













用AI評估AI,上交大新款大模型部分任務(wù)超越GPT-4,模型數(shù)據(jù)都開源
評估大模型對齊表現(xiàn)最高效的方式是?
在生成式AI趨勢里,讓大模型回答和人類價(jià)值(意圖)一致非常重要,也就是業(yè)內(nèi)常說的對齊(Alignment)。
“讓大模型自己上。”
這是上海交通大學(xué)生成式人工智能研究組(GAIR)提出的最新思路。
但是目前的評估方法還存在透明度不夠、準(zhǔn)確性不佳等問題。
所以研究人員開源了一個130億參數(shù)規(guī)模的大模型Auto-J,能對評估當(dāng)下大模型的對齊效果。
它可同時分析兩個大模型的回答,分別做出評價(jià)并進(jìn)行對比。
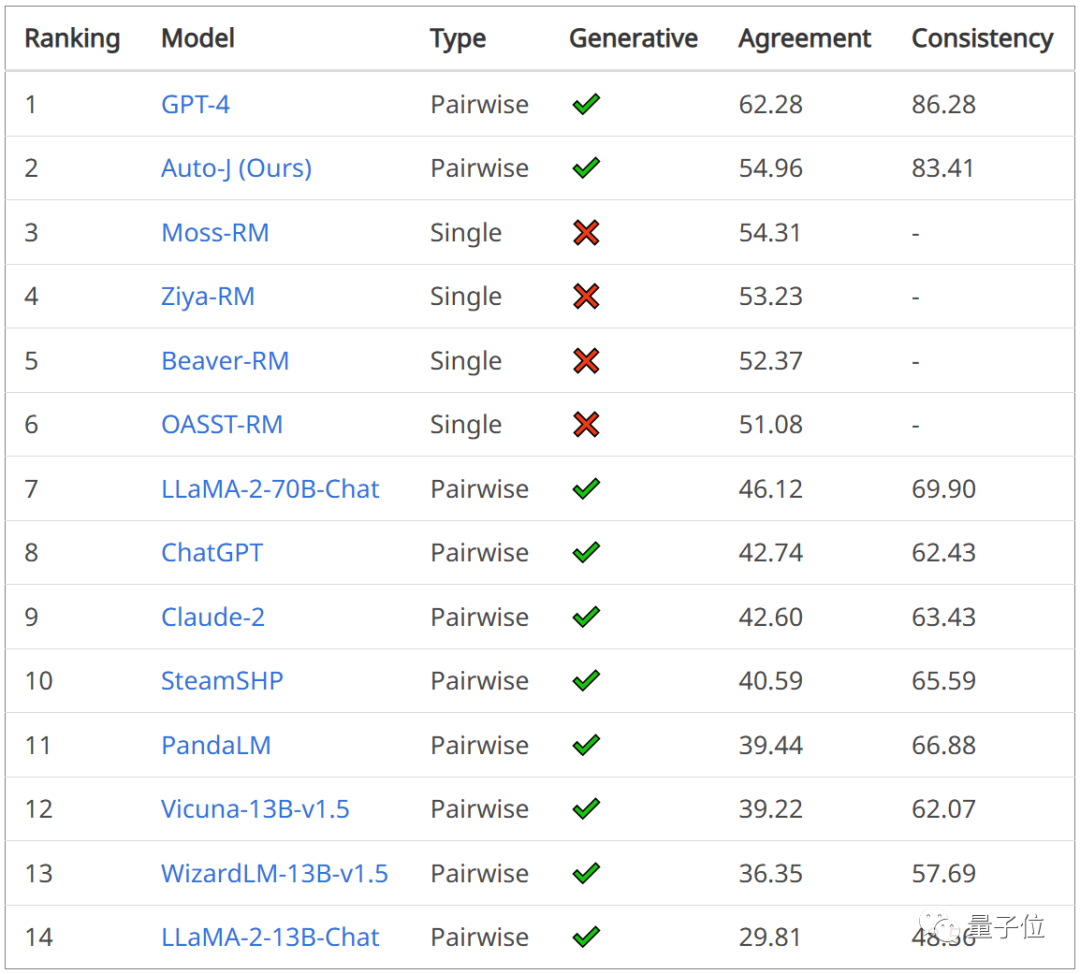
也能評估單個回復(fù)。并且在這一任務(wù)上的表現(xiàn)超越了GPT-4。
目前,該項(xiàng)目開源了大量資源,包括:
- Auto-J的130億參數(shù)模型(使用方法、訓(xùn)練和測試數(shù)據(jù)也已經(jīng)在GitHub上給出);
- 所涉及問詢場景的定義文件;
- 每個場景手工構(gòu)建的參考評估準(zhǔn)則;
- 能夠自動識別用戶問詢所屬場景的分類器等。
用大模型指導(dǎo)大模型回答
在實(shí)際任務(wù)中,Auto-J不僅可以在兩個不同模型的回復(fù)中,指明更優(yōu)秀的回答,而且會從多個具體維度給出判斷和分析。
同時對于它認(rèn)為不夠好的回復(fù),能提出改進(jìn)建議。
注:本節(jié)提供的示例已由原始英文文本翻譯為中文
具體來看Auto-J在成對回復(fù)比較和單回復(fù)評估任務(wù)的效果。
成對回復(fù)比較部分給出的問題是:
起草一份給我家人的郵件,告訴他們我已經(jīng)買好了感恩節(jié)的機(jī)票。我會在11月22日出發(fā),30日離開。
實(shí)驗(yàn)對比了GPT4ALL-13B-snoozy和Claude-1的回復(fù)。

