema Evolution
可以對 Iceberg 表進行 Schema 修改,比如字段類型提升、增加列、刪除列、重命名列、調(diào)整列順序等。這里需要說明的是,字段類型不是可以隨意更改的,Iceberg 只支持字段類型提升。例如,int 改成 long,float 改成 double,或者精度增大等。
2、Iceberg 支持隱式分區(qū)
Iceberg 有多種分區(qū)函數(shù)供選擇,如下圖所示。當(dāng)我們需要根據(jù)某個 timestamp 類型的字段提取出的年、月、日或者小時進行分區(qū)時,可以直接使用 Iceberg 提供的分區(qū)函數(shù)。Iceberg 還支持多級分區(qū),在分區(qū)選擇上具有更高的靈活性。

與 Hive 進行對比,隱式分區(qū)體現(xiàn)在:
(1)Iceberg 寫入時,不需要像 Hive 一樣指定分區(qū),寫入哪個分區(qū)是由 Iceberg 自動管理的。這樣的好處在于,可以保證數(shù)據(jù)分區(qū)是正確的,防止用戶錯誤導(dǎo)致數(shù)據(jù)分區(qū)錯誤。
(2)用戶查詢時,不需要考慮分區(qū)的物理結(jié)構(gòu)。假如一張表使用 date 字段做了分區(qū),用戶查詢時不需要考慮這個字段是進行了月的分區(qū),還是天的分區(qū),只需要按照這個字段進行查詢即可,Iceberg 會自動生成查詢計劃,如下圖所示。

(3)在目錄結(jié)構(gòu)上,Iceberg 具有元數(shù)據(jù)層,通過記錄分區(qū)和文件地址之間的關(guān)系,實現(xiàn)了物理結(jié)構(gòu)和邏輯結(jié)構(gòu)的分離。這樣,可以非常方便地進行 partition evolution 操作。
3、Iceberg 的行級更新的能力
Fomat version 2 中提供了行級更新的能力,在 Iceberg 中使用了兩類文件進行標(biāo)記刪除。第一類是 position delete file,這類文件可以指定文件和行號進行刪除。第二類是 equality delete file,這類文件記錄了被刪除記錄的唯一鍵進行刪除。Iceberg 只是規(guī)定了可以使用這兩類文件進行刪除,但具體由哪一類文件或兩類文件共同使用以達(dá)到刪除目的,是由引擎層來決定的。下圖中是 Flink 引擎實現(xiàn)行級刪除的模式,對當(dāng)前事務(wù)寫入的文件使用 position delete file,而對于之前的事務(wù)寫入的文件會使用 equality delete file 進行刪除。查詢時,使用 Merge On Read 模式,可以得到已經(jīng)刪除成功的結(jié)果。

二、Iceberg 在小米的應(yīng)用場景
本節(jié)介紹 Iceberg 數(shù)據(jù)湖在小米的幾個應(yīng)用。
1、日志入湖場景
小米原有的日志入湖的數(shù)據(jù)鏈路如下圖所示,用戶會在 Client 端使用 MQ 的 SDK,將數(shù)據(jù)發(fā)送到 MQ 中。小米使用 Talos 作為 MQ,對標(biāo)于業(yè)界的 Kafka,MQ 中沒有 Schema。之后使用 Spark streaming 將文件直接 flush 到 HDFS 上,然后使用 add partition 掛載到 Hive 上。

這個鏈路的特點是:
(1)使用了舊版本的 Spark streaming,實現(xiàn)的是 at least once 語義,數(shù)據(jù)可能會出現(xiàn)重復(fù)。
(2)由于 MQ 當(dāng)中沒有 Schema,只能使用上報的時間進行分區(qū)。這樣,會在凌晨的時候出現(xiàn)分區(qū)漂移的問題。
(3)直接 flush 文件到 Hive 上時,Hive 的 schema 與文件 schema 可能不匹配,導(dǎo)致歷史數(shù)據(jù)讀取時可能會出現(xiàn)問題。
針對以上問題,我們使用 Iceberg 對日志入湖的流程重新進行了設(shè)計,修改后的數(shù)據(jù)鏈路如下圖所示。在 MQ 上配置 Schema,使用 Flink SQL 進行解析,然后寫入到 Iceberg 中。
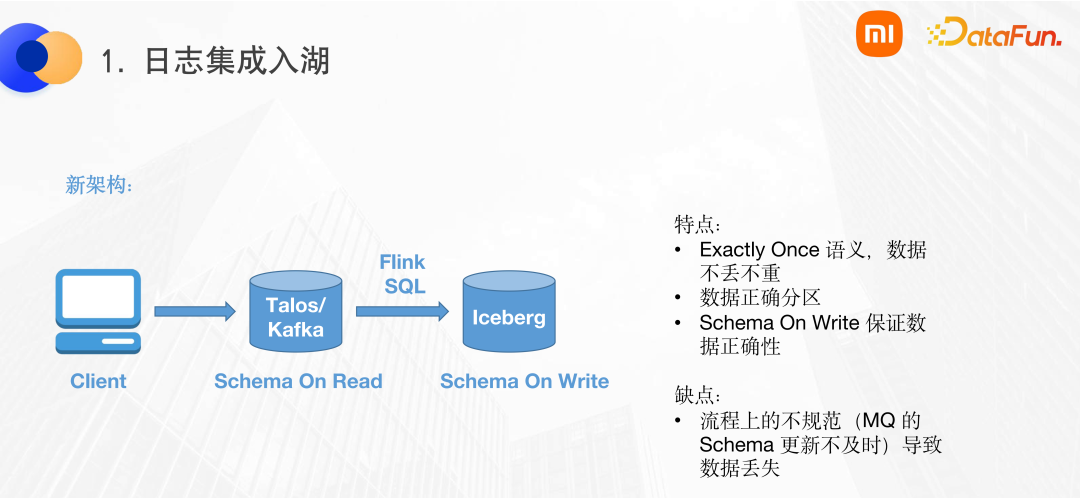
這個數(shù)據(jù)鏈路有以下幾個特性:
(1)使用 Flink SQL 的 exactly once,保證數(shù)據(jù)的不丟不重。
(2)使用了 Iceberg 的隱式分區(qū)特性,保證數(shù)據(jù)分區(qū)的正確性,避免了分區(qū)漂移問題。
(3)Schema On Write 以及 schema evolution 特性,保證數(shù)據(jù)在 schema 演變過程中也永遠(yuǎn)是正確的。
鏈路在實際落地中,可能會出現(xiàn)數(shù)據(jù)丟失的問題。數(shù)據(jù)丟失的根本原因是鏈路上的數(shù)據(jù)不規(guī)范。Talos 使用的 Schema On Read 模式,用戶將 Schema 附加到 MQ 上,在 MQ 到 Iceberg 的過程中,有一個 Schema 同步的過程。但由于 MQ 中的 Schema 人為配置可能延遲,會導(dǎo)致 MQ 的 SDK 發(fā)送的數(shù)據(jù)與 MQ 中 Schema 不一致,使得 FlinkSQL 解析的時候可能會丟掉一些列。最終用戶角度看到的就是數(shù)據(jù)丟失。想要解決這個問題,要在流程中進行規(guī)范,首先定義 Schema,然后發(fā)送數(shù)據(jù)。
2、Flink+ Iceberg 構(gòu)建的近實時數(shù)倉
小米有很多的 IOT 設(shè)備,在這些設(shè)備上打點有兩個痛點問題:
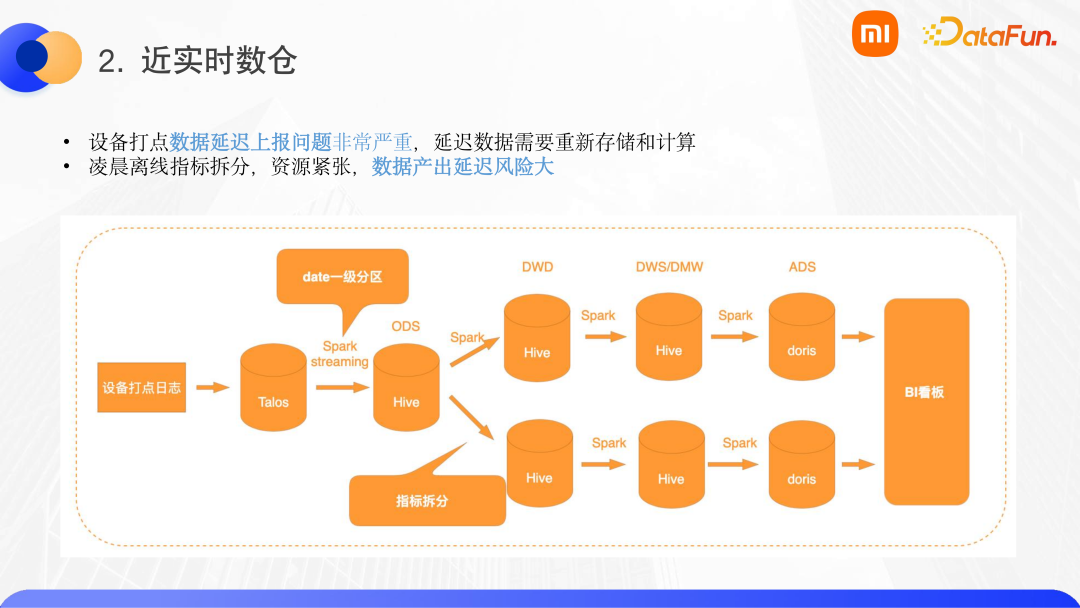
(1)設(shè)備打點數(shù)據(jù)延遲上報問題非常嚴(yán)重。假設(shè)一臺設(shè)備的一批數(shù)據(jù)沒有上報,然后關(guān)機,過了一個月數(shù)據(jù)才上報,那么數(shù)據(jù)開發(fā)工程師需要將過去一個月的數(shù)據(jù)進行重新計算和存儲。由于 Hive 不支持事務(wù)性,那么在進行重新計算然后覆蓋過去一個月的數(shù)據(jù)的過程中,可能會導(dǎo)致下游讀取的異常。
(2)由于 Spark 離線任務(wù)通常都是 T+1 的,所以凌晨時會啟動很多的 Spark 作業(yè)做指標(biāo)拆分,將 ODS 的數(shù)據(jù)拆分到 DWD 層,這會導(dǎo)致集群的資源緊張,數(shù)據(jù)產(chǎn)出的延遲風(fēng)險非常大。
針對這些問題,我們使用了 Flink+Iceberg 對鏈路進行重構(gòu),重構(gòu)后的數(shù)據(jù)鏈路如下圖。

這個鏈路具有以下特點:
(1)首先在入湖側(cè),Iceberg 的隱式分區(qū)可以保證打點延遲的數(shù)據(jù)能夠正確分區(qū),以剛才的例子,一個月之前的數(shù)據(jù)不需要覆蓋寫入,只需要將下游的數(shù)據(jù)進行回溯即可。
(2)結(jié)合 Iceberg 的靈活分區(qū),使用 date+event_name 進行了二級分區(qū)。這樣,下游進行指標(biāo)拆分時,只需要指定二級分區(qū)就可以進行消費,這樣可以大大減少數(shù)據(jù)的掃描量,進而節(jié)省計算資源。
(3)整個鏈路中使用 Flink 來替換 Spark,這對用戶來說非常重要,因為它意味著凌晨的計算量可以平攤到全天,這樣產(chǎn)出延遲的風(fēng)險可以大大降低。分?jǐn)偟饺觳⒉灰馕吨L(fēng)險變高了,相反,F(xiàn)link 的 checkpoint 只有十幾分鐘到半個小時。這樣,即使作業(yè)失敗,恢復(fù)的代價也會比較小。
3、離線場景下遇到的一些問題
Iceberg 的離線場景是比較完善的。但是,若需要數(shù)據(jù)鏈路穩(wěn)定,仍然需要一些努力。
(1)分區(qū)完備性校驗
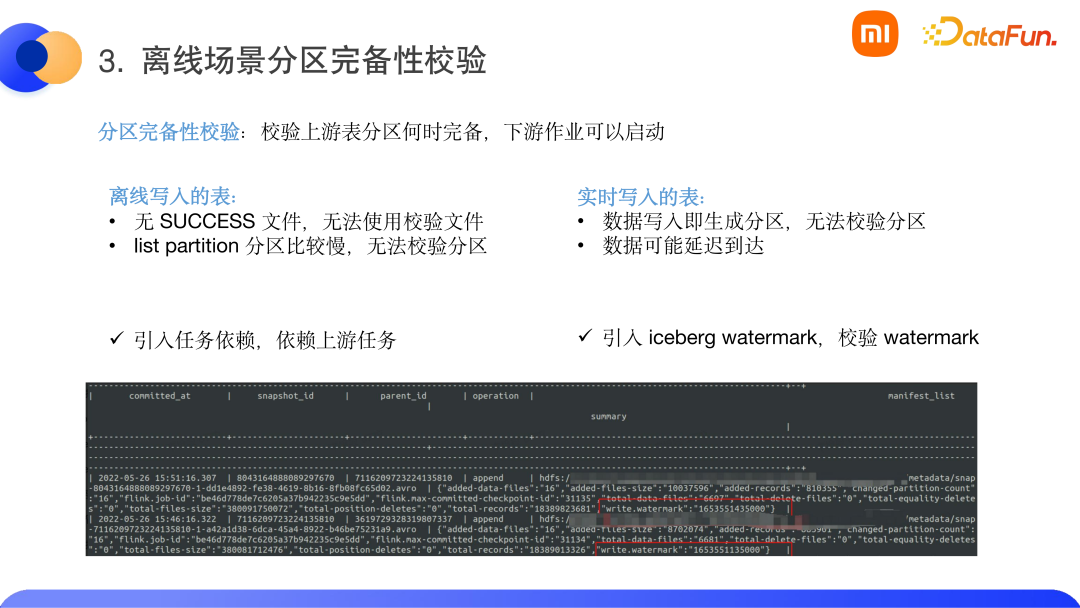
分區(qū)完備性校驗,即如何感知到上游的 T-1 數(shù)據(jù)已經(jīng)寫入完成,從而開啟下游作業(yè)。這里分成兩個場景。
① 離線形式的表,之前 Hive 表的校驗邏輯是校驗 success 文件。但是 Iceberg 寫入并沒有 success 文件。同時 Iceberg 表的分區(qū)散落在各元數(shù)據(jù)文件當(dāng)中,而 list partition 操作非常耗時。針對這一問題,我們使用了任務(wù)依賴,不是使用數(shù)據(jù)依賴來依賴分區(qū)的檢測,而是依賴于上游的任務(wù)。當(dāng)上游任務(wù)寫入完成之后,下游任務(wù)就可以進行調(diào)度。
② 實時寫入的表,Iceberg 表分區(qū)在寫入第一條數(shù)據(jù)時就已經(jīng)生成,這樣也無法校驗分區(qū)。并且,在實時場景下,經(jīng)常會有數(shù)據(jù)延遲到達(dá)的問題。針對這個問題,我們參考了 Flink 的 watermark 機制,使用了 Iceberg 的 watermark,根據(jù)用戶提供的時間列來生成一個時間戳,如下圖所示,我們會在快照里增加一個時間戳,有一個單獨的檢查作業(yè)來對比分區(qū)和 watermark,當(dāng) watermark 超過分區(qū)時,即意味著分區(qū)寫入完成,業(yè)界也稱這種方式為流轉(zhuǎn)批。
(2)離線場景的優(yōu)化
① 試圖將 z-order 應(yīng)用于 ETL,在實踐中,z-order 在整個分區(qū)中執(zhí)行的代價很高。而且,對于 ETL 底層的一些表(如 ODS,DWD),查詢的次數(shù)比較少,z-order 帶來的收益不大。因此,建議用戶使用 local sort 進行排序?qū)懭氲姆绞健?/span>
② 我們在內(nèi)部實現(xiàn)了 parquet 的 page column index,相比 parquet 之前的謂詞下推的方式時 row group 級別的,一個 row group 是 128M 或 256M,而 parquet 最小的可讀單位其實是一個 page,大概是 2MB 左右,page column index 會對 page 建立一個 min-max 索引,查詢時可以利用查詢謂詞和 page 的 min-max 索引來對數(shù)據(jù)進行有效過濾,最終讀入更少量的 page 進行計算,如下圖所示。
