一個模型擊潰12種AI造假,各種GAN與Deepfake都陣亡,已開源
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
AI造出的假圖片恐怕很難再騙過AI了。
連英偉達本月剛上線的StyleGAN2也被攻破了。即使是人眼都分辨看不出來假臉圖片,還是可以被AI正確鑒別。

最新研究發現,只要用讓AI學會鑒別某一只GAN生成的假圖片,它就掌握了鑒別各種假圖的能力。
不論是GAN生成的,Deepfake的,超分辨率的,還是怎樣得來的,只要是AI合成圖片,都可以拿一個通用的模型檢測出來。
盡管各種CNN的原理架構完全不同,但是并不影響檢測器發現造假的通病。
只要做好適當的預處理和后處理,以及適當的數據擴增,便可以鑒定圖片是真是假,不論訓練集里有沒有那只AI的作品。
這就是Adobe和UC伯克利的科學家們發表的新成果。
有網友表示,如果他們把這項研究用來參加Kaggle的假臉識別大賽,那么將有可能獲得最高50萬美元獎金。

然而他們并沒有,而是先在ArXiv公布了預印本,并且還被CVPR 2020收錄。
最近,他們甚至將論文代碼在GitHub上開源,還提供了訓練后的權重供讀者下載。
造出7萬多張假圖
要考驗AI鑒別假貨的能力,論文的第一作者、來自伯克利的學生Wang Sheng-Yu用11種模型生成了不同的圖片,涵蓋了各種CNN架構、數據集和損失。
所有這些模型都具有上采樣卷積結構,通過一系列卷積運算和放大操作來生成圖像,這是CNN生成圖像最常見的設計。

有ProGAN、StyleGAN、BigGAN、BigGAN、GauGAN等等,這些GAN各有特色。
ProGAN和StyleGAN為每個類別訓練不同的網絡;StyleGAN將較大的像素噪聲注入模型,引入高頻細節;BigGAN具有整體式的類條件結構;進行圖像轉換的GauGAN、CycleGAN、StarGAN。
除了GAN以外,還有其他處理圖片的神經網絡:
- 直接優化感知損失 ,無需對抗訓練的級聯細化網絡(CRN);
- 條件圖像轉換模型隱式最大似然估計(IMLE);
- 改善低光照曝光不足的SITD模型;
- 超分辨率模型,即二階注意力網絡(SAN);
- 用于換臉的的開源DeepFake工具faceswap。

主流圖片處理CNN模型應有盡有。他們總共造出了7萬多張“假圖”。
雖然生成這些圖片所用的算法大相徑庭、風格迥異,但是總有會有一些固有缺陷,這里面既有CNN本身的問題,也有GAN的局限性。
這是因為常見的CNN生成的內容降低了圖片的表征能力,而這些工作大部分集中在網絡執行上采樣和下采樣的方式上。下采樣是將圖像壓縮,上采樣是將圖像插值到更大的分辨率上。
之前,Azulay和Weiss等人的研究表明,表明卷積網絡忽略了經典的采樣定理,而跨步卷積(strided convolutions)操作減少了平移不變性,導致很小的偏移也會造成輸出的極大波動。

另外,朱俊彥團隊發表在ICCV 2019上的論文表明,GAN的生成能力有限,并分析了預訓練GAN無法生成的圖像結構。
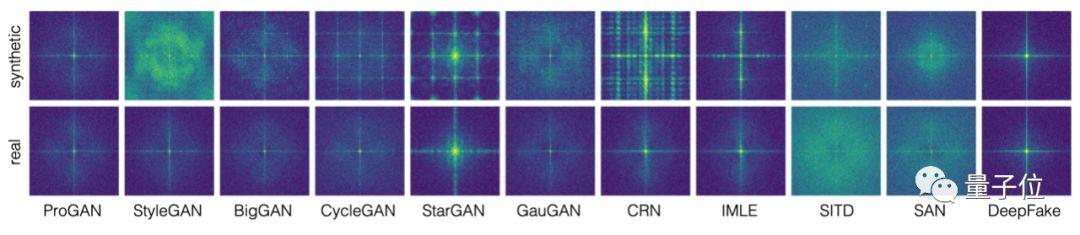
今年7月,哥倫比亞大學的Zhang Xu等人進一步發現了GAN的“通病”,常見GAN中包含的上采樣組件會引起偽像。
他們從理論上證明了,這些偽像在頻域中表現為頻譜的復制,這在頻譜圖上表現十分明顯。
比如同樣是一張馬的圖片,真實照片的信號主要集中在中心區域,而GAN生成的圖像,頻譜圖上出現了四個小點。

