













為什么MongoDB敢說“做以前你從未能做的事”
在MongoDB的網(wǎng)站上,它這樣自我介紹:做以前你從未能做的事(Do What You Could Never Do Before)。為什么MongoDB敢這樣說?它有什么長(zhǎng)處與不足?今天我們給大家拋磚引玉。

一、 MongoDB是什么?
“需求是創(chuàng)新之母。” 雖然這是句老話,但現(xiàn)在依然很受用!
過去的十年,我們將數(shù)據(jù)生成、存儲(chǔ)和分析的臨界點(diǎn)推上一個(gè)全新的高度。這個(gè)大躍進(jìn)是我們向數(shù)字化的數(shù)據(jù)驅(qū)動(dòng)的經(jīng)濟(jì)又近了一步;這個(gè)大躍進(jìn)也創(chuàng)造了它自身的需要。而這些問題及其解決方法通常都在大數(shù)據(jù)的保護(hù)傘之下。
想象一下:如今,臉書和谷歌產(chǎn)生了更多的數(shù)據(jù),它們加在一起超過了前幾年的全球數(shù)據(jù)總量。伴隨數(shù)據(jù)生成的高速增長(zhǎng),隨之而來是存儲(chǔ)和規(guī)模的問題。看,所有人都希望臉書上的訂閱能夠被瞬間加載——我們?cè)骱薅酥謾C(jī)和電腦在那兒傻傻等著它加載。可回頭想想,什么架構(gòu)才能使我們有這樣快速體驗(yàn)?數(shù)百萬的用戶同時(shí)向數(shù)據(jù)庫請(qǐng)求實(shí)時(shí)信息。再加上非結(jié)構(gòu)化數(shù)據(jù)和系統(tǒng)需求(讓您可以快速添加新功能),這看上去更像是一個(gè)不可能完成的任務(wù)。
傳統(tǒng)的數(shù)據(jù)庫很難應(yīng)付這種需求,且提升規(guī)模所需的成本令人望而卻步。本文給大家介紹一個(gè)新型的數(shù)據(jù)存儲(chǔ)系統(tǒng),大家管它叫做MongoDB。它提供了無架構(gòu)設(shè)計(jì)、高性能、高可用性和自動(dòng)規(guī)模伸縮,這是當(dāng)前所需要但傳統(tǒng)RDBMS系統(tǒng)無法滿足的性質(zhì)。
維基上這么描述MongoDB
MongoDB(源自huMONGOus一詞,意為“堆積如山的”)是一個(gè)跨平臺(tái)的面向文檔的NoSQL數(shù)據(jù)庫。MongoDB避開了傳統(tǒng)的基于表格的關(guān)系型數(shù)據(jù)庫結(jié)構(gòu),代之以具有動(dòng)態(tài)結(jié)構(gòu)的類JSON文檔格式(MongoDB稱之為BSON),從而使一些特定類型應(yīng)用的數(shù)據(jù)整合更容易、更快。在GNU Affero和Apach許可下發(fā)布的MongoDB是一個(gè)免費(fèi)的開源軟件。
二、有誰在用MongoDB?
下面只列舉其中一部分。實(shí)際上,MongoDB在全球已有一千萬次以上的下載量,目前有三十萬人正在學(xué)習(xí)MongoDB。