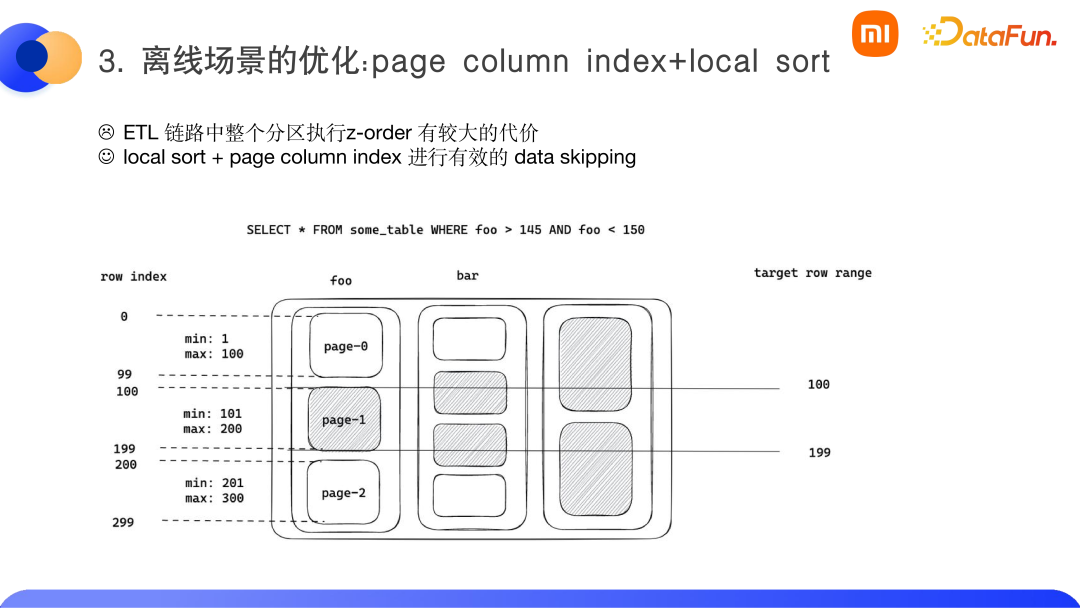
在小米內(nèi)部 benchmark 場景中,效果還是不錯的。最好的情況下,可以過濾 80% 的數(shù)據(jù)。但若查詢的是非排序列,比如下圖的 Q7 到 Q9,基本上沒有什么改善效果。

(3)隱式分區(qū)在離線場景的問題
當(dāng)我們將 Iceberg 引入到離線場景之后,由 Iceberg 自帶的隱式分區(qū)和 dynamic overwrite 帶來的結(jié)果與用戶期望有所不同。例如,假設(shè)表結(jié)構(gòu)中含有四個字段(如下圖所示),我們使用 date 按天分區(qū)之后再使用 hour 按小時分區(qū)。

當(dāng)我們使用語句 insert overwrite catalog.db.table_test values(1,‘a(chǎn)’,20230101,1),(2,‘b’,20230101,2) 進行覆蓋寫入后,會發(fā)現(xiàn)查詢結(jié)果只覆蓋了date=20230101/hour=1和date=20230101/hour=2分區(qū),沒有覆蓋date=20230101/hour=3 的分區(qū)。這意味著 dynamic overwrite 對隱式分區(qū)操作時,不會覆蓋所有的二級分區(qū)。此時,用戶希望回歸到 Hive 的使用方式,解決方法是使用 static overwrite 來指定分區(qū)進行覆蓋。將覆蓋語句修改為:
- set Spark.sql.sources.partitinotallow=static。
- insert overwrite catalog.db.table_test partition(date=20230101) values(1,‘c’, 1), (2,‘d’,2);
(4)Spark timestamp 帶來的問題
Iceberg 類型和多引擎類型的對齊上存在一些問題。如 Iceberg 當(dāng)中的 timestamp 類型有兩類,第一種是帶有時區(qū)的 timestamptz,第二種是無時區(qū)的 timestamp。
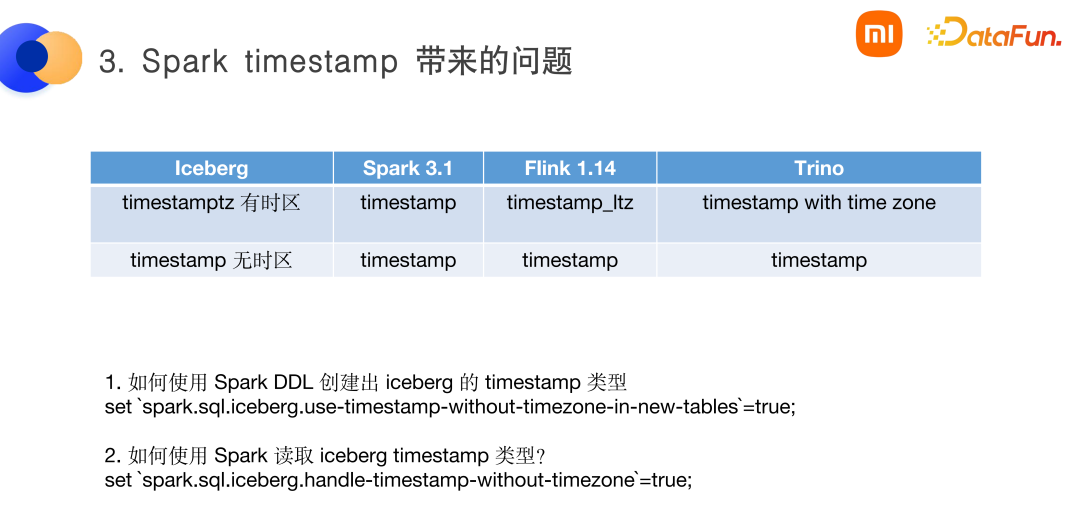
而 Spark 的 timestamp 類型只有一類,即有時區(qū)的 timestamp 類型。這樣就帶來一個問題,如何使用 Spark DDL 來創(chuàng)建出 Iceberg 的無時區(qū)的 timestamp 類型呢?這時需要配置一個參數(shù):
set‘Spark.sql.Iceberg.use-timestamp-without-timezone-in-new-tables’=true
當(dāng)使用Spark來讀取Iceberg timestamp類型時,則需要配置另一個參數(shù):
Set ‘Spark.sql.Iceberg.handle-timestmap-withour-timezone’=true