Auto-J給出的判斷是Claude-1的回復(fù)更好,原因是信息更豐富、吸引人、個性化。
同時它也給出了具體的分析過程,從目的、語氣、正文內(nèi)容、個性化、信息豐富度幾個方面評估,并講明了各個方面兩個大模型的優(yōu)劣。

單回復(fù)評估任務(wù)的提問是:
在烤架上烤三文魚最好的方法是什么?
待評估的回復(fù)是:
在烤架上烹制三文魚的最好辦法是首先將烤架預(yù)熱至中高溫,刷上橄欖油,撒上鹽和胡椒,然后把三文魚皮朝下放在烤架上。讓三文魚烤5-7分鐘,直到皮酥脆,用叉子輕松刺入魚肉。翻轉(zhuǎn)三文魚,再烤3-4分鐘,配上你喜歡的配菜,享受美味。
對于這段回答,Auto-J給出的評價(jià)是“答得害行但是在幾個方面缺乏深度和詳細(xì)信息”。
比如沒有提到具體的烹飪溫度或時間,沒有提到三文魚的品質(zhì)。
而且還給出了具體建議能讓回復(fù)更加有個性化:通過詢問用戶有關(guān)具體烤肉設(shè)備或烹飪?nèi)聂~的經(jīng)驗(yàn)。

支持50+場景
在性能表現(xiàn)上,Auto-J在以下兩方面都表現(xiàn)不錯。
功能使用方面
支持50+種不同的真實(shí)場景的用戶問詢(query)(如常見的廣告創(chuàng)作,起草郵件,作文潤色,代碼生成等)能夠評估各類大模型在廣泛場景下的對齊表現(xiàn);
它能夠無縫切換兩種最常見的評估范式——成對回復(fù)比較和單回復(fù)評估;并且可以“一器多用”,既可以做對齊評估也可以做“獎勵函數(shù)”(Reward Model)對模型性能進(jìn)一步優(yōu)化;
同時,它也能夠輸出詳細(xì),結(jié)構(gòu)化且易讀的自然語言評論來支持其評估結(jié)果,使其更具可解釋性與可靠性,并且便于開發(fā)者參與評估過程,迅速發(fā)現(xiàn)價(jià)值對齊過程中存在的問題
性能開銷方面
在性能和效率上,Auto-J 的評估效果僅次于GPT-4而顯著優(yōu)于包括ChatGPT在內(nèi)的眾多開源或閉源模型,并且在高效的vllm推理框架下能每分鐘評估超過100個樣本。
在開銷上,由于其僅包含130億參數(shù),Auto-J能直接在32G的V100上進(jìn)行推理,而經(jīng)過量化壓縮更是將能在如3090這樣的消費(fèi)級顯卡上部署使用,從而極大降低了LLM的評估成本 (目前主流的解決方法是利用閉源大模型(如GPT-4)進(jìn)行評估,但這種通過調(diào)用API的評估方式則需要消耗大量的時間和金錢成本。)
具體方法
訓(xùn)練數(shù)據(jù)總體上遵循如下的流程示意圖:

△訓(xùn)練數(shù)據(jù)收集流程示意圖
場景的定義和參考評估標(biāo)準(zhǔn):