因此他們提出了一種基于頻譜而不是像素的分類器模型,在分辨假圖像上達到了最先進的性能。
而Wang同學發現,不僅是GAN,其他的CNN在生成圖像時,也會在頻譜圖中觀察到周期性的圖案。
訓練AI辨別真偽
剛才生成的數據集,包含了11個模型生成的假圖。
不過,真假分類器并不是用這個大合集來訓練的。
真正的訓練集里,只有英偉達ProGAN這一個模型的作品,這是關鍵。

△ ProGAN過往作品展
團隊說,只選一個模型的作品用來訓練,是因為這樣的做法更能適應現實任務:
現實世界里,數據多樣性永遠是未知的,你不知道自己訓練出的AI需要泛化到怎樣的數據上。所以,干脆就用一種模型生成的圖像來訓練,專注于幫AI提升泛化能力。
而其他模型生成的作品,都是測試泛化能力用的。
(如果用很多模型的假圖來訓練,泛化任務就變得簡單了,很難觀察出泛化能力有多強。)
具體說來,真假分類器是個基于ResNet-50的網絡,先在ImageNet上做了預訓練,然后用ProGAN的作品做二分類訓練。
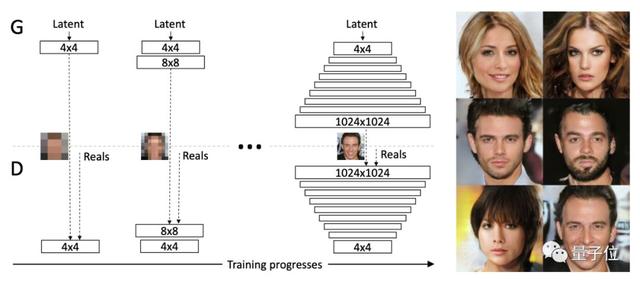
△ ProGAN原理
不過,訓練集不是一只ProGAN的作品。團隊用了20只ProGAN,每只負責生成LSUN數據集里的一個類別。一只ProGAN得到3.6萬張訓練用圖,200張驗證用圖,一半是生成的假圖,一半是真圖。
把20只ProGAN的成果加在一起,訓練集有72萬張,驗證集有4000張。
為了把單一數據集的訓練成果,推廣到其他的數據集上,團隊用了自己的方法:
最重要的就是數據擴增。先把所有圖像左右翻轉,然后用高斯模糊,JPEG壓縮,以及模糊+JPEG這些手段來處理圖像。
擴增手段并不特別,重點是讓數據擴增以后處理的形式出現。團隊說,這種做法帶來了驚人的泛化效果 (詳見后文) 。
訓練好了就來看看成果吧。
明辨真偽
研究人員主要是用平均精度 (Average Precision) 這個指標,來衡量分類器的表現。
在多個不同的CNN模型生成的圖片集里,ProGAN訓練出的分類器都得到了不錯的泛化:
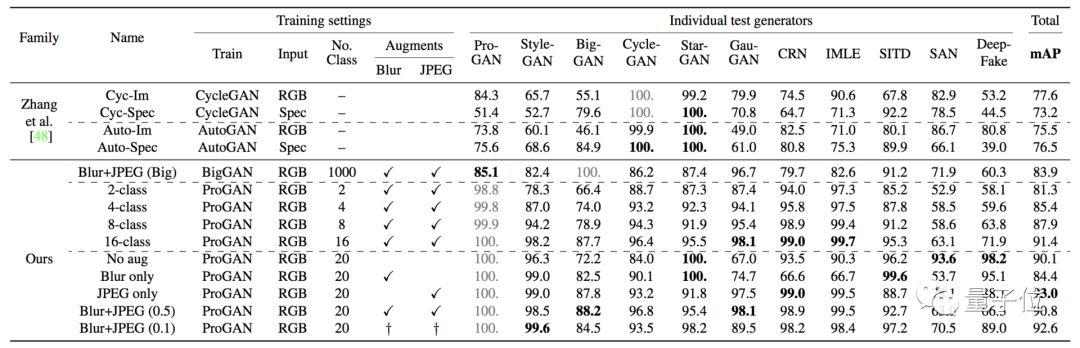
幾乎所有測試集,AP分值都在90以上。只在StyleGAN的分值略低,是88.2。
不論是GAN,還是不用對抗訓練、只優化感知損失的模型、還是超分辨率模型,還是Deepfake的作品,全部能夠泛化。
團隊還分別測試了不同因素對泛化能力產生的影響:
一是,數據擴增對泛化能力有所提升。比如,StyleGAN從96.3提升到99.6,BigGAN從72.2提升到88.2,GauGAN從67.0提升到98.1等等。更直觀的表格如下,左邊是沒有擴增:

另外,數據擴增也讓分類器更加魯棒了。
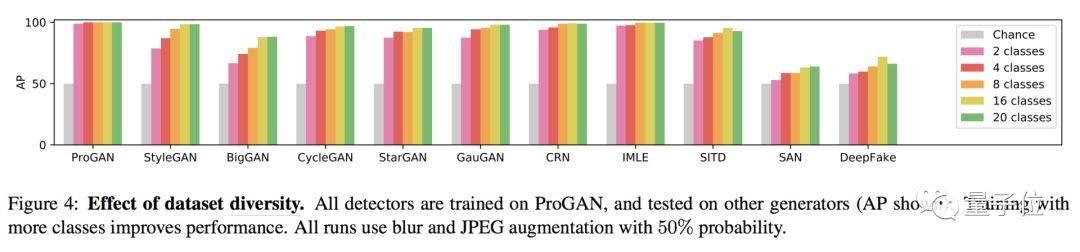
二是,數據多樣性也對泛化能力有提升。還記得當時ProGAN生成了LSUN數據集里20個類別的圖片吧。大體上看,用越多類別的圖像來訓練,得到的成績就越好:
然后,再來試想一下,這時候如果突然有個新模型被開發出來,AI也能適應么?
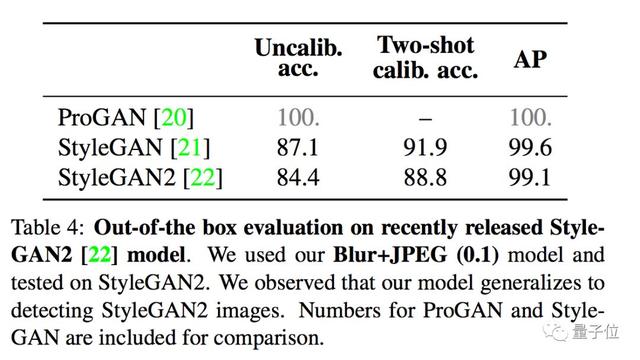
這里,團隊用了剛出爐沒多久的英偉達StyleGAN2,發現分類器依然可以良好地泛化:
最后,還有一個問題。
AI識別假圖,和人類用肉眼判斷的機制一樣么?
團隊用了一個“Fakeness (假度) ”分值,來表示AI眼里一張圖有多假。AI覺得越假,分值越高。