這時 Spark 會把無時區(qū)的當(dāng)成有時區(qū)的進行處理,也就是說當(dāng)時間戳是 UTC 的 0 點,那么 Spark 讀出來的就已經(jīng)加了 8 個小時了(這里假設(shè)系統(tǒng)時區(qū)為 UTC+8)。這樣用起來似乎也沒什么問題,但是與 Trino 比較起來就有問題了。當(dāng)我們在平臺上同時提供了 Spark 和 Trino 兩種 adhoc 的查詢方式,會發(fā)現(xiàn)結(jié)果是不同的。這個問題在 Spark 3.4 之后應(yīng)該會有所改善,因為設(shè)計中會引入一個新的無時區(qū)的時間戳類型。
4、實時集成入湖
我們將 MySQL、TiDB、Oracle 等關(guān)系型數(shù)據(jù)庫的 binlog 日志采集到 MQ 當(dāng)中,再使用 Flink 寫入到 Iceberg 的 format v2 上,如下圖所示。
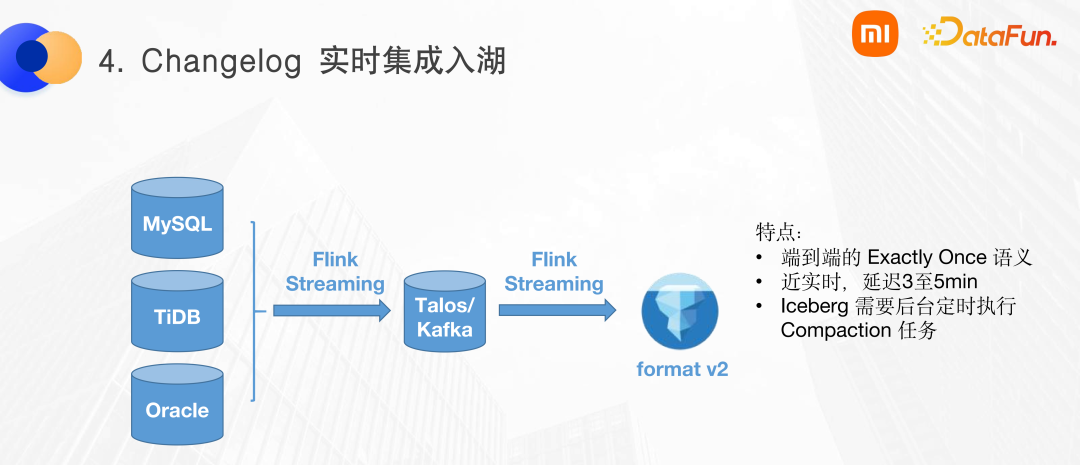
這種數(shù)據(jù)鏈路的特點包括:
(1)整個鏈路借助于 Flink 的 Exactly Once 和 Iceberg 的事務(wù)性,可以到達(dá)一個端到端的 exactly once 的語義。
(2)Iceberg 對實時支持可以達(dá)到分鐘級別。
(3)Iceberg 自身的 merge on read 設(shè)計,需要后臺定時執(zhí)行 compaction 任務(wù)。Iceberg 的 compaction 是一種插件式設(shè)計,到目前還未實現(xiàn)在 Flink 當(dāng)中。目前,當(dāng)需要使用 Flink 進行類似于 HBase 的限流或?qū)懲5炔僮鲿r,尚需自己開發(fā)。假如 Compaction 任務(wù)異常終止,寫鏈路是感知不到的。會造成寫入時沒有問題,但是查詢時速度很慢的現(xiàn)象。
此外,我們在 v2 中發(fā)現(xiàn)更多 Iceberg 存在的問題:
(1)唯一鍵問題:Iceberg 本身并沒有明確說明在表中可以配置一個主鍵,而是將這個權(quán)利交給引擎層去處理。這張表是否可以保證唯一主鍵,完全取決于引擎及使用方式。即使使用了支持聲明主鍵的引擎,也很難保證聲明的主鍵的唯一性。除非默認(rèn)開啟 Upsert 方式,但這種方式代價比較高。
(2)Upsert 問題:Iceberg 的文件組織實現(xiàn)方式的 Upsert 的代價比較高。因為 Iceberg 在設(shè)計時,希望數(shù)據(jù)盡可能入湖且沒有索引,所以不會去校驗這條數(shù)據(jù)是否已經(jīng)存在了。Upsert 的實現(xiàn)方式為 delete+insert 方式,即寫入兩條記錄,一條刪除一條新增。當(dāng)數(shù)據(jù)量比較大時,會導(dǎo)致 equality delete file 文件過多。解決方法有兩種,一是增加 compaction 頻次,二是通過 bloom filter 來過濾掉一些無用的 delete。
(3)并發(fā)沖突問題:實時寫入時,compaction 和寫入會出現(xiàn)并發(fā)沖突,這往往是由于 compaction 過程中,有一條 position delete 數(shù)據(jù)寫入了。這種方式下,F(xiàn)link 是比較友好的,因為 position delete 只會指向一個新增的文件,不會對歷史的文件進行引用。因此在校驗時,可以對 position delete file 在快照中打標(biāo)記,從而忽略由 position delete 帶來的沖突進而導(dǎo)致 compaction 失敗問題。
