鏈?zhǔn)澜纾阂环N簡(jiǎn)單而有效的人類行為Agent模型強(qiáng)化學(xué)習(xí)框架
強(qiáng)化學(xué)習(xí)是一種機(jī)器學(xué)習(xí)的方法,它通過(guò)讓智能體(Agent)與環(huán)境交互,從而學(xué)習(xí)如何選擇最優(yōu)的行動(dòng)來(lái)最大化累積的獎(jiǎng)勵(lì)。強(qiáng)化學(xué)習(xí)在許多領(lǐng)域都有廣泛的應(yīng)用,例如游戲、機(jī)器人、自動(dòng)駕駛等。強(qiáng)化學(xué)習(xí)也可以用于干預(yù)人類的行為,幫助人類實(shí)現(xiàn)他們的長(zhǎng)期目標(biāo),例如戒煙、減肥、健身等。這些任務(wù)通常是摩擦性的,也就是說(shuō),它們需要人類付出長(zhǎng)期的努力,而不是立即獲得滿足。在這些任務(wù)中,人類往往表現(xiàn)出有限的理性,也就是說(shuō)他們的行為并不總是符合他們的最佳利益,而是受到一些認(rèn)知偏差、情緒影響、環(huán)境干擾等因素的影響。因此,如何用強(qiáng)化學(xué)習(xí)干預(yù)人類的有限理性,使其在摩擦性的任務(wù)中表現(xiàn)更好,是一個(gè)具有重要意義和挑戰(zhàn)性的問(wèn)題。
為了解決這個(gè)問(wèn)題,一篇最近發(fā)表在AAMAS2024會(huì)議上的論文《Reinforcement Learning Interventions on Boundedly Rational Human Agents in Frictionful Tasks》提出了一種行為模型強(qiáng)化學(xué)習(xí)(BMRL)的框架,用于讓人工智能干預(yù)人類在摩擦性任務(wù)中的行為。該論文的作者是來(lái)自哈佛大學(xué)、劍橋大學(xué)和密歇根大學(xué)的五位研究人員,他們分別是Eura Nofshin、Siddharth Swaroop、Weiwei Pan、Susan Murphy和Finale Doshi-Velez。他們的研究受到了Simons Foundation、National Science Foundation、National Institute of Biomedical Imaging and Bioengineering等機(jī)構(gòu)的資助。他們的論文的主要貢獻(xiàn)有以下幾點(diǎn):
1)他們提出了一種新的Agent模型,稱為鏈?zhǔn)澜纾–hainWorld),用于描述Agent在摩擦性任務(wù)中的行為。鏈?zhǔn)澜缡且环N簡(jiǎn)單的馬爾可夫決策過(guò)程(MDP)模型,其中Agent可以選擇執(zhí)行或跳過(guò)任務(wù),從而增加或減少他們達(dá)到目標(biāo)的概率。人工智能可以通過(guò)改變Agent的折扣因子或獎(jiǎng)勵(lì)來(lái)影響人類的決策。鏈?zhǔn)澜绲膬?yōu)點(diǎn)是它可以快速地對(duì)人類進(jìn)行個(gè)性化,也可以解釋人類的行為背后的原因。
2)他們引入了一種基于BMRL的Agent模型之間的等價(jià)性的概念,用于判斷不同的Agent模型是否會(huì)導(dǎo)致相同的人工智能干預(yù)策略。他們證明了鏈?zhǔn)澜缡且活惛鼜?fù)雜的人類MDP的等價(jià)模型,只要它們導(dǎo)致相同的三窗口人工智能策略,即由無(wú)效窗口、干預(yù)窗口和無(wú)需干預(yù)窗口組成的策略。他們還給出了一些與鏈?zhǔn)澜绲葍r(jià)的更復(fù)雜的人類MDP的例子,例如單調(diào)鏈?zhǔn)澜纭⑦M(jìn)展世界和多鏈?zhǔn)澜纾@些模型可以捕捉一些與人類行為相關(guān)的有意義的特征。