實驗結果是,在大部分數據集里,AI眼里的假度,和人類眼里的假度,并沒有明顯的相關性。
只在BigGAN和StarGAN兩個數據集上,假度分值越高時,能看到越明顯的瑕疵。
更多數據集上沒有這樣的表現,說明分類器很有可能更傾向于學習低層的缺陷,而肉眼看到的瑕疵可能更偏向于高層。
安裝使用
說完了論文,下面我們就可以去GitHub上體驗一下這個模型的厲害了。
論文源代碼基于PyTorch框架,需要安裝NVIDIA GPU才能運行,因為項目依賴于CUDA。
首先將項目克隆到本地,安裝依賴項。
- pip install -r requirements.txt
考慮到訓練成本巨大,作者還提供權重和測試集下載,由于這些文件存放在Dropbox上不便國內用戶下載,在我們公眾號中回復CNN即可獲得國內網盤地址。
下載完成后將這兩個文件移動到weights目錄下。
然后我們就可以用來判別圖像的真假了:
- # Model weights need to be downloaded.
- python demo.py examples/real.png weights/blur_jpg_prob0.1.pth
- python demo.py examples/fake.png weights/blur_jpg_prob0.1.pth
如果你有能力造出一個自己的GAN,還可以用它來檢測你模型的造假能力。
- # Run evaluation script. Model weights need to be downloaded.
- python eval.py
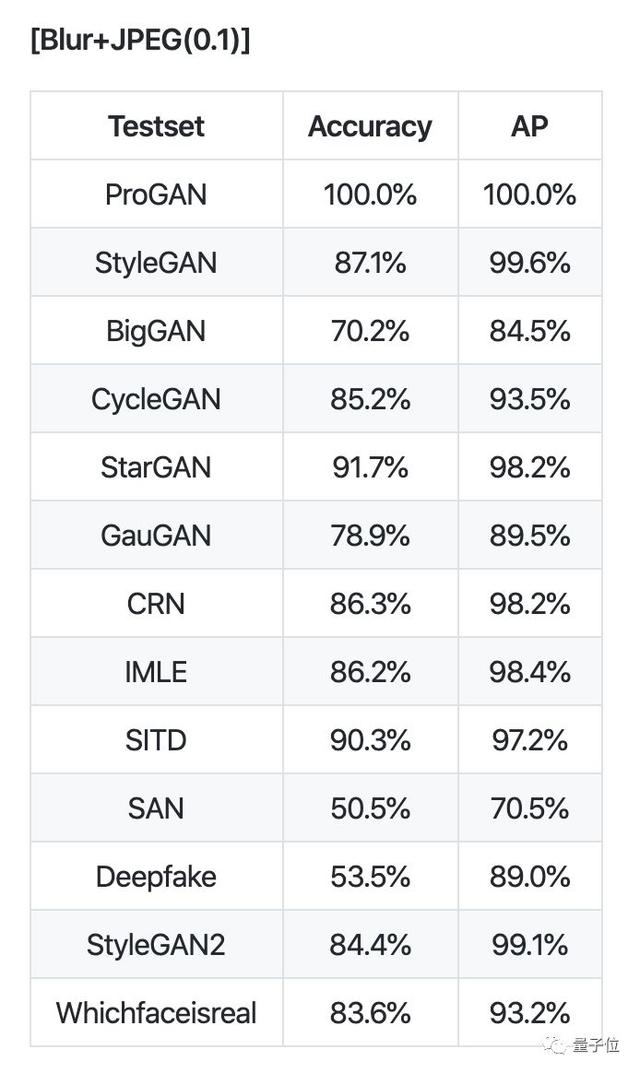
作者就用它鑒別了13種CNN模型制造的圖片,證明了它的泛化能力。
閃閃發光作者團
這篇文章的第一作者是來自加州大學伯克利分校的Wang Sheng-Yu,他現在是伯克利人工智能研究實驗室(BAIR)的一名研究生,在鑒別假圖上是個好手。
今年他和Adobe合作的另一篇論文Detecting Photoshopped Faces by Scripting Photoshop,可以發現照片是否經過PS瘦臉美顏的操作,而且還能恢復“照騙”之前的模樣。

這篇的另一名作者Richard Zhang與Wang同學在上面的文章中也有合作,2018年之前他在伯克利攻讀博士學位,畢業后進入Adobe工作。
這篇文章的通訊作者Alexei Efros,他曾是朱俊彥的導師,本文提到的CycleGAN正是出自朱俊彥博士之手。Alexei現在是加州大學伯克利分校計算機系教授,此前曾在CMU機器人學院任教9年。
傳送門
論文地址:https://arxiv.org/abs/1912.11035
源代碼:https://github.com/peterwang512/CNNDetection