分析全球最大美食點評網站萬家餐廳數據 尋找餐廳經營成功的秘密
作者|Jiaxu Luo, Charles Leung, Danli Zeng, Samriddhi Shakya
翻譯校對|吳小雯 Francis 姜范波 寒小陽
摘要
各位美食愛好者對于Yelp應該比“大眾點評”更加熟悉。這家美食評論起家的網站是被全球公認的“美食攻略提供者”,它是利用大眾經驗和點評的最好例子之一,而其中的大量評價數據和排名機制也因此“操控”了很多家大小餐廳的生死。
開一家自己的餐廳,對小企業主們而言是一件很令人膽怯的活——開始經營的前三年中,60%的餐廳會經營失敗。對于很多業主,Yelp曝光率是決定他們能否挺過前三年經營的關鍵因素。
本文來自NYC數據科學學院舉辦的為期12周全日制的數據科學訓練營,該文章基于他們最后的畢業設計。
該畢業設計的目的是:確定出能在Yelp中取得高評分的關鍵屬性和特征。結合數據可視化和機器學習算法,我們識別出高商業評分的影響屬性和特征。我們也利用自然語言處理從用戶評價中提煉出有價值的信息。喜歡奇思妙想的我們五個人,利用R Shiny 構建應用程序來幫助業主們通過以下三種方式進入該市場:
1.地圖:針對經營成功的餐廳進行地理位置分析
2.主題模型:針對不同類別的餐廳進行差評分析
3.美食廊:對好評如潮的菜系種類進行分析
簡介
康奈爾大學的研究表明,27%新餐廳會在第一年倒閉,而將近有60%的餐廳會在三年內倒閉。無法經營成功的一個關鍵性阻礙是Yelp曝光率不足。經營良好的餐廳,顧客會定期光臨,會有較高評分和點評數量,這樣會提高餐廳在搜索排名中的位置,為任何倒霉事保留緩沖空間。
Yelp中的餐廳排名是被全球公認的,它是利用大眾經驗和點評的最好例子之一。我們想要尋求的答案是——影響餐廳經營成功的關鍵特征是什么?我們相信從Yelp提供的與評分相關的官方數據中,一定能找出可識別的重要特征。
這些關鍵特征可以是商家經營的固有屬性,例如開業時間,環境吵鬧程度,也可以是客戶的主觀因素。通過數據可視化和預測模型,我們探索出在Yelp中取得高分的關鍵特征。我們通過基于隱狄利克雷分布(Latent Dirichlet Allocation)的主題模型算法處理客戶評價內容。我們的最終作品,匯總了我們的各種發現,以R Shiny應用——YelpQuest的形式進行呈現。
數據處理