(4)完整 CDC 問題:Iceberg 與 Hudi 或 Paimon 不同,沒有專門的 changelog 供 Flink 直接消費。我們需要從文件組織中將 changelog 自行解析出來,這樣的解析代價很高,并且可能出現(xiàn)由于 Upsert 操作而帶來的 changelog 不準(zhǔn)確。小米內(nèi)部實現(xiàn)了單事務(wù)中解析出刪除的數(shù)據(jù)和插入的數(shù)據(jù),然后以順序的方式提供給下游消費。但是若單個快照中,先刪后寫的操作過多時,會導(dǎo)致下游波動。Changelog 不準(zhǔn)確(尤其在非主鍵聚合的場景下),是通過配置 changelog CDC 去重來解決的,依賴于 Flink 內(nèi)部的state 撤回的機制來解決,配置語句為:set table.exec.source.cdc-event-duplicate=true。
5、列級數(shù)據(jù)加密
Iceberg 由于元數(shù)據(jù)層的設(shè)計,可以在 Iceberg 表上實現(xiàn)數(shù)據(jù)加密。列級數(shù)據(jù)加密主要是利用了 parquet 1.12.2 高版本的加密能力。之前,小米內(nèi)部的數(shù)據(jù)加密是依賴于隱私集群,單獨的 IDC 機房的隔離會造成運維成本高,以及數(shù)據(jù)孤島的問題。因此我們參照社區(qū)在 Iceberg 上實現(xiàn)了一個數(shù)據(jù)加密,這個方案稱為單層數(shù)據(jù)加密。
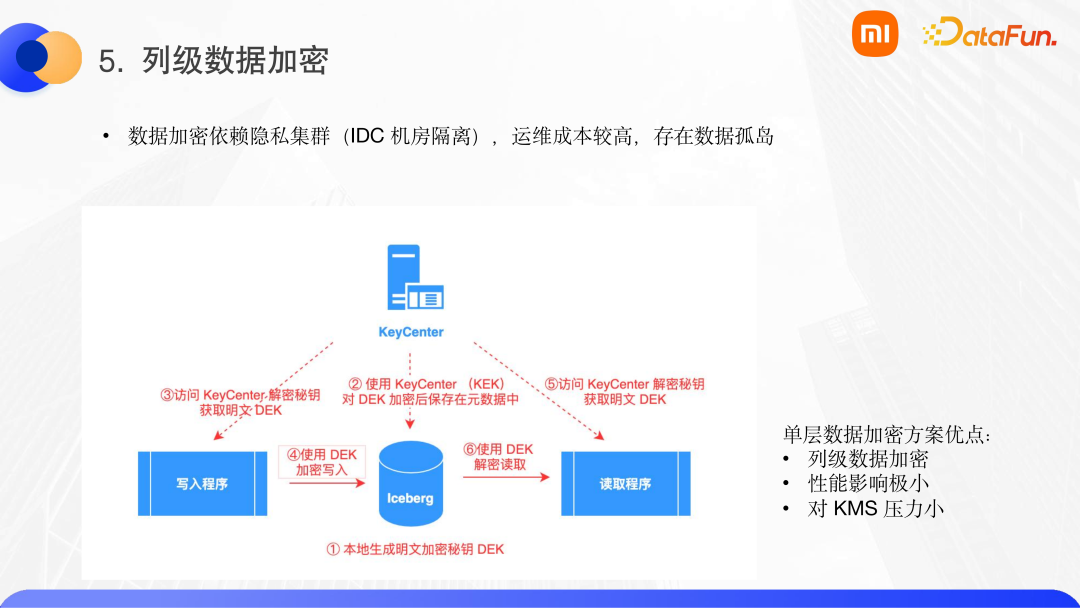
與直接數(shù)據(jù)加密方式不同,直接數(shù)據(jù)加密的每條數(shù)據(jù)的寫入都會調(diào)用一次 KeyCenter 進行加密,然后寫入。單層數(shù)據(jù)加密會在 Iceberg 表中保存加密之后的一個密鑰,當(dāng)寫入程序?qū)懭霑r,會調(diào)用一次 KeyCenter,對加密的密鑰進行一次解密以獲取明文密鑰 DEK,然后對數(shù)據(jù)進行加密寫入。讀取過程與寫入過程類似,讀取時會對 Iceberg 元數(shù)據(jù)中保存的加密密鑰進行解密,進而對數(shù)據(jù)進行解密處理。這里會涉及兩個密鑰,一個是 Iceberg 表自身保存的 DEK,另一個是對這個 DEK 加密的 KeyCenter 中的密鑰。單層包裹的加密方案的優(yōu)點是:
(1)parquet 列級數(shù)據(jù)加密,不需要對所有的列進行加密,用戶可以選擇需要加密的列。
(2)對 KeyCenter 壓力較小,寫入和讀取時只需要對 KeyCenter 訪問有限次數(shù)。
這個方案在小米內(nèi)部實現(xiàn)的是簡化版本,我們會對一個 Iceberg 表維護一個 DEK 密鑰。而社區(qū)的方案中,密鑰粒度比較細(xì),可以是分區(qū)粒度的密鑰,也可以是文件級別的密鑰。
6、Hive 升級 Iceberg 的調(diào)研
(1)方案 1:使用 migrate 原地升級
可以使用社區(qū)提供的 migrate 原地升級的方案進行升級。社區(qū)提供了 Spark 的 procedure 語法,使用 CALL migrate 語法可以直接將 Hive 表升級為 Iceberg 表。下面的例子中,將 Spark_catalog.db.sample 表升級成了 Iceberg 表,同時將新增屬性 foo 為 bar。