3)他們通過(guò)實(shí)驗(yàn)分析了鏈?zhǔn)澜绲聂敯粜裕串?dāng)真實(shí)的Agent模型與鏈?zhǔn)澜绮煌耆ヅ浠虿坏葍r(jià)時(shí),人工智能使用鏈?zhǔn)澜邕M(jìn)行干預(yù)的性能如何。他們發(fā)現(xiàn)鏈?zhǔn)澜缡且环N有效且魯棒的Agent模型,可以用于設(shè)計(jì)人工智能干預(yù)策略,在大多數(shù)情況下,它可以達(dá)到或接近最佳的性能,即使在一些極端的情況下,它也可以保持一定的水平。
我們將對(duì)這篇論文的主要內(nèi)容進(jìn)行更詳細(xì)的解讀和分析,從而幫助您更好地理解和評(píng)價(jià)這項(xiàng)研究的質(zhì)量和意義。
首先,我們來(lái)看看什么是行為模型強(qiáng)化學(xué)習(xí)(BMRL)的框架,以及為什么它是一種適合用于干預(yù)人類行為的方法。BMRL是一種基于模型的強(qiáng)化學(xué)習(xí)的方法,它假設(shè)人工智能可以觀察到人類的狀態(tài)、行動(dòng)和獎(jiǎng)勵(lì),從而建立一個(gè)Agent的MDP模型。Agent的MDP模型由一組狀態(tài)、一組行動(dòng)、一個(gè)轉(zhuǎn)移函數(shù)、一個(gè)獎(jiǎng)勵(lì)函數(shù)和一個(gè)折扣因子組成。Agent的目標(biāo)是通過(guò)選擇最優(yōu)的行動(dòng)來(lái)最大化他們的期望累積獎(jiǎng)勵(lì)。然而Agent的MDP模型可能存在一些問(wèn)題,導(dǎo)致Agent的行為與他們的目標(biāo)不一致,例如:
人類的折扣因子可能過(guò)低,導(dǎo)致人類過(guò)于看重短期的獎(jiǎng)勵(lì),而忽視長(zhǎng)期的后果。例如,一個(gè)想要戒煙的人可能會(huì)因?yàn)橐粫r(shí)的癮而放棄他的計(jì)劃。
人類的獎(jiǎng)勵(lì)函數(shù)可能存在一些摩擦,導(dǎo)致人類執(zhí)行任務(wù)的成本過(guò)高,而收益過(guò)低。例如,一個(gè)想要減肥的人可能會(huì)因?yàn)檫\(yùn)動(dòng)的痛苦而不愿意堅(jiān)持他的計(jì)劃。
人類的轉(zhuǎn)移函數(shù)可能存在一些不確定性,導(dǎo)致人類執(zhí)行任務(wù)的結(jié)果難以預(yù)測(cè),而風(fēng)險(xiǎn)過(guò)高。例如,一個(gè)想要學(xué)習(xí)一門新語(yǔ)言的人可能會(huì)因?yàn)閷W(xué)習(xí)的難度而不敢嘗試他的計(jì)劃。

圖1:BMRL概述,人類代理與環(huán)境交互,如標(biāo)準(zhǔn)RL中所示。人工智能主體的行為會(huì)影響人類主體。人工智能環(huán)境由人工智能主體+環(huán)境構(gòu)成。
在這些情況下,人工智能可以通過(guò)干預(yù)人類的MDP模型的參數(shù),來(lái)改變?nèi)祟惖男袨椋蛊涓咏麄兊哪繕?biāo)。例如,人工智能可以通過(guò)以下方式來(lái)干預(yù)人類的行為。
一是通過(guò)提供一些正向的反饋或獎(jiǎng)勵(lì),來(lái)提高人類的折扣因子,從而增強(qiáng)人類對(duì)長(zhǎng)期目標(biāo)的關(guān)注。例如,人工智能可以通過(guò)發(fā)送一些鼓勵(lì)的信息或提供一些小禮物,來(lái)激勵(lì)一個(gè)想要戒煙的人堅(jiān)持他的計(jì)劃。