我們應用的數據源來自于Yelp 2016 Dataset Challenge,它提供的數據表有:業務表(businesss),評價表(reviews),小貼士表(tips,更簡短的評價),用戶信息表(user information)和簽到表(check-ins)。其中業務表(business table)中列出了餐廳的名稱,地理位置,營業時間,菜系類別,平均星級評分,評價數量和其他與經營相關的一系列因素,如:吵鬧程度,預訂政策。評價表(review table)中列出餐廳星級評分,評價內容,評價時間,和該評價獲得的支持率。我們限制采樣數據集的范圍在美國鳳凰城(Phoenix)的大都市區域,然后通過類別過濾業務表(business)數據,僅保留餐廳和評價數據。從餐廳中獲取到的評價文本會構成該項目的語料庫。

挑戰
- 關于預測,雖然只有9427家餐廳為樣本,但特征的數量是十分龐大的。我們擁有的數據不足以充分支持結論。特征簡化或者選擇一個相對復雜的模型是有必要的。
- 對于不同菜系的餐廳,好評/差評 的標準是不同的。僅通過評價星級無法完全捕捉客戶的觀點。例如,快餐店的評分一般都很低;因此,4星評分的快餐店比4星評分的意大利餐廳更出色。
業務表(Business Table)
- 從業務表文件中查找出餐廳
- 創建只包括餐廳(restaurants)的業務子表文件
- 創建包括評價,簽到、小貼士的子表文件
- 從評價,簽到和小貼士子文件中進行數據總結(例如:每個餐廳的簽到/小貼士/評價總數量),并創建包括業務ID和求和字段的概況數據文件,該文件可以追加到餐廳(restaurants)文件中
- 合并概況數據到業務餐廳(restaurants)數據中,并形成最終的模型數據集
評價表(Reviews Table)
- 根據餐廳分類得到平均分,判斷各餐廳是高于還是低于平均分(例如,在分類平均值中,泰式:4.5星,快餐店:3.5星)
- 基于餐廳類別平均分,創建好評的數據子集
- 基于餐廳類別平均分,創建差評的數據子集
- 連接從步驟2到步驟3得到的兩個子集
- 從步驟4創建頂級菜肴的評價子集,對好評和差評的數據集根據評價進行主題建模。
探索性數據分析
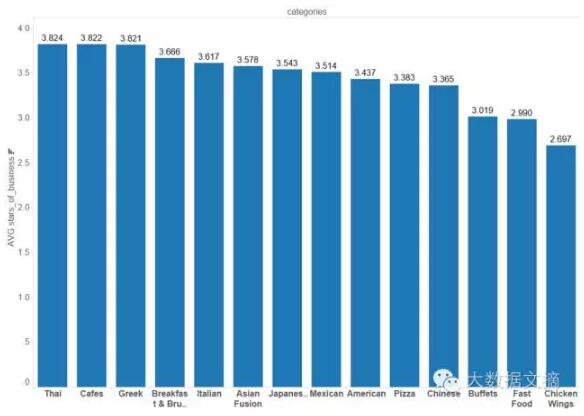
通過探索性分析,我們首先想要檢測自己那些先入為主的觀點。當我們想到5星餐廳時,我們不會想到是快餐店或者披薩店。我們想到的是富麗堂皇的歐洲菜,如意大利菜或法國菜。通過菜系進行分類計算評分平均值,我們得到了以下的信息圖表,例如:泰式或希臘菜系會有很高的評分,而自助餐,快餐和雞翅店會有較低的評分。這些數據似乎能支持我們的假設:餐廳的評分跟特定的菜系類別有關。
與此同時,當我們想象5星評分的餐廳時,一般不會想到路邊的便宜小餐廳。為檢測人均消費對餐廳評分的影響,我們繪制了以下Mosaic圖。你看到的是關于價格范圍和評分水平的卡方檢驗(它給出了一個很顯著的P值 2.2e-16)。
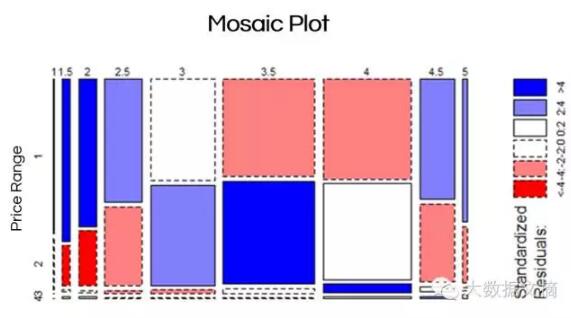
