













DeepFake換頭術升級:浙大新模型,GAN出一頭秀發
雖然DeepFake能令人置信地換臉,但沒法同樣換好頭發。現在浙大與瑞典研究者都擴寬思路,用GAN或CNN來另外生成逼真的虛擬發絲。
DeepFake技術面世的2010年間末葉,正好趕上了川普時代。
無數搓手打算用DeepFake來好好惡搞大總統一下的玩梗人,在實操中遇到了一個不大不小的障礙:
各家DeepFake類軟件,可以給圖像換上金毛闖王的橙臉,但那頭不羈的金發實在讓AI都生成不出令人置信的替代品。
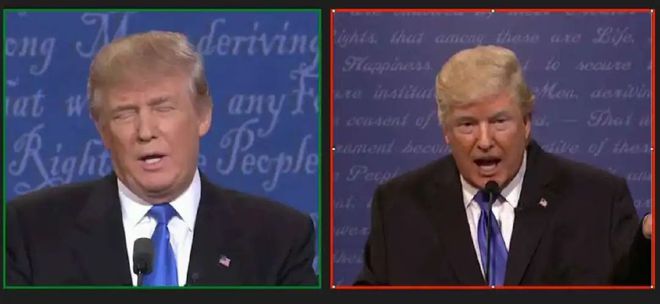
看,是不是那頭毛就讓DeepFake產品露餡了。
DeepFake搞得定換臉,也搞不定換頭發
其實這是老問題遇到了新挑戰。如何栩栩如生地復現人像模特的頭發,這是一個自希臘-羅馬時代的雕像師開始就很覺棘手的難題。
人腦袋平均有大概100000根頭發絲,并且因為顏色和折射率的不同,在超過一定的長度后,即使在計算機時代也只能用復雜物理模型進行模擬,來進行圖像移動和重組。
目前,只有自20世紀末以來的傳統CGI技術可以做到這一點。
當下的DeepFake技術還是不太能解決這個問題。數年來,DeepFaceLab也只發布一個僅僅能捕捉短發的「頭部全體毛發」模型,發部還是僵硬的。這還是一款在業內領先的軟件包。
最近,DFL的合作伙伴FaceSwap做出了BiseNet語義分割模型,能使用戶在deepfake輸出圖像中包括到耳部和頭發的圖形細節呈現。
這兩套軟件包都來自2017年Deepfakes的源代碼,在當時頗受爭議。
就算現在DeepFake模型要呈現的頭發圖像非常短,輸出結果的質量往往也很差,頭像好像是疊加上去的一樣,不像是渾然一體的圖像一部分。
用GAN來生成毛發
目前,業界用來模擬人像使用最多的兩種辦法,一個是神經輻射場技術(Neural Radiance Fields)。NeRF可以從多個視角捕捉畫面,之后可以將這些視角的3D成像封裝在可探索的神經網絡AI里。
另一種辦法則是生成對抗網絡(GAN),GAN在人類圖像合成方面比NeRF更加先進,即使是NeRF在2020年才出現。
NeRF對3D幾何圖形的推測性理解,將使其能夠以較高的保真度和一致性,對圖案場景進行復制。哪怕當前沒有施加物理模型的空間、或者準確來說和攝像頭視角無關的變化,所收集的數據導致的變形都是一樣的。
不過就目前來看,NeRF模擬人類發絲運動模擬的能力并不出色。
與NeRF不同,GAN天然就有個幾乎致命的劣勢。GAN的潛在空間并不會自然包含對3D信息的理解。
因此,3D可感知的GAN所生成的人臉合成圖像,在近幾年成了圖像生成研究的熱點問題。而2019年的InterFaceGAN是最主要的突破之一。
然而,即使是在InterFaceGAN展示上的精心挑選的圖像結果,也都表明:在時間的一致性的表現上,神經網絡AI生成發絲圖像達到令人滿意的一致性依然是一項艱巨的挑戰,應用在VFX圖像工作流程中仍然性能不可靠。
越來越明顯的是,通過操控神經網絡AI潛在空間進行的連貫視圖生成,可能是一種類似煉金術的技術。
越來越多的論文中不得不另辟蹊徑,將基于CGI的3D信息作為穩定的和規范化的約束,納入GAN的工作流程。
CGI元素可以由3D形式的中間圖形元表示,比方說「蒙皮多人線性模型」(SMPL,Skinned Multi-Person Linear Model)。
又或是應用和NeRF模式相近的3D推斷技術得出,在這種技術中,圖像的幾何元素是從源圖像和源視頻中評估出來的。
就在本周,悉尼科技大學的ReLER實驗室、AAII研究所、阿里達摩院以及浙江大學的研究者合作發布了一項論文,描述了用于3D可感知圖像合成的「多視角連貫性生成性對抗網絡」(MVCGAN)。