三、對(duì)比傳統(tǒng)關(guān)系型數(shù)據(jù)庫
將關(guān)系型數(shù)據(jù)庫和MongoDB進(jìn)行比較,就好似在比較一只獅子和一只老虎一般。雖然都是食肉動(dòng)物,但是一個(gè)是獨(dú)自狩獵,另一個(gè)則是群體出動(dòng)。SQL(老虎)有著一個(gè)固定的數(shù)據(jù)模型,其中的數(shù)據(jù)需要遵循架構(gòu)的設(shè)計(jì),這有助于組織分析例如銷售統(tǒng)計(jì)類的結(jié)構(gòu)化數(shù)據(jù)。而另一方,MongoDB(獅子)是一個(gè)基于文檔的數(shù)據(jù)庫,它以文檔的形式存儲(chǔ)數(shù)據(jù)。雖然他們的方法不同,但依據(jù)組織化的需求,這兩者都需要數(shù)據(jù)存儲(chǔ)并選擇數(shù)據(jù)庫類型。
四、使用MongoDB有什么優(yōu)點(diǎn)?
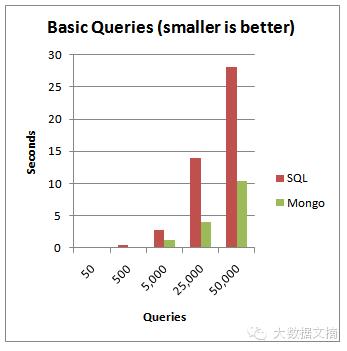
從上面的附圖你可以發(fā)現(xiàn),當(dāng)服務(wù)器上的查詢數(shù)量增加時(shí),MongoDB就明顯是一個(gè)勝利者。MongoDB 非常適用于實(shí)時(shí)分析,它有著低延遲以及針對(duì)需求的高可用性。
MongoDB已經(jīng)進(jìn)入了前沿領(lǐng)域,因?yàn)楦黝惤M織需要分析半結(jié)構(gòu)化、非結(jié)構(gòu)化以及地理或空間數(shù)據(jù),更因?yàn)楝F(xiàn)今世界原先的結(jié)構(gòu)化數(shù)據(jù)正在被快速的改變。
傳統(tǒng)的關(guān)系型數(shù)據(jù)庫系統(tǒng)不能完全應(yīng)付得了這些需求,因?yàn)樗鼈児逃械慕Y(jié)構(gòu)不允許它們處理這樣的需求。雖然關(guān)系型數(shù)據(jù)庫系統(tǒng)也在改變,來迎合數(shù)據(jù)的大爆發(fā),但最適合處理當(dāng)今數(shù)據(jù)的數(shù)據(jù)庫仍是像MongoDB這類文檔數(shù)據(jù)庫。
#p#
五、MongoDB的局限性是什么?
以下列舉了一些MongoDB的限制。
1.最大的文件不能超過16MB
2.最大文件嵌套層級(jí)為100(指文件嵌套文件再嵌套文件)
3.索引區(qū)不能超過1024字節(jié)。
4.每個(gè)集合最多為64個(gè)索引。
5.創(chuàng)建一個(gè)復(fù)合索引最多使用31個(gè)字段。
6.全文本搜索和地理位置索引是互斥的。
7.在32位機(jī)器上,一個(gè)固定集合(capped collection)中的文件數(shù)量大小是有限制的。但64位機(jī)器上則對(duì)文件數(shù)量大小沒有限制。
8.在Windows系統(tǒng)上,MongoDB不能存儲(chǔ)超過4TB的數(shù)據(jù)(去除日志后為8TB)
9.在單個(gè)復(fù)制集中最多可有12個(gè)節(jié)點(diǎn)。
10.在單個(gè)復(fù)制集中最多可有7個(gè)投票節(jié)點(diǎn)。
11.如要回滾超過300MB的數(shù)據(jù),需要進(jìn)行人工干預(yù)。
12.在分片集群(sharded cluster)中無法使用組命令。
13.在分片集群中無法使用 $isolated, $snapshot, geoSearch。
14.你無法在 $where中涉及到數(shù)據(jù)庫對(duì)象。
15.為了分片一個(gè)集合,它必須小于256GB。
16.在分片集群中對(duì)單條記錄(非多條)的更新/移出必須包含分片密鑰。同樣命令針對(duì)多條記錄執(zhí)行時(shí)則可以不包含分片密鑰。
17.分片密鑰最大值為512字節(jié)。
18.一旦分片完成,一個(gè)集合的分片密鑰值將無法改變。
除了這些限制以外,在關(guān)系型數(shù)據(jù)庫系統(tǒng)中用約束來防止數(shù)據(jù)被意外刪除的功能在MongoDB或其他NoSQL數(shù)據(jù)庫系統(tǒng)中無法實(shí)現(xiàn)。 也可能有其它問題,例如像下面列示的這個(gè),為了存儲(chǔ)多層數(shù)據(jù)而違反了標(biāo)準(zhǔn)范式。

一個(gè)用戶有許多朋友,并可能其中之一就是他自己。人們可能反復(fù)對(duì)自身進(jìn)行點(diǎn)贊、評(píng)論或兩者皆有的行為動(dòng)作。這種類型的反復(fù)模式使得它更難將一個(gè)活動(dòng)流反規(guī)范化(de-normalize)為一份獨(dú)立的文檔
MongoDB也像其它科技一般,非常公平的共享了它的局限性和缺陷,并且隨著版本更新,它們將很有希望被解決。



