△場景定義與參考評估標(biāo)準(zhǔn)
為了更廣泛的支持不同的評估場景,Auto-J 定義了58種不同的場景,分屬于8大類(摘要,重寫,代碼,創(chuàng)作,考題,一般交流,功能性寫作以及其他NLP任務(wù))。
對于每個場景,研究者手動編寫了一套用作參考的評估標(biāo)準(zhǔn)(criteria),覆蓋了這類場景下常見的評估角度,其中每條標(biāo)準(zhǔn)包含了名稱和文本描述。
評估標(biāo)準(zhǔn)的構(gòu)建遵循一個兩層的樹狀結(jié)構(gòu):先定義了若干組通用基礎(chǔ)標(biāo)準(zhǔn)(如文本與代碼的一般標(biāo)準(zhǔn)),而每個場景的具體標(biāo)準(zhǔn)則繼承了一個或多個基礎(chǔ)標(biāo)準(zhǔn),并額外添加了更多的定制化標(biāo)準(zhǔn)。
以上圖的“規(guī)劃”(planning)場景為例,針對這一場景的標(biāo)準(zhǔn)包括了該場景特定的內(nèi)容與格式標(biāo)準(zhǔn),以及繼承而來的基礎(chǔ)標(biāo)準(zhǔn)。
收集來自多種場景的用戶問詢和不同模型的回復(fù):
Auto-J被定位成能夠在定義的多種廣泛場景上均表現(xiàn)良好,因此一個重要的部分就是收集不同場景下相應(yīng)的數(shù)據(jù)。為此,研究者手動標(biāo)注了一定量用戶問詢的場景類別,并以此訓(xùn)練了一個分類器用以識別任意問詢的所屬場景。
在該分類器的幫助下,成功從包含了大量真實(shí)用戶問詢和不同的模型回復(fù)的若干數(shù)據(jù)集中(如Chatbot Arena Conversations數(shù)據(jù)集)通過降采樣的方式篩選出了類別更加均衡的3436個成對樣本和960個單回復(fù)樣本作為訓(xùn)練數(shù)據(jù)的輸入部分,其中成對樣本包含了一個問詢,兩個不同的針對該問詢的回復(fù),以及人類標(biāo)注的偏好標(biāo)簽(哪個回復(fù)更好或平局);而單回復(fù)樣本則只包含了一個問詢和一個回復(fù)。
收集高質(zhì)量的評判(judgment):
除了問詢和回復(fù),更重要是收集作為訓(xùn)練數(shù)據(jù)輸出部分的高質(zhì)量評估文本,即“評判”(judgment)。
研究者定義一條完整的評判包含了中間的推理過程和最后的評估結(jié)果。對于成對回復(fù)比較而言,其中間推理過程為識別并對比兩條回復(fù)之間的關(guān)鍵不同之處,評估結(jié)果是選出兩條回復(fù)中更好的一個(或平局);而對于單回復(fù)樣本,其中間推理過程是針對其不足之處的評論(critique),評估結(jié)果則是一個1-10的總體打分。
在具體操作上,選擇調(diào)用GPT-4來生成需要的評判。
對于每個樣本,都會將其對應(yīng)場景的評估標(biāo)準(zhǔn)傳入GPT-4中作為生成評判時的參考;此外,這里還觀察到在部分樣本上場景評估標(biāo)準(zhǔn)的加入會限制GPT-4發(fā)現(xiàn)回復(fù)中特殊的不足之處,因此研究者還額外要求其在給定的評估標(biāo)準(zhǔn)之外盡可能地發(fā)掘其他的關(guān)鍵因素。
最終,會將來自上述兩方面的輸出進(jìn)行融合與重新排版,得到更加全面、具體且易讀的評判,作為訓(xùn)練數(shù)據(jù)的輸出部分,其中對于成對回復(fù)比較數(shù)據(jù),進(jìn)一步根據(jù)已有的人類偏好標(biāo)注進(jìn)行了篩選。
訓(xùn)練:
研究者將來自兩種評估范式的數(shù)據(jù)合并使用以訓(xùn)練模型,這使得Auto-J僅通過設(shè)置相應(yīng)的提示詞模板即可無縫切換不同的評估范式。
另外,還采用了一種類似于上下文蒸餾的(context distillation)技術(shù),在構(gòu)建訓(xùn)練序列時刪去了GPT-4用以參考的場景評估標(biāo)準(zhǔn),僅保留了輸出端的監(jiān)督信號。
在實(shí)踐中發(fā)現(xiàn)這能夠有效增強(qiáng)Auto-J的泛化性,避免其輸出的評判僅限制在對評估標(biāo)準(zhǔn)的同義重復(fù)上而忽略回復(fù)中具體的細(xì)節(jié)。
同時,對于成對回復(fù)比較數(shù)據(jù)部分,還采用了一個簡單的數(shù)據(jù)增強(qiáng)方式,即交換兩個回復(fù)在輸入中出現(xiàn)的順序,并對輸出的評判文本進(jìn)行相應(yīng)的重寫,以盡可能消除模型在評估時的位置偏好。
實(shí)驗(yàn)和結(jié)果
針對Auto-J所支持的多個功能,分別構(gòu)建了不同的測試基準(zhǔn)以驗(yàn)證其有效性:
在成對回復(fù)比較任務(wù)上,評估指標(biāo)為與人類偏好標(biāo)簽的一致性,以及在交換輸入中兩個回復(fù)的順序前后模型預(yù)測結(jié)果的一致性。
可以看到Auto-J在兩個指標(biāo)上均顯著超過了選取的基線模型,僅次于GPT-4。


