聽(tīng)說(shuō)你的多智能體強(qiáng)化學(xué)習(xí)算法不work?你用對(duì)MAPPO了嗎
清華和UC伯克利聯(lián)合研究發(fā)現(xiàn),在不進(jìn)行任何算法或者網(wǎng)絡(luò)架構(gòu)變動(dòng)的情況下,用 MAPPO(Multi-Agent PPO)在 3 個(gè)具有代表性的多智能體任務(wù)(Multi-Agent Particle World, StarCraftII, Hanabi)中取得了與 SOTA 算法相當(dāng)?shù)男阅堋?/p>

近些年,多智能體強(qiáng)化學(xué)習(xí)(Multi-Agent Reinforcement Learning,MARL)取得了突破性進(jìn)展,例如 DeepMind 開(kāi)發(fā)的 AlphaStar 在星際爭(zhēng)霸 II 中打敗了職業(yè)星際玩家,超過(guò)了 99.8% 的人類玩家;OpenAI Five 在 DOTA2 中多次擊敗世界冠軍隊(duì)伍,是首個(gè)在電子競(jìng)技比賽中擊敗冠軍的人工智能系統(tǒng);以及在仿真物理環(huán)境 hide-and-seek 中訓(xùn)練出像人一樣可以使用工具的智能體。我們提到的這些智能體大多是采用 on-policy 算法(例如 IMPALA[8])訓(xùn)練得到的,這就意味著需要很高的并行度和龐大的算力支持,例如 OpenAI Five 消耗了 12.8 萬(wàn)塊 CPU 和 256 塊 P100 GPU 來(lái)收集數(shù)據(jù)樣本和訓(xùn)練網(wǎng)絡(luò)。
然而,大多數(shù)的學(xué)術(shù)機(jī)構(gòu)很難配備這個(gè)量級(jí)的計(jì)算資源。因此,MARL 領(lǐng)域幾乎已經(jīng)達(dá)成共識(shí):與 on-policy 算法(例如 PPO[3])相比,在計(jì)算資源有限的情況下,off-policy 算法(例如 MADDPG[5],QMix[6])因其更高的采樣效率更適合用來(lái)訓(xùn)練智能體,并且也演化出一系列解決某些具體問(wèn)題(domain-specific)的 SOTA 算法(例如 SAD[9],RODE[7])。