Mosaic圖使用顏色作為比較各價格范圍和星級評分組合下,觀測值與期待值的差別(譯注:如圖所示,橫向為星級評分,分為9組,縱向為價格范圍,分為4組。如果價格范圍對星級評分沒有影響,則各價格段的星級評分頻率分布是均一的(即期待值),應顯示為白色,而本例中多處顯示為紅色或藍色,表示價格范圍對星級評分有影響)。藍顏色表示,相對于預期結果,實際上有更多的觀測值,而紅色卻有更少的觀測值。在本案例中,我們可以觀察到,價格和星級評分不是完全獨立的,該結果可通過χ2檢測得到證實。
預測模型
為從數據中確定出關鍵的影響特征,我們決定使用基于樹的模型。相對于觀察到的大量屬性和特征,我們的數據表顯得很稀疏。基于樹的模型可以解決稀疏性問題,特別是XGBoost更為出色。我們選擇了三種不同的模型:隨機森林,XgBoost和梯度增強樹。下圖展示了基于XGBoost的結果,因為它具有更高的穩定性。
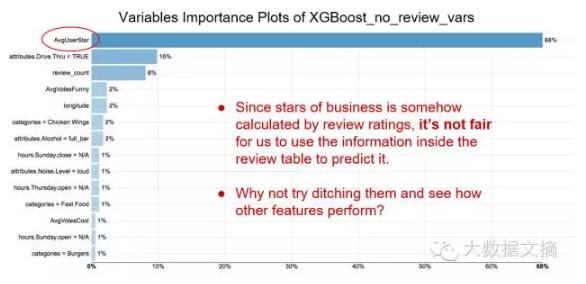
首先我們將所有的有效屬性作為預測因子進行建模,擬合到了一個R square =0.936的模型。根據特征重要性的圖示我們可以得出一個很強的影響因子——用戶平均評價星級。然而,該信息并不是什么遠見卓識;總體的商業評分是所有用戶評分的平均值,因此顯而易見該因素在圖表中會很顯著。我們決定移除所有跟評價相關的因素后,再重新運行XGBoost:
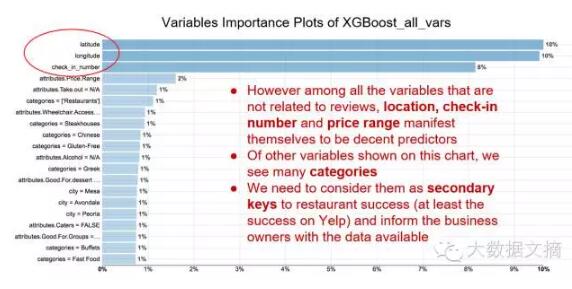
第二次運行時,R square 明顯地下降到0.318,去除評價相關的因素后,我們無法很好的進行評分預測。這次試驗中,地理位置,用餐人數,人均消費是重要的預測因子。
主題建模
預處理
建立任何模型之前,我們都需要預處理點評文本:
- 刪除常用的停用詞,例如“在”,“和”,“但是”等等。。。
- 刪除標點,規避非字符號
- 刪除數字
- 刪除無法寫出的符號
- 去除空白符號
- 將文本轉換為小寫字母
- 把文本分詞為二元詞和三元詞(n-gram語言模型中的bigrams和trigrams)
由于一些詞匯與其他詞匯連用時會改變其原有的意思,我們決定將點評文本分詞為二元詞組和三元詞組(2或3字的組合) 。例如,如果將 “不好” 分成 “不” 和 “好” 兩個單詞,那么分析過程就會出錯。
LDA(主題模型)和數據可視化
為了理解點評數據中的關鍵主題,我們使用LDA主題建模算法來提取每個類別和每個評級中的20項關鍵主題。我們使用R語言擴展包 “LDAvis” 來進行交互式主題模型的可視化, 并且回答了這些問題:
1.每項關鍵主題都是什么意思?
2.這些關鍵主題普遍性怎么樣?
3.這些關鍵主題是如何相互關聯?