CALL catalog_name.db.sample(‘Spark_catalog.db.sample’, map(‘foo’, ‘bar’))
但這種方式在實際落地中存在一些問題:
① Iceberg 支持的文件只有 parquet/orc/avro 這三種格式,不支持 text、sequenceFile 等文件格式。導(dǎo)致一些 Hive 表無法支持升級為 Iceberg 表。
② 表下游消費離線作業(yè)的 Spark 必須是 2.4 以上的版本。而小米內(nèi)部存在一些低版本的 HiveSQL 和低版本的 Spark 作業(yè),因此這部分表是無法使用這個方案進行升級的。
(2)方案 2:復(fù)用 Hive location
出于減少下游作業(yè)的改動的目的,我們希望能夠復(fù)用 Hive 的 location。寫入的時候?qū)懭氲?Iceberg 表,讓 Iceberg 表和 Hive 表的存儲地址相同。這樣我們只需要升級上游作業(yè),下游表在 catalog 層仍然存在,這樣下游作業(yè)不需要改動,如下圖所示。

這個想法是比較好的,但是實現(xiàn)過程有些取巧,因為 Iceberg 是多快照的,因此一個分區(qū)下,可能會有多個副本,而 Hive 是通過 list 目錄來讀取數(shù)據(jù)的。這樣,Hive 在讀取時,可能會讀取到重復(fù)數(shù)據(jù)。若想要讓 Hive 讀取單快照,那只能及時清理 Iceberg 快照和殘留文件。但是這樣又使得 Iceberg 失去了事務(wù)性,而且受限于 Hive 下游消費作業(yè),Iceberg 的一些特性(如 schema evolution)也都受到了限制。若是 Hive 的 parquet 版本和 Iceberg 的 parquet 版本不一致,那么改動會非常大。最終這個方案被放棄。
(3)方案 3:創(chuàng)建新表
這是業(yè)界使用最多的方案,這個方案的思路是:創(chuàng)建一張相同的 Iceberg 表,將 Hive 的歷史數(shù)據(jù)回溯到 Iceberg 當(dāng)中,然后升級上游作業(yè),隨后測試驗證和升級 Hive 的所有下游作業(yè),讓其消費 Iceberg。

為什么這個方案比較麻煩,但是用戶愿意遷移呢?主要有兩個原因:
① 我們在 Iceberg 上使用了 ZSTD 的壓縮算法,得益于 ZSTD 更高的壓縮率,使得存儲成本可以降低 30%。
② 在回溯歷史數(shù)據(jù)的時候,我們對大字符串進行了排序,這樣可以提高數(shù)據(jù)的相似度,進一步提升壓縮率。對一張表來說,存量數(shù)據(jù)在存儲中占有更大的比例。若是能夠?qū)v史數(shù)據(jù)的存儲空間減少 30%,用戶還是可以接受改造的。
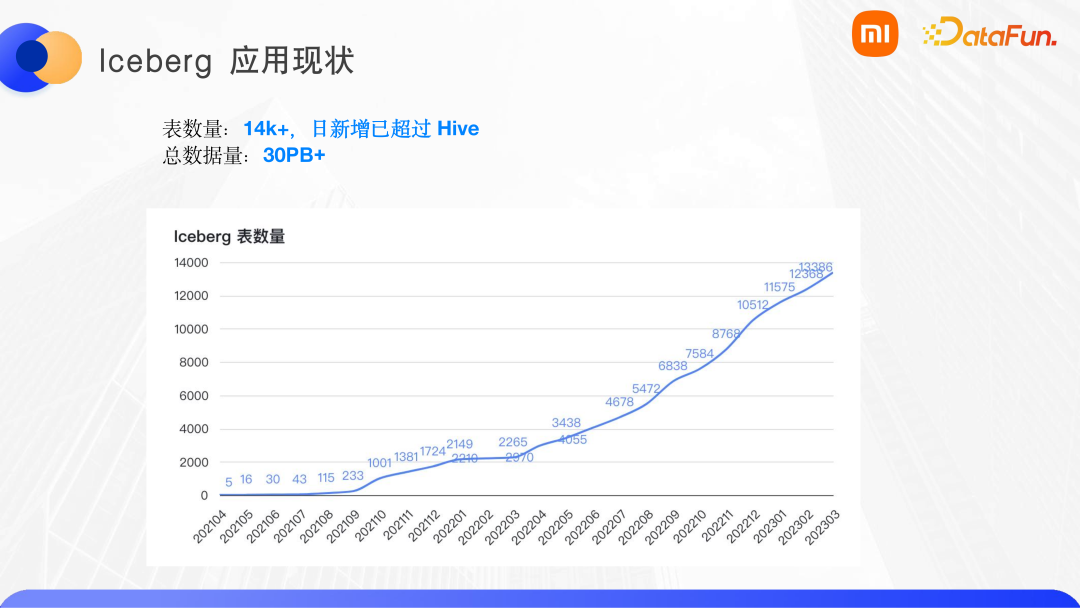
7、Iceberg 在小米的應(yīng)用現(xiàn)狀
目前有 1 萬 4 千多張表,日新增已經(jīng)超過了 Hive,總的數(shù)據(jù)量已經(jīng)達(dá)到 30PB。
三、未來規(guī)劃
首先,我們將跟進物化視圖的功能。在 OLAP 場景且沒有謂詞下推的情況下,我們期望通過預(yù)計算的方式來提高 Iceberg 的查詢能力。
其次,我們將跟進 Iceberg 在 Spark3.3 上的 changelog view。這個功能使得 Spark 可以獲取到 Iceberg 的 changelog,我們希望在離線場景下也可以進行增量讀取和更新。