二是通過(guò)提供一些便利的工具或服務(wù),來(lái)降低人類執(zhí)行任務(wù)的成本,從而增加人類的收益。例如,人工智能可以通過(guò)提供一些個(gè)性化的運(yùn)動(dòng)計(jì)劃或設(shè)備,來(lái)幫助一個(gè)想要減肥的人堅(jiān)持他的計(jì)劃。
三是通過(guò)提供一些有用的信息或建議,來(lái)降低人類執(zhí)行任務(wù)的不確定性,從而減少人類的風(fēng)險(xiǎn)。例如,人工智能可以通過(guò)提供一些有效的學(xué)~~~
接下來(lái),我們來(lái)看看什么是鏈?zhǔn)澜纾–hainWorld),以及為什么它是一種簡(jiǎn)單而有效的人類模型。鏈?zhǔn)澜缡且环N由作者提出的人類MDP模型,它可以用來(lái)描述人類在摩擦性任務(wù)中的行為。
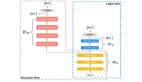
 圖2:鏈?zhǔn)澜绲膱D形表示。
圖2:鏈?zhǔn)澜绲膱D形表示。
鏈?zhǔn)澜绲幕窘Y(jié)構(gòu)如下:
鏈?zhǔn)澜缬??個(gè)狀態(tài)組成,每個(gè)狀態(tài)對(duì)應(yīng)于人類執(zhí)行任務(wù)的進(jìn)度。狀態(tài)??0表示人類剛開(kāi)始執(zhí)行任務(wù),狀態(tài)?????1表示人類即將完成任務(wù),狀態(tài)????表示人類已經(jīng)完成任務(wù),也就是達(dá)到了他們的長(zhǎng)期目標(biāo)。狀態(tài)????表示人類放棄了任務(wù),也就是與他們的長(zhǎng)期目標(biāo)背道而馳。
鏈?zhǔn)澜缬袃蓚€(gè)行動(dòng),??=1表示人類執(zhí)行任務(wù),??=0表示人類跳過(guò)任務(wù)。當(dāng)人類執(zhí)行任務(wù)時(shí),他們有一定的概率????增加進(jìn)度,也有一定的概率???減少進(jìn)度。當(dāng)人類跳過(guò)任務(wù)時(shí),他們有一定的概率????放棄任務(wù),也有一定的概率1?????保持進(jìn)度不變。人類的行動(dòng)選擇取決于他們的折扣因子???和獎(jiǎng)勵(lì)函數(shù)??。
鏈?zhǔn)澜绲莫?jiǎng)勵(lì)函數(shù)??由四個(gè)參數(shù)組成,分別是????、????、????和???。????表示人類完成任務(wù)的獎(jiǎng)勵(lì),????表示人類放棄任務(wù)的獎(jiǎng)勵(lì),????表示人類執(zhí)行任務(wù)的成本,???表示人類減少進(jìn)度的懲罰。人類的獎(jiǎng)勵(lì)函數(shù)反映了他們對(duì)任務(wù)的價(jià)值和摩擦的感受。
鏈?zhǔn)澜绲恼劭垡蜃???表示人類對(duì)未來(lái)獎(jiǎng)勵(lì)的重視程度,它決定了人類的行為是否與他們的長(zhǎng)期目標(biāo)一致。人類的折扣因子可能受到一些因素的影響,例如情緒、注意力、自我控制等。人類的折扣因子反映了他們的有限理性和認(rèn)知偏差。
 圖片
圖片
圖3:具有不同鏈?zhǔn)澜鐓?shù)的兩個(gè)人的不同最優(yōu)人工智能策略示例。每個(gè)方塊都是一個(gè)鏈?zhǔn)澜鐮顟B(tài)。一????意味著AI應(yīng)該選擇行動(dòng)來(lái)減少????,雖然????意味著AI應(yīng)該選擇行動(dòng)來(lái)增加??. 紅色實(shí)線和藍(lán)色虛線顯示干預(yù)窗口的開(kāi)始和結(jié)束。