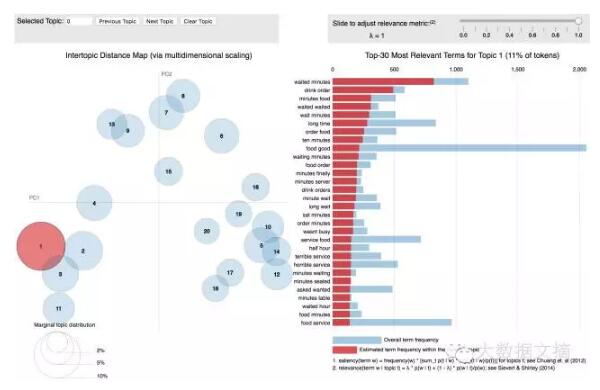
上圖右側結果是LDAvis對第一個問題的回答。在這張條形圖中,y軸是詞條,x軸是出現次數,你可以看出點評內容中特定詞條在各主題內的出現次數。我們采用一種特殊的度量標準 -- 顯著性(saliency) -- 來確定一項主題中最重要的詞條。顯著性就是詞條在單個主題中出現頻率相對其在整個點評文本中出現頻率的比例。排列越靠前的詞條也就越獨特,相對于這項主題也就更重要。
上圖左側LDAvis的結果圖叫做主題間距模型。它為主題模型提供全局視圖,并且回答了后兩個問題 -- 每個主題圓的直徑代表每項主題的普遍性;詹森 - 香農離散度計算出主題間的相互距離,(詹森 - 香農離散度是測算兩個概率分布間相似性的流行方法),然后再按比例調整每兩個主題的間距。要點在于,兩個氣泡越是靠近彼此,它們就越相似。一圖勝千言,因此我們將它納入了我們的應用程序。
應用程序
我們的最終產品為R Shiny應用程序,包含以下幾項功能:
- 地圖:餐廳成功的地理位置分析
- 主題建模:理解指定類別市場中的差評
- 料理畫廊:理解好評中頻繁出現的料理主題
我們的主要用戶將是想要開餐廳或擴展餐廳的小企業主。
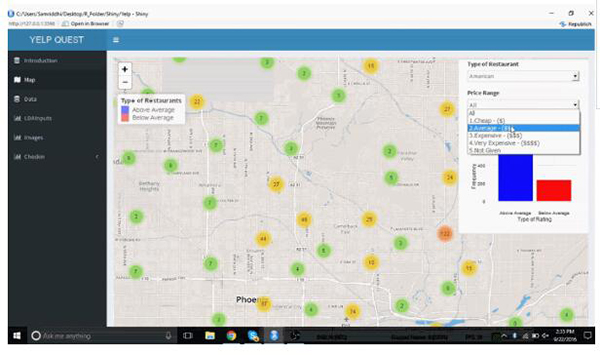
通過地圖,用戶可以找出開餐廳最好的地方,或是鳥瞰餐廳間的競爭狀況。亞利桑那州的一張互動地圖顯示出了這些餐廳,它們被分為某類餐廳中 “高于同類平均水平” 和 “低于同類平均水平” 兩組。用戶通過點擊地圖上的標記就能獲得有關餐館的具體信息。現在假設用戶希望開一家意大利餐廳:
標識出地圖上的大型片區
在地圖上,人們普遍喜歡意大利食品的最大片區就很可能是開餐廳的好地點。
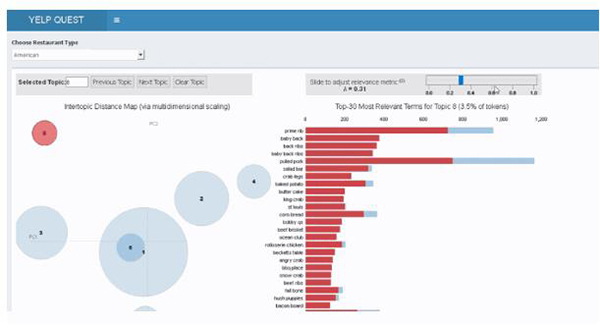
還有就是主題模型功能。
以前如果想要了解其他餐館的負面點評,唯一方法就是閱讀每一頁點評。而主題模型是迅速匯總信息的最快方式。用戶可以快速探索不同的主題氣泡,并基于點評中詞條的出現頻率找出問題。例如,如果時間是一個很重要的問題,那么用戶在開餐廳時就可以利用這一點。
最后是菜單畫廊功能。
畫廊可以顯示出最受好評的食物。用戶可以通過了解最流行的詞條來建立自己餐廳的菜單。
通過使用預測模型和探索式數據分析(EDA),我們確定了要納入應用程序YelpQuest中作為預測因子和過濾器的關鍵特征。而基于差評和好評的主題模型使我們的產品有望幫助未來小企業主們的成長和成功。
【本文是51CTO專欄機構大數據文摘的原創譯文,微信公眾號“大數據文摘( id: BigDataDigest)”】