但是,來(lái)自清華大學(xué)與 UC 伯克利的研究者在一篇論文中針對(duì)這一傳統(tǒng)認(rèn)知提出了不同的觀點(diǎn):MARL 算法需要綜合考慮數(shù)據(jù)樣本效率(sample efficiency)和算法運(yùn)行效率(wall-clock runtime efficiency)。在有限計(jì)算資源的條件下,與 off-policy 算法相比,on-policy 算法 --MAPPO(Multi-Agent PPO)具有顯著高的算法運(yùn)行效率和與之相當(dāng)(甚至更高)的數(shù)據(jù)樣本效率。有趣的是,研究者發(fā)現(xiàn)只需要對(duì) MAPPO 進(jìn)行極小的超參搜索,在不進(jìn)行任何算法或者網(wǎng)絡(luò)架構(gòu)變動(dòng)的情況下就可以取得與 SOTA 算法相當(dāng)?shù)男阅堋8M(jìn)一步地,還貼心地給出了 5 條可以提升 MAPPO 性能的重要建議,并且開(kāi)源了一套優(yōu)化后的 MARL 算法源碼(代碼地址:
https://github.com/marlbenchmark/on-policy)。
所以,如果你的 MARL 算法一直不 work,不妨參考一下這項(xiàng)研究,有可能是你沒(méi)有用對(duì)算法;如果你專注于研究 MARL 算法,不妨嘗試將 MAPPO 作為 baseline,說(shuō)不定可以提高任務(wù)基準(zhǔn);如果你處于 MARL 研究入門(mén)階段,這套源碼值得擁有,據(jù)說(shuō)開(kāi)發(fā)完備,簡(jiǎn)單易上手。這篇論文由清華大學(xué)的汪玉、吳翼等人與 UC 伯克利的研究者合作完成。研究者后續(xù)會(huì)持續(xù)開(kāi)源更多優(yōu)化后的算法及任務(wù)(倉(cāng)庫(kù)指路:
https://github.com/marlbenchmark)

論文鏈接:
https://arxiv.org/abs/2103.01955
什么是 MAPPO
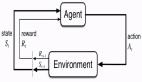
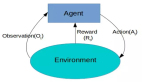