鏈?zhǔn)澜绲膬?yōu)點(diǎn)是它可以用少量的參數(shù)來(lái)描述人類在摩擦性任務(wù)中的行為,從而使人工智能可以快速地對(duì)人類進(jìn)行個(gè)性化。人工智能可以通過(guò)觀察人類的狀態(tài)、行動(dòng)和獎(jiǎng)勵(lì),來(lái)估計(jì)人類的MDP模型的參數(shù),然后根據(jù)人類的MDP模型來(lái)選擇最優(yōu)的干預(yù)策略。人工智能的干預(yù)策略可以通過(guò)改變?nèi)祟惖恼劭垡蜃踊颡?jiǎng)勵(lì)來(lái)實(shí)現(xiàn),從而影響人類的行為選擇。例如,人工智能可以通過(guò)提供一些正向的反饋或獎(jiǎng)勵(lì),來(lái)提高人類的折扣因子,從而增強(qiáng)人類對(duì)長(zhǎng)期目標(biāo)的關(guān)注。人工智能也可以通過(guò)提供一些便利的工具或服務(wù),來(lái)降低人類執(zhí)行任務(wù)的成本,從而增加人類的收益。
鏈?zhǔn)澜绲牧硪粋€(gè)優(yōu)點(diǎn)是它可以解釋人類的行為背后的原因,從而使人工智能可以與人類進(jìn)行有效的溝通和合作。人工智能可以通過(guò)分析人類的MDP模型的參數(shù),來(lái)了解人類的行為動(dòng)機(jī)、偏好、障礙和困難。人工智能也可以通過(guò)向人類提供一些有用的信息或建議,來(lái)幫助人類理解他們的行為后果、風(fēng)險(xiǎn)和機(jī)會(huì)。人工智能還可以通過(guò)向人類展示他們的MDP模型的參數(shù),來(lái)促進(jìn)人類的自我反思和自我調(diào)節(jié)。人工智能的這些功能可以增加人類對(duì)人工智能的信任和接受度,從而提高人工智能干預(yù)的效果和滿意度。
我們來(lái)看看作者是如何證明鏈?zhǔn)澜绲淖顑?yōu)人工智能策略具有三窗口的形式,以及這種形式的意義和優(yōu)勢(shì)。作者首先給出了鏈?zhǔn)澜绲淖顑?yōu)人工智能策略的定義,即在每個(gè)狀態(tài)下,選擇能夠使人類的期望累積獎(jiǎng)勵(lì)最大化的干預(yù)策略。作者然后利用動(dòng)態(tài)規(guī)劃的方法,推導(dǎo)出了鏈?zhǔn)澜绲淖顑?yōu)人工智能策略的遞推公式,即在每個(gè)狀態(tài)下,比較人工智能干預(yù)和不干預(yù)的兩種情況下,人類的期望累積獎(jiǎng)勵(lì)的大小,選擇較大的一種作為最優(yōu)的干預(yù)策略。作者接著證明了鏈?zhǔn)澜绲淖顑?yōu)人工智能策略具有三窗口的形式,即存在三個(gè)臨界狀態(tài)????、????和????,使得在????之前,人工智能不干預(yù);在????和????之間,人工智能干預(yù)折扣因子;在????和????之間,人工智能干預(yù)獎(jiǎng)勵(lì);在????之后,人工智能不干預(yù)。作者還給出了三個(gè)臨界狀態(tài)的計(jì)算方法,即通過(guò)求解一些不等式和方程,得到????、????和????的值。
鏈?zhǔn)澜绲淖顑?yōu)人工智能策略的三窗口形式有三個(gè)意義和優(yōu)勢(shì)。
它可以解釋人類在摩擦性任務(wù)中的行為模式,即人類在任務(wù)的開(kāi)始和結(jié)束階段,往往不需要人工智能的干預(yù),而在任務(wù)的中間階段,往往需要人工智能的干預(yù)。這是因?yàn)樵谌蝿?wù)的開(kāi)始階段,人類的動(dòng)機(jī)和信心往往較高,而在任務(wù)的結(jié)束階段,人類的目標(biāo)和收益往往較明確,因此人類的行為與他們的長(zhǎng)期目標(biāo)較為一致。而在任務(wù)的中間階段,人類的動(dòng)機(jī)和信心往往較低,而且目標(biāo)和收益往往較模糊,因此人類的行為與他們的長(zhǎng)期目標(biāo)較為偏離。因此,人工智能的干預(yù)可以在適當(dāng)?shù)臅r(shí)機(jī),提高人類的折扣因子或獎(jiǎng)勵(lì),從而增強(qiáng)人類的行為一致性。