最后,小米會在海外集群上探索數(shù)據(jù)上云。小米內(nèi)部都是 EBS 掛載,EBS 本身比較貴,而 HDFS 本身有 3 個副本,相比直接使用公有云成本較高。
四、問答環(huán)節(jié)
Q1:為什么要 Spark streaming 切換為 Flink SQL,主要出于什么考慮?
A1:主要是內(nèi)部架構(gòu)考慮。第一是,Spark Streaming 的 2.3 版本的 At least once 語義會導(dǎo)致數(shù)據(jù)重復(fù)。第二是,引入 Flink 之后,開始積極向 Flink 方向靠攏,不再去維護 Spark streaming 的方向,在替換為 Flink SQL 之后,對整個數(shù)據(jù)鏈路進行了迭代。
Q2:watermark 是 Iceberg 已經(jīng)存在的,還是業(yè)務(wù)自己加的?
A2:這個需要業(yè)務(wù)自己配置使用什么字段來作為 watermark 的生成字段,需要用戶自己配置。然后 Flink 在寫入時,會在快照中生成 watermark。
Q3:小米在強實時場景中用到了 Hudi 嗎?
A3:沒有,小米在強實時場景走的 MQ 那套數(shù)據(jù)鏈路。
Q4:選型上為什么是 Iceberg 而不是 Hudi?
A4:最初為使得 kappa 架構(gòu)和 lambda 架構(gòu)得到統(tǒng)一而調(diào)研了數(shù)據(jù)湖的組件,選擇 Iceberg 的主要原因是 Iceberg 的開放性和多引擎支持。2021 年 4 月份,Iceberg 最先支持了 Flink。而當(dāng)時,Hudi 和 Spark 還未解耦。我們出于使用 Flink 的角度而選擇了 Iceberg。實踐中,Iceberg 在實時數(shù)據(jù)的處理中,尤其在 CDC 處理方面,可能沒有 Hudi 那么易用。我們也對 Iceberg 進行了二次開發(fā),才把數(shù)據(jù)鏈路運行得穩(wěn)定一些。
Q5:歷史的離線作業(yè)倉庫,數(shù)倉作業(yè)為 Hive 作業(yè),如果切換到實時鏈路 Iceberg,如何做到無感知切換?比如說,SparkSQL 語法與 FlinkSQL 語法不同,以及 UDF 實現(xiàn)不同。
A5:目前沒有辦法做到無感知切換,SparkSQL 和 FlinkSQL 語義上就不大一樣。若是切換到 Flink batch 還有可能,但若是想要離線切到實時,基本上要把整個邏輯的實現(xiàn)一遍。
Q6:目前實時數(shù)倉當(dāng)中,append 模式和 Upsert 模式的數(shù)據(jù)延時可以做到幾分鐘?盡可能避免數(shù)據(jù)延遲到達(dá)。
A6:這兩種模式,目前最低都是 1 分鐘。 我們約束了用戶配置的 checkpoint 時長,最低不能低于 1 分鐘。
Q7:如何使用 local sort 進行多列查詢?
A7:這個可以寫入時在算法上使用 z-order 排序替換默認(rèn)的排序算法來實現(xiàn)。
Q8:切換 Iceberg 帶來的切換成本是怎樣的,業(yè)務(wù)需求是否很強烈?
A8:Iceberg 帶來的事務(wù)性、隱式分區(qū)、多引擎支持的特性可以切實解決用戶的問題。即使切換過程中有很大的成本,當(dāng)數(shù)據(jù)湖方案確實可以解決用戶的痛點時,用戶也會想用這個新架構(gòu)去替換。