PPO(Proximal Policy Optimization)[4]是一個(gè)目前非常流行的單智能體強(qiáng)化學(xué)習(xí)算法,也是 OpenAI 在進(jìn)行實(shí)驗(yàn)時(shí)首選的算法,可見(jiàn)其適用性之廣。PPO 采用的是經(jīng)典的 actor-critic 架構(gòu)。其中,actor 網(wǎng)絡(luò),也稱之為 policy 網(wǎng)絡(luò),接收局部觀測(cè)(obs)并輸出動(dòng)作(action);critic 網(wǎng)絡(luò),也稱之為 value 網(wǎng)絡(luò),接收狀態(tài)(state)輸出動(dòng)作價(jià)值(value),用于評(píng)估 actor 網(wǎng)絡(luò)輸出動(dòng)作的好壞。可以直觀理解為評(píng)委(critic)在給演員(actor)的表演(action)打分(value)。MAPPO(Multi-agent PPO)是 PPO 算法應(yīng)用于多智能體任務(wù)的變種,同樣采用 actor-critic 架構(gòu),不同之處在于此時(shí) critic 學(xué)習(xí)的是一個(gè)中心價(jià)值函數(shù)(centralized value function),簡(jiǎn)而言之,此時(shí) critic 能夠觀測(cè)到全局信息(global state),包括其他 agent 的信息和環(huán)境的信息。
實(shí)驗(yàn)環(huán)境
接下來(lái)介紹一下論文中的實(shí)驗(yàn)環(huán)境。論文選擇了 3 個(gè)具有代表性的協(xié)作 Multi-agent 任務(wù),之所以選擇協(xié)作任務(wù)的一個(gè)重要原因是合作任務(wù)具有明確的評(píng)價(jià)指標(biāo),便于對(duì)不同的算法進(jìn)行比較。
第一個(gè)環(huán)境是 OpenAI 開(kāi)源的 Multi-agent Particle World(MPE)任務(wù)(源代碼指路:
https://github.com/openai/multiagent-particle-envs)[1],輕量級(jí)的環(huán)境和抽象多樣的任務(wù)設(shè)定使之成為快速驗(yàn)證 MARL 算法的首選測(cè)試平臺(tái)。在 MPE 中有 3 個(gè)協(xié)作任務(wù),分別是 Spread,Comm 和 Reference,如圖 1 所示。