它可以指導(dǎo)人工智能的干預(yù)設(shè)計(jì),即人工智能可以根據(jù)人類的狀態(tài),選擇合適的干預(yù)方式,從而提高干預(yù)的效率和效果。例如,人工智能可以根據(jù)人類的進(jìn)度,選擇干預(yù)折扣因子或獎(jiǎng)勵(lì),從而影響人類的行為選擇。人工智能也可以根據(jù)人類的折扣因子或獎(jiǎng)勵(lì)的變化量,選擇合適的干預(yù)強(qiáng)度,從而平衡干預(yù)的成本和收益。人工智能還可以根據(jù)人類的反饋,調(diào)整干預(yù)的策略,從而適應(yīng)人類的個(gè)性和偏好。
它可以作為人類模型的等價(jià)性的判據(jù),即人工智能可以通過(guò)比較不同的人類模型是否導(dǎo)致相同的三窗口人工智能策略,來(lái)判斷它們是否等價(jià)。這樣,人工智能可以使用鏈?zhǔn)澜缱鳛槠渌祟怣DP的替代模型,而不會(huì)損失性能。這樣,人工智能可以減少人類模型的復(fù)雜度和不確定性,從而提高干預(yù)的可解釋性和可信度。

圖4:當(dāng)真正的人類模型是一個(gè)鏈?zhǔn)澜鐣r(shí),我們的方法會(huì)迅速個(gè)性化。情節(jié)是多集(x軸)的AI獎(jiǎng)勵(lì)(y軸)。左上角的線條更具個(gè)性。
最后,我們來(lái)看看作者是如何通過(guò)實(shí)驗(yàn)分析鏈?zhǔn)澜绲聂敯粜裕串?dāng)真實(shí)的人類模型與鏈?zhǔn)澜绮煌耆ヅ浠虿坏葍r(jià)時(shí),人工智能使用鏈?zhǔn)澜邕M(jìn)行干預(yù)的性能如何。作者設(shè)計(jì)了一系列的實(shí)驗(yàn),來(lái)模擬不同的人類模型和人工智能干預(yù)的場(chǎng)景,例如:
- 人類模型的參數(shù)存在噪聲,即人類的折扣因子、獎(jiǎng)勵(lì)函數(shù)、轉(zhuǎn)移函數(shù)等可能隨機(jī)變化,從而影響人類的行為選擇。
- 人類模型的結(jié)構(gòu)存在誤差,即人類的狀態(tài)空間、行動(dòng)空間、轉(zhuǎn)移函數(shù)等可能與鏈?zhǔn)澜绮灰恢拢瑥亩绊懭祟惖男袨槟J健?/li>
- 人類模型的復(fù)雜度存在差異,即人類的狀態(tài)空間、行動(dòng)空間、轉(zhuǎn)移函數(shù)等可能比鏈?zhǔn)澜绺鼜?fù)雜或更簡(jiǎn)單,從而影響人類的行為難度。
- 人類模型的行為存在偏差,即人類的行為選擇可能不是最優(yōu)的,而是受到一些認(rèn)知偏差、情緒影響、環(huán)境干擾等因素的影響。
- 人工智能干預(yù)的效果存在變化,即人工智能干預(yù)人類的折扣因子或獎(jiǎng)勵(lì)可能有正面的、負(fù)面的或沒(méi)有效果,從而影響人類的行為反應(yīng)。
 圖片
圖片
圖5:Chainworld按比例縮放為大型網(wǎng)格世界。左邊的示例網(wǎng)格世界。向右移動(dòng),柵格的寬度(X)和高度(Y)將增加。
作者使用了五種基準(zhǔn)方法來(lái)與鏈?zhǔn)澜邕M(jìn)行比較,分別是:
- Oracle,即人工智能知道真實(shí)的人類模型,并使用最優(yōu)的干預(yù)策略。
- Random,即人工智能隨機(jī)選擇干預(yù)或不干預(yù),以及干預(yù)的方式和強(qiáng)度。
- Model-free,即人工智能不使用任何人類模型,而是直接通過(guò)Q-learning來(lái)學(xué)習(xí)最優(yōu)的干預(yù)策略。
