SRMT:一種融合共享記憶與稀疏注意力的多智能體強化學習框架
在人工智能(AI)和強化學習(RL)領域的發展進程中,長期記憶維持和決策優化一直是核心技術難點。傳統強化學習模型在經驗回溯方面存在局限性,這顯著制約了其在復雜動態環境中的應用效果。自反射記憶Transformer (SRMT)作為一種新型記憶增強型transformer架構,專注于提升基于AI的決策能力和多智能體協同效果。
本研究將系統闡述SRMT的技術架構、核心功能、應用場景及實驗數據,深入分析其在多智能體強化學習(MARL)領域的技術優勢。
SRMT技術架構概述
SRMT是一種面向多智能體系統的記憶增強型transformer模型。該模型通過實現高效的記憶共享機制,使智能體能夠進行經驗存儲、檢索和反饋分析,從而在傳統的transformer與強化學習架構基礎上實現了技術突破。
SRMT核心技術特征:
- 共享循環記憶結構:實現智能體間的隱式知識傳遞,提升協同效率
- 自注意力與交叉注意力機制:優化歷史信息與實時數據的融合處理
- 架構可擴展性:支持單智能體到多智能體環境的無縫遷移
- 決策能力優化:基于歷史經驗實現策略優化與理性決策
- 動態環境適應性:在復雜導航規劃等任務中展現出顯著優勢
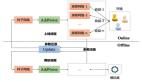
SRMT技術實現機制

1、智能體策略模塊
- 空間特征編碼器:執行輸入數據的特征提取
- 核心運算模塊:采用Actor-Critic框架優化學習策略
- 動作解碼器:生成動作空間概率分布
2、記憶處理機制
- 記憶單元:負責經驗數據的存儲與更新
- 交叉注意力模塊:優化記憶信息檢索效率
- 自注意力模塊:對歷史關鍵事件進行決策權重分配
3、雙層記憶架構
- 獨立記憶單元:維護單個智能體的專屬記憶空間
- 共享記憶池:支持多智能體間的協同學習機制
實驗環境配置

實驗環境包含多樣化場景,涵蓋迷宮結構與路徑規劃任務。
密集獎勵條件下的擴展性驗證

在長度達1000單位的復雜走廊環境中,SRMT智能體表現出優秀的泛化能力,在稀疏獎勵和負獎勵場景下均保持穩定性能。
研究團隊在密集獎勵的走廊導航任務中對SRMT進行了系統評估,智能體能夠獲取持續反饋信號。通過對記憶保持與即時決策的動態平衡,該模型始終保持領先性能。實驗結果驗證了SRMT在復雜環境中學習最優策略的能力。
性能評估與對比分析

不同環境下系統吞吐量對比分析,驗證SRMT相較于基準模型的效率優勢。
研究團隊將SRMT與傳統的RNN、Transformer及混合記憶模型在多種多智能體強化學習環境中進行了對比測試。數據表明SRMT在以下指標上全面超越基準水平:
- 記憶維持效率
- 多智能體協同成功率
- 策略收斂速度
- 動態任務決策穩定性
SRMT技術創新價值和未來研究方向
- 自適應學習能力:實現實時學習與環境適應
- 系統擴展性:支持不同規模智能體系統的高效運行
- 長期記憶性能:保證關鍵信息的持久保存
- 計算資源優化:實現快速高效的數據處理
基于SRMT在AI決策領域的技術優勢,未來研究可重點關注:
- 混合元學習技術的應用
- 深度模仿學習的系統集成
- 自主系統與機器人領域的實踐應用
總結
自反射記憶Transformer (SRMT)在多智能體強化學習領域實現了關鍵技術突破。通過共享循環記憶與transformer處理機制的創新集成,有效提升了系統的決策能力、擴展性與適應性。該技術在機器人控制、AI仿真及自主系統等領域具有廣泛的應用前景,為新一代智能模型的發展提供了重要參考。