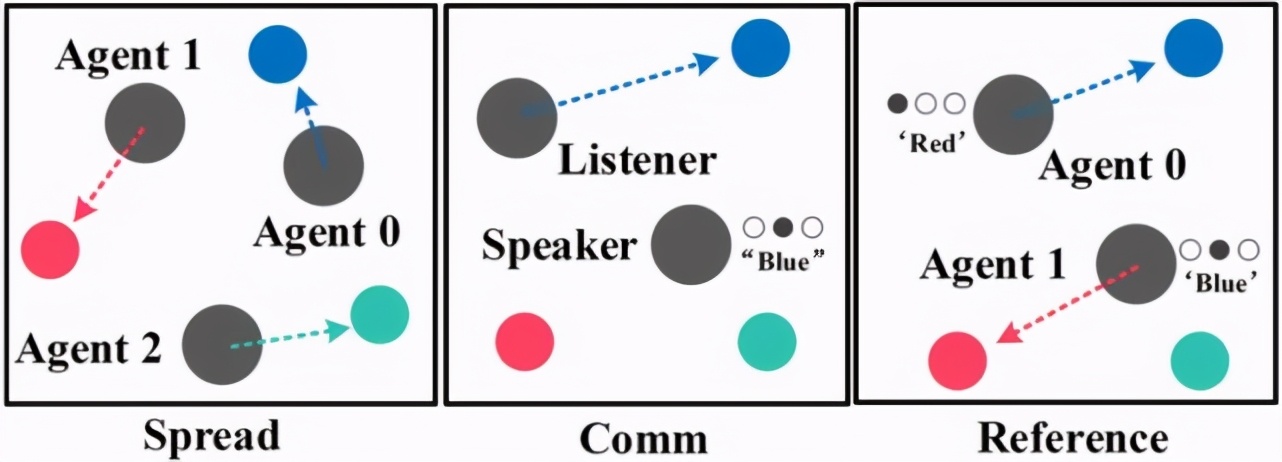
圖 1:MPE 環(huán)境中的 3 個(gè)子任務(wù):Spread,Comm 和 Reference
第二個(gè)環(huán)境是 MARL 領(lǐng)域著名的 StarCraftII(星際爭(zhēng)霸 II)任務(wù)(源代碼:
https://github.com/oxwhirl/smac),如圖 2 所示。這一任務(wù)最初由 M. Samvelyan 等人提出 [2],提供了 23 個(gè)實(shí)驗(yàn)地圖,agent 數(shù)量從 2 到 27 不等,我方 agent 需要進(jìn)行協(xié)作來(lái)打敗敵方 agent 以贏得游戲。自該任務(wù)發(fā)布以來(lái),有很多研究人員針對(duì)其特點(diǎn)進(jìn)行了算法研究,例如經(jīng)典算法 QMix[6] 以及最新發(fā)表的 RODE[7]等等。由于 StarCraftII 經(jīng)過(guò)了版本迭代,并且不同版本之間性能有差距,特別說(shuō)明,這篇論文采用的是最新版本 SC2.4.10。
圖 2:StarCraftII 環(huán)境中的 2 個(gè)代表性地圖:Corridor 和 2c vs. 64zg
第三個(gè)環(huán)境是由 Nolan Bard 等人 [3] 在 2019 年提出的一個(gè)純協(xié)作任務(wù) Hanabi(源代碼:
https://github.com/deepmind/hanabi-learning-environment),Hanabi 是一個(gè) turn-based 的紙牌類游戲,也就是每一輪只有一個(gè)玩家可以出牌,相較于之前的多智能體任務(wù),Hanabi 的一個(gè)重要特點(diǎn)是純合作,每個(gè)玩家需要對(duì)其他玩家的意圖進(jìn)行推理,完成協(xié)作才能獲得分?jǐn)?shù),Hanabi 的玩家數(shù)可以是 2-5 個(gè),圖 3 是 4 個(gè)玩家的任務(wù)示意圖,感興趣的讀者可以自己嘗試玩一下。
圖 3:4 個(gè)玩家的 Hanabi-Full 任務(wù)示意圖
實(shí)驗(yàn)結(jié)果