- Model-based,即人工智能使用觀察到的人類的狀態(tài)、行動(dòng)和獎(jiǎng)勵(lì)來(lái)估計(jì)人類的轉(zhuǎn)移函數(shù),然后使用確定性等價(jià)來(lái)求解最優(yōu)的干預(yù)策略。
- Always ??,即人工智能總是干預(yù)人類的折扣因子,不考慮人類的狀態(tài)和行動(dòng)。
- Always ????,即人工智能總是干預(yù)人類的獎(jiǎng)勵(lì)函數(shù),不考慮人類的狀態(tài)和行動(dòng)。
 圖片
圖片
圖6:穩(wěn)健性實(shí)驗(yàn)示例。Chainworld對(duì)所有級(jí)別的錯(cuò)誤指定都是穩(wěn)健的(圖6a),對(duì)低級(jí)別錯(cuò)誤指定都穩(wěn)健,并在高級(jí)別上進(jìn)行維護(hù)(圖6b),包括oracle在內(nèi)的所有方法都難以在圖6c中表現(xiàn)良好。附錄D.1和附錄E.3中分別列出了所有環(huán)境的詳細(xì)信息和圖表。
作者使用了人工智能在第六個(gè)回合中獲得的獎(jiǎng)勵(lì)作為評(píng)價(jià)指標(biāo),來(lái)衡量人工智能干預(yù)的性能。作者發(fā)現(xiàn)鏈?zhǔn)澜缭诖蠖鄶?shù)情況下,都可以達(dá)到或接近Oracle的性能,即使在一些極端的情況下,它也可以保持一定的水平。作者還發(fā)現(xiàn)鏈?zhǔn)澜缭诘退降哪P驼`差下,具有很強(qiáng)的魯棒性,而在高水平的模型誤差下,也可以維持一定的性能。作者還發(fā)現(xiàn),鏈?zhǔn)澜缭谝恍┡c鏈?zhǔn)澜绲葍r(jià)的人類模型下,可以完全復(fù)制Oracle的性能,證明了鏈?zhǔn)澜绲牡葍r(jià)性的有效性。作者還發(fā)現(xiàn),鏈?zhǔn)澜缭谝恍┚哂行袨橐饬x的人類模型下,可以表現(xiàn)出與人類的行為模式一致的干預(yù)策略,證明了鏈?zhǔn)澜绲慕忉屝缘挠行浴?/p>
總結(jié)一下,這篇論文提出了一種行為模型強(qiáng)化學(xué)習(xí)(BMRL)的框架,用于讓人工智能干預(yù)人類在摩擦性任務(wù)中的行為。作者提出了一種新的人類模型,稱為鏈?zhǔn)澜纾╟hainworld),用于描述人類在摩擦性任務(wù)中的行為。作者引入了一種基于BMRL的人類模型之間的等價(jià)性的概念,用于判斷不同的人類模型是否會(huì)導(dǎo)致相同的人工智能干預(yù)策略。作者通過(guò)實(shí)驗(yàn)分析了鏈?zhǔn)澜绲聂敯粜裕串?dāng)真實(shí)的人類模型與鏈?zhǔn)澜绮煌耆ヅ浠虿坏葍r(jià)時(shí),人工智能使用鏈?zhǔn)澜邕M(jìn)行干預(yù)的性能如何。作者的研究為人工智能干預(yù)人類行為提供了一種簡(jiǎn)單而有效的方法,也為人類行為的理解和解釋提供了一種有用的工具。
這篇論文的質(zhì)量和意義是顯而易見(jiàn)的,它在人工智能和行為科學(xué)的交叉領(lǐng)域做出了重要的貢獻(xiàn)。它不僅提出了一種新穎的人類模型和人工智能干預(yù)的框架,而且提供了一系列的理論證明和實(shí)驗(yàn)驗(yàn)證,展示了其有效性和魯棒性。它也為未來(lái)的研究提供了一些有趣的方向和挑戰(zhàn),例如進(jìn)行用戶研究、考慮人工智能干預(yù)的倫理問(wèn)題、測(cè)試鏈?zhǔn)澜绲聂敯粜浴⒎潘梢恍┖?jiǎn)化的假設(shè),以及探索更多樣的人工智能干預(yù)方式。這篇論文值得我們認(rèn)真閱讀和思考,也值得我們借鑒和應(yīng)用,以期在人工智能和人類的協(xié)作和互動(dòng)中,實(shí)現(xiàn)更好的效果和滿意度。(END)
參考資料:https://arxiv.org/abs/2401.14923