MVCGAN生成的頭像
MVCGAN包含了一個「生成輻射場網絡」(GRAF)AI,它可以在GAN中提供幾何限制。理論上來講,這個組合可以說實現了任何基于GAN的方法的最逼真虛擬頭發輸出結果。

MVCGAN生成的帶發絲頭像與其他模型生成頭像的對比
從上圖可以看出,在極端發絲參數下,除MVCGAN外,其他模型的圖像結果都產生不可置信的扭曲
不過,在CGI工作流程中,以時間為基礎的虛擬發絲重建依然是一項挑戰。
因此業界尚無理由相信,傳統的、基于幾何圖形的辦法,能夠在可預見將來能把具有時間一致性的發絲圖形合成帶入AI的潛在空間中。
用CNN生成穩定的虛擬頭發數據
不過,瑞典查爾默斯理工學院三位研究人員即將發表的論文,或許還可以為「用神經網絡生成人發圖像」的研究提供新進展。
這篇題為《用卷積神經網絡實時進行毛發濾鏡》的論文即將在2022年5月份的重要學術會議「交互式3D圖形和游戲盛會」上發表。
該系統由一個基于自動編碼器的神經網絡AI作為基礎,該神經網絡AI能夠實時評估生成的虛擬發絲圖案分辨率,包括發絲在虛擬空間中自動產生的陰影和頭發厚度呈現。此自動編碼器的隨機數種子來自于由OpenGL幾何體生成的有限隨機數樣本。
由這種方法途徑,就可以只渲染有限數量的、具有隨機透明度的樣本,然后訓練U-net來重建原始圖像。
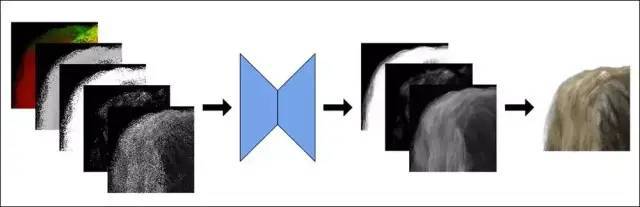
該神經網絡在PyTorch上進行訓練,可以在6-12小時內完成訓練達到收斂,具體市場取決于神經網絡體量和輸入特征值的數量。然后將訓練的參數(權重)用于圖像系統的實時實現。
訓練數據集,則是通過以隨機距離、姿勢以及不同的照明條件,來渲染數百張直發和波浪發型的實際圖片而生成的。
樣本中的發絲半透明度數值,是從在超采樣分辨率條件下、以隨機透明度渲染的圖像平均求得的。
原始的高分辨率數據,先被降采樣,以適應網絡和硬件限制;然后在典型的自動編碼器工作流程中進行上采樣,以提高清晰度。

利用從訓練模型派生的算法的「實時」軟件,作為此AI模型的實時推理應用程序,采用了NVIDIA CUDA、cuDNN和OpenGL的混合。
初始輸入特征值被轉儲到OpenGL的多重采樣顏色緩沖區中,其處理結果在CNN中繼續處理前會分流到cuDNN張量,然后這些張量將會被復制回「實時」OpenGL紋理中,以施加到最終圖像中。
這個AI的實時運行硬件是一張NVIDIA RTX 2080顯卡,產生的圖像分辨率是1024x1024像素。
由于頭發顏色的數據值與神經網絡AI處理的最終值是完全分離的,因此改變頭發顏色是一項容易的任務,盡管虛擬發絲的漸變和條紋等效果仍然將在未來構成挑戰。

結論
探索自動編碼器或GAN的潛在空間,仍然更類似于靠直覺的駕帆船,而非精確駕駛。只有在最近的時段,業界才開始看到在NeRF、GAN和非deepfake(2017)自動編碼器框架等方法中生成「更簡單」的幾何形狀(如人臉)的可靠結果。
人類頭發顯著的結構復雜性,加上需要結合當前物理模型和圖像合成方法無法提供的其他特征,表明頭發合成不太可能仍然只是一般面部合成模型中的一個集成組件。此任務需要復雜的、專用的和獨立的神經網絡AI來完成,即使這些神經網絡最終可能會被納入更廣泛、更復雜的面部合成框架中。





