首先來(lái)看一下論文給出的實(shí)驗(yàn)結(jié)果,特別注意,論文所有的實(shí)驗(yàn)都在一臺(tái)主機(jī)中完成,該主機(jī)的配置是 256 GB 內(nèi)存, 一塊 64 核 CPU 和一塊 GeForce RTX 3090 24GB 顯卡。另外,研究者表示,本文的所有的算法都進(jìn)行了微調(diào)(fine-tune),所以本文中的復(fù)現(xiàn)的某些實(shí)驗(yàn)結(jié)果會(huì)優(yōu)于原論文。
(1)MPE 環(huán)境
圖 4 展示了在 MPE 中不同算法的數(shù)據(jù)樣本效率和算法運(yùn)行效率對(duì)比,其中 IPPO(Independent PPO)表示的是 critic 學(xué)習(xí)一個(gè)分布式的價(jià)值函數(shù)(decentralized value function),即 critic 與 actor 的輸入均為局部觀測(cè),IPPO 和 MAPPO 超參保持一致;MADDPG[5]是 MARL 領(lǐng)域十分流行的 off-policy 算法,也是針對(duì) MPE 開(kāi)發(fā)的一個(gè)算法,QMix[6]是針對(duì) StarCraftII 開(kāi)發(fā)的 MARL 算法,也是 StarCraftII 中的常用 baseline。
從圖 4 可以看出與其他算法相比,MAPPO 不僅具有相當(dāng)?shù)臄?shù)據(jù)樣本效率和性能表現(xiàn)(performance)(圖(a)),同時(shí)還具有顯著高的算法運(yùn)行效率(圖(b))。
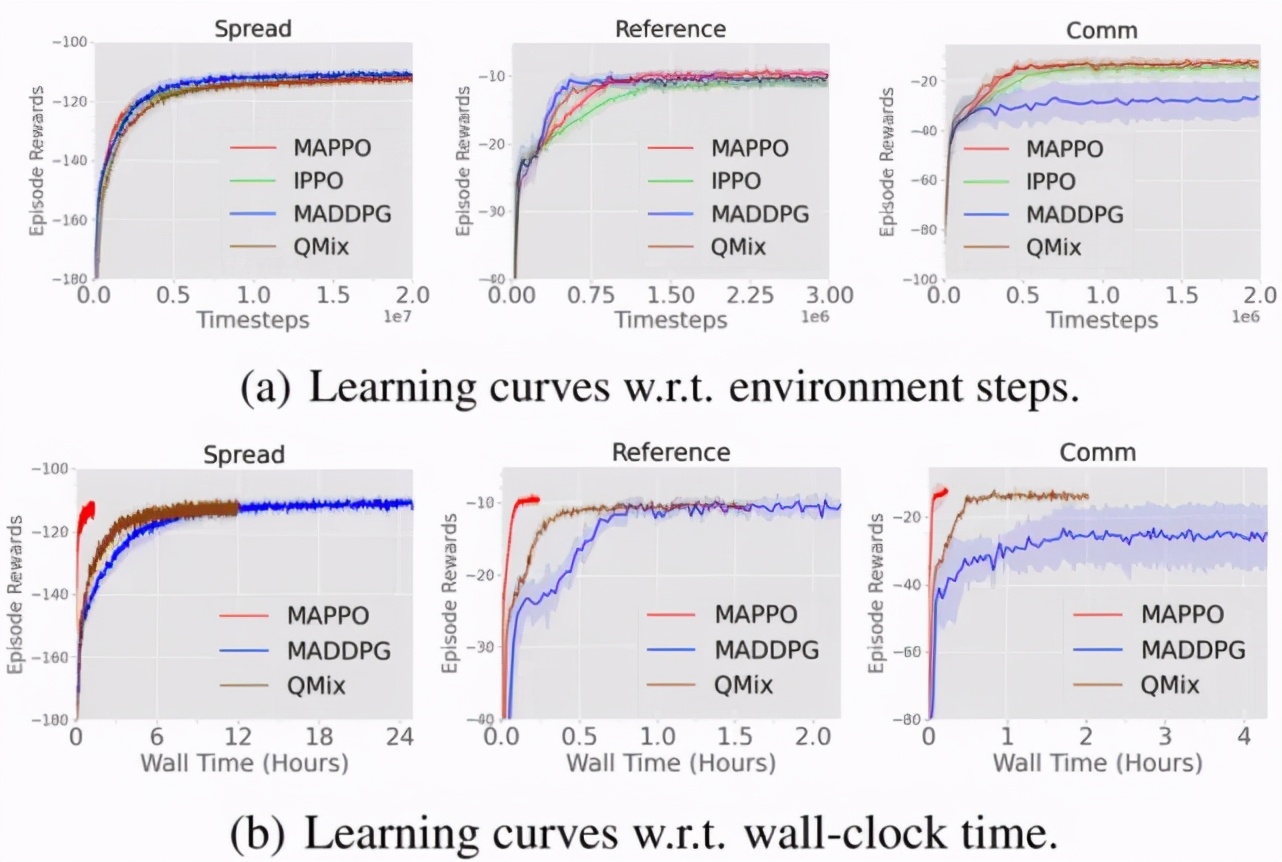
圖 4:在 MPE 中不同算法的數(shù)據(jù)樣本效率和算法運(yùn)行效率對(duì)比
(2)StarCraftII 環(huán)境
表 1 展示了 MAPPO 與 IPPO,QMix 以及針對(duì) StarCraftII 的開(kāi)發(fā)的 SOTA 算法 RODE 的勝率對(duì)比,在截?cái)嘀?10M 數(shù)據(jù)的情況下,MAPPO 在 19/23 個(gè)地圖的勝率都達(dá)到了 SOTA,除了 3s5z vs. 3s6z,其他地圖與 SOTA 算法的差距小于 5%,而 3s5z vs. 3s6z 在截?cái)嘀?10M 時(shí)并未完全收斂,如果截?cái)嘀?25M,則可以達(dá)到 91% 的勝率。