△成對回復(fù)比較任務(wù)的結(jié)果
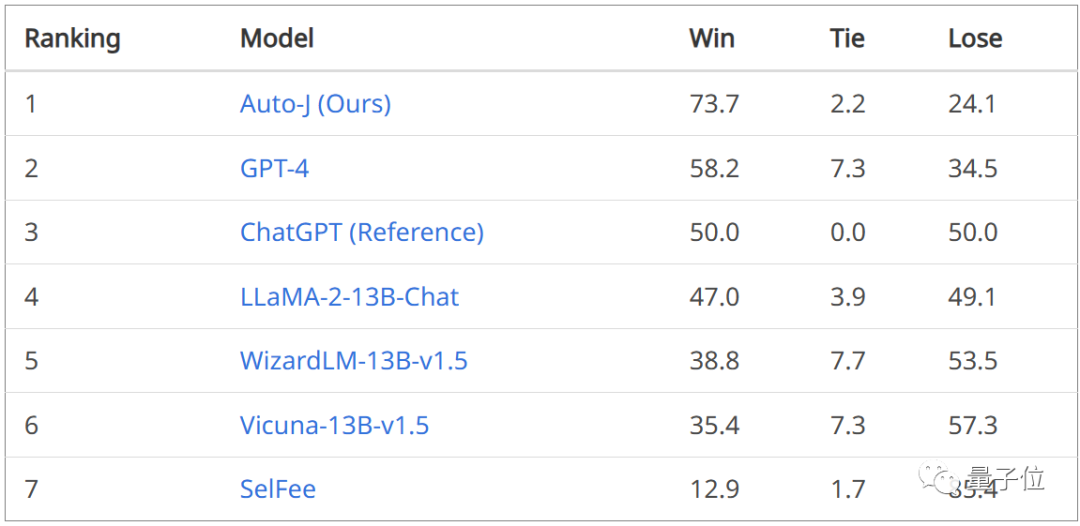
在單回復(fù)評論生成任務(wù)上,將Auto-J生成的評論與其他模型的評論進(jìn)行了一對一比較,可以看到不管是基于GPT-4的自動比較還是人類給出的判決,Auto-J所生成的評論都顯著優(yōu)于大部分基線,且略微優(yōu)于GPT-4。

△Auto-J在單回復(fù)評論生成任務(wù)上相比基線的勝率
研究者還探索了Auto-J作為獎勵模型(Reward Model)的潛力。
在常用的檢測獎勵模型有效性的Best-of-N設(shè)定下(即基座模型生成多個候選答案,獎勵模型根據(jù)自身輸出選擇最佳回復(fù)),Auto-J給出的單回復(fù)打分比各類基線模型能選出更好的回復(fù)(以GPT-4評分為參考)。
同時,其打分也顯示了與GPT-4打分更高的相關(guān)性。

△不同模型作為獎勵模型的表現(xiàn)
最后,開發(fā)者也探究了Auto-J在系統(tǒng)級別的評估表現(xiàn)。
對AlpacaEval(一個流行的基于GPT-4評估的大模型排行榜)上提交的開源模型使用Auto-J的單樣本打分進(jìn)行了重新排序。
可以看到,基于Auto-J的排序結(jié)果與GPT-4的排序結(jié)果有極高的相關(guān)性。


△Auto-J與GPT-4對AlpacaEval排行榜提交的開源模型排序之間的相關(guān)性及具體排名數(shù)據(jù)
作者總結(jié)和展望
總結(jié)來說,GAIR研究組開發(fā)了一個具有 130 億參數(shù)的生成式評價(jià)模型 Auto-J,用于評估各類模型在解決不同場景用戶問詢下的表現(xiàn),并旨在解決在普適性、靈活性和可解釋性方面的挑戰(zhàn)。
實(shí)驗(yàn)證明其性能顯著優(yōu)于諸多開源與閉源模型。
此外,也公開了模型之外的其他資源,如模型的訓(xùn)練和多個測試基準(zhǔn)中所使用的數(shù)據(jù),在構(gòu)建數(shù)據(jù)過程中得到的場景定義文件和參考評估標(biāo)準(zhǔn),以及用以識別各類用戶問詢所屬場景的分類器。
該項(xiàng)目具體的論文、主頁信息如下:
論文地址:https://arxiv.org/abs/2310.05470
項(xiàng)目地址:https://gair-nlp.github.io/auto-j/
代碼地址:https://github.com/GAIR-NLP/auto-j






