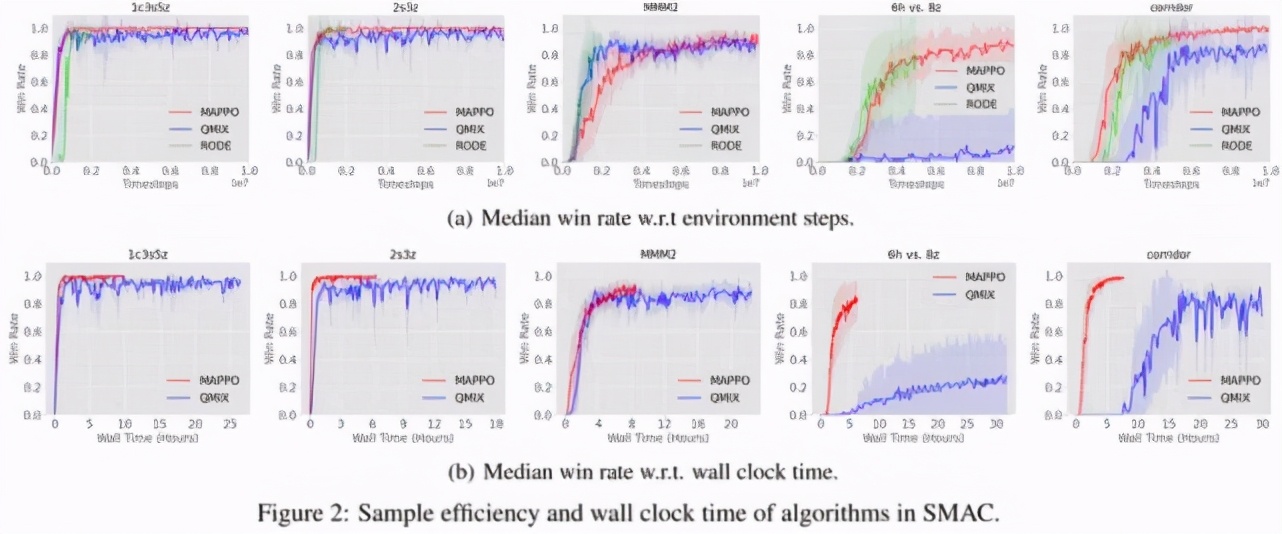
圖 5 表示在 StarCraftII 中不同算法的數(shù)據(jù)樣本效率和算法運(yùn)行效率對(duì)比。可以看出 MAPPO 實(shí)際上與 QMix 和 RODE 具有相當(dāng)?shù)臄?shù)據(jù)樣本效率,以及更快的算法運(yùn)行效率。由于在實(shí)際訓(xùn)練 StarCraftII 任務(wù)的時(shí)候僅采用 8 個(gè)并行環(huán)境,而在 MPE 任務(wù)中采用了 128 個(gè)并行環(huán)境,所以圖 5 的算法運(yùn)行效率沒(méi)有圖 4 差距那么大,但是即便如此,依然可以看出 MAPPO 驚人的性能表現(xiàn)和運(yùn)行效率。
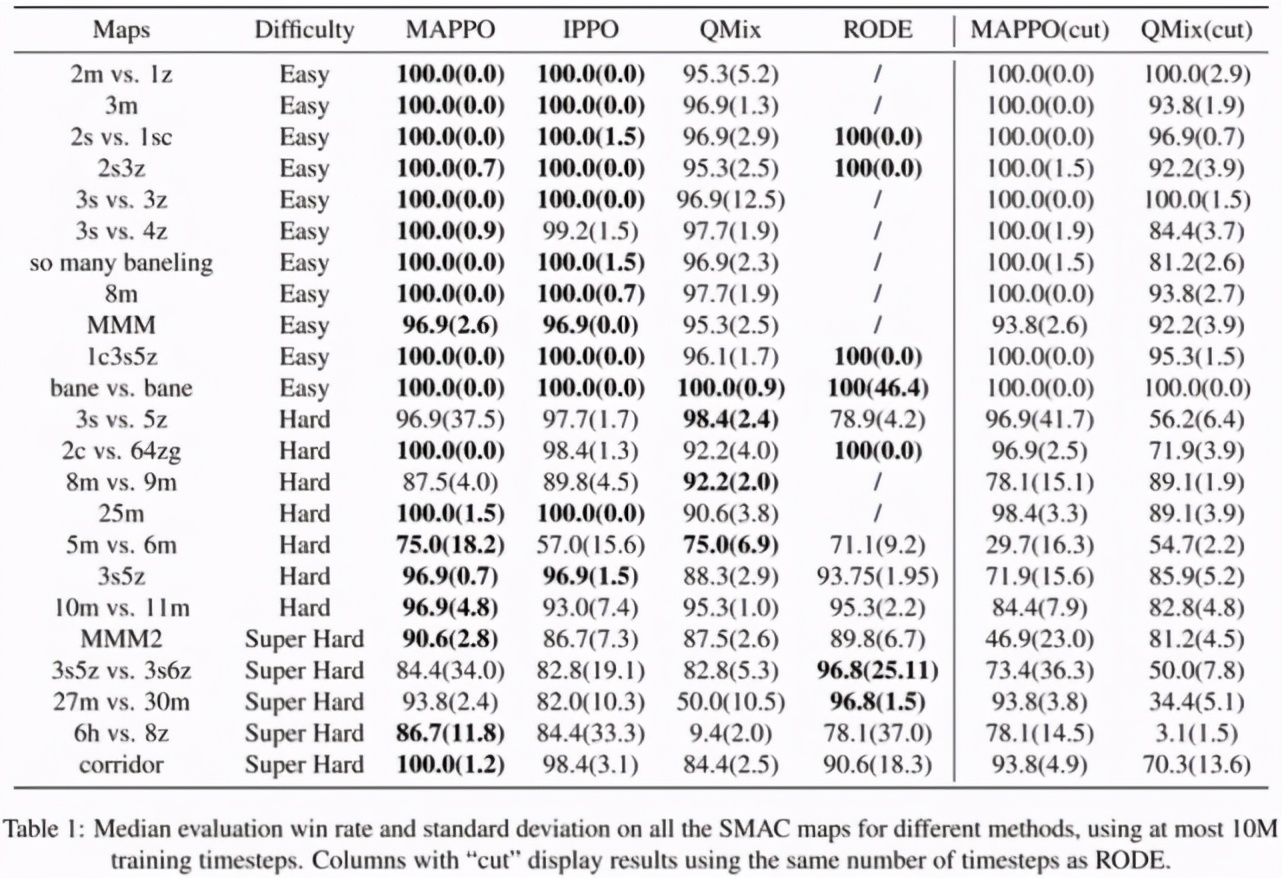
表 1:不同算法在 StarCraftII 的 23 個(gè)地圖中的勝率對(duì)比,其中 cut 標(biāo)記表示將 MAPPO 和 QMix 截?cái)嘀僚c RODE 相同的步數(shù),目的是為了與 SOTA 算法公平對(duì)比。
(3)Hanabi 環(huán)境
SAD 是針對(duì) Hanabi 任務(wù)開(kāi)發(fā)的一個(gè) SOTA 算法,值得注意的是,SAD 的得分取自原論文,原作者跑了 13 個(gè)隨機(jī)種子,每個(gè)種子需要約 10B 數(shù)據(jù),而由于時(shí)間限制,MAPPO 只跑了 4 個(gè)隨機(jī)種子,每個(gè)種子約 7.2B 數(shù)據(jù)。從表 2 可以看出 MAPPO 依然可以達(dá)到與 SAD 相當(dāng)?shù)牡梅帧?/p>
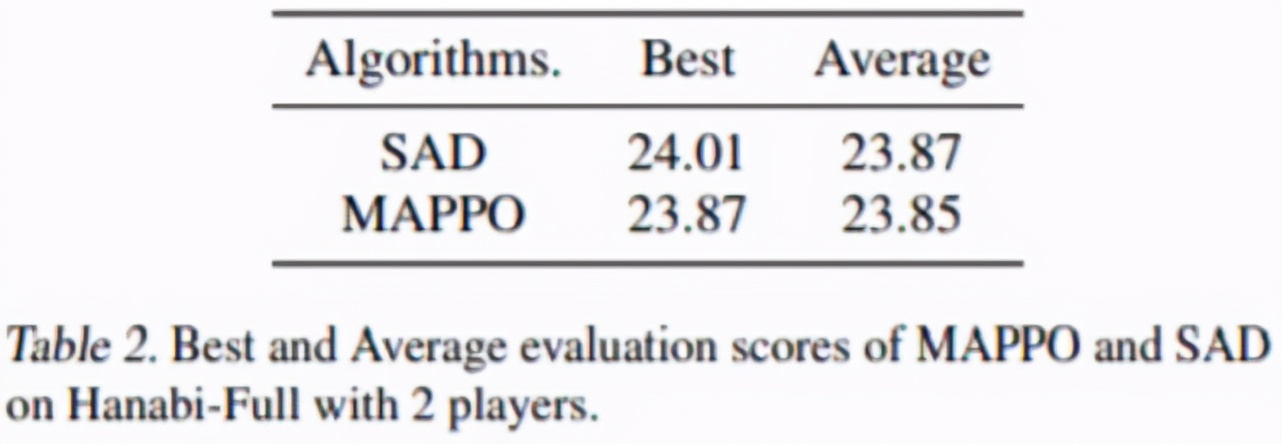
表 2:MAPPO 和 SAD 在 2 個(gè)玩家的 Hanabi-Full 任務(wù)的得分對(duì)比。
5 條小建議
看完了論文給出的實(shí)驗(yàn)結(jié)果,那么,回到最開(kāi)始的問(wèn)題,你用對(duì) MAPPO 了嗎?
研究者發(fā)現(xiàn),即便多智能體任務(wù)與單智能體任務(wù)差別很大,但是之前在其他單智能體任務(wù)中的給出的 PPO 實(shí)現(xiàn)建議依然很有用,例如 input normalization,value clip,max gradient norm clip,orthogonal initialization,GAE normalization 等。但是除此之外,研究者額外給出了針對(duì) MARL 領(lǐng)域以及其他易被忽視的因素的 5 條建議。
Value normalization: 研究者采用 PopArt 對(duì) value 進(jìn)行 normalization,并且指出使用 PopArt 有益無(wú)害。
Agent Specific Global State: 采用 agent-specific 的全局信息,避免全局信息遺漏以及維度過(guò)高。值得一提的是,研究者發(fā)現(xiàn) StarCraftII 中原有的全局信息存在信息遺漏,甚至其所包含的信息少于 agent 的局部觀測(cè),這也是直接將 MAPPO 應(yīng)用在 StarCraftII 中性能表現(xiàn)不佳的重要原因。
Training Data Usage: 簡(jiǎn)單任務(wù)中推薦使用 15 training epochs,而對(duì)于較難的任務(wù),嘗試 10 或者 5 training epochs。除此之外,盡量使用一整份的訓(xùn)練數(shù)據(jù),而不要切成很多小份(mini-batch)訓(xùn)練。
Action Masking: 在多智能體任務(wù)中經(jīng)常出現(xiàn) agent 無(wú)法執(zhí)行某些 action 的情況,建議無(wú)論前向執(zhí)行還是反向傳播時(shí),都應(yīng)將這些無(wú)效動(dòng)作屏蔽掉,使其不參與動(dòng)作概率計(jì)算。
Death Masking: 在多智能體任務(wù)中,也經(jīng)常會(huì)出現(xiàn)某個(gè) agent 或者某些 agents 中途死掉的情況(例如 StarCraftII)。當(dāng) agent 死亡后,僅保留其 agent id,將其他信息屏蔽能夠?qū)W得更加準(zhǔn)確的狀態(tài)價(jià)值函數(shù)。
更多的實(shí)驗(yàn)細(xì)節(jié)和分析可以查看論文原文。


 分享到微信
分享到微信  分享到微博
分享到微博