OccFusion:一種簡單有效的Occ多傳感器融合框架(性能SOTA)
本文經自動駕駛之心公眾號授權轉載,轉載請聯系出處。
對3D場景的全面理解在自動駕駛中至關重要,最近的3D語義占用預測模型已經成功地解決了描述具有不同形狀和類別的真實世界物體的挑戰。然而,現有的3D占用預測方法在很大程度上依賴于全景相機圖像,這使得它們容易受到照明和天氣條件變化的影響。通過集成激光雷達和環視雷達等附加傳感器的功能,本文的框架提高了占用預測的準確性和穩健性,從而在nuScenes基準上獲得了頂級性能。此外,在nuScene數據集上進行的廣泛實驗,包括具有挑戰性的夜間和雨天場景,證實了我們的傳感器融合策略在各種感知范圍內的卓越性能。
論文鏈接:https://arxiv.org/pdf/2403.01644.pdf
論文名稱:OccFusion: A Straightforward and Effective Multi-Sensor Fusion Framework for 3D Occupancy Prediction
本文的主要貢獻概述如下:
- 提出了一種多傳感器融合框架,用于集成相機、激光雷達和雷達信息,以執行3D語義占用預測任務。
- 在3D語義占用預測任務中,將本文的方法與其他最先進的(SOTA)算法進行了比較,以證明多傳感器融合的優勢。
- 進行了徹底的消融研究,以評估不同傳感器組合在具有挑戰性的照明和天氣條件下(如夜間和雨天)所實現的性能增益。
- 考慮到各種傳感器組合和具有挑戰性的場景,進行了一項全面的研究,以分析感知范圍因素對我們的框架在3D語義占用預測任務中的性能的影響!
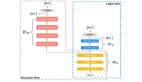
網絡結構一覽
OccFusion的總體架構如下所示。首先,將環繞視圖圖像輸入到2D主干中以提取多尺度特征。隨后,在每個尺度上進行視圖變換,以獲得每個級別的全局BEV特征和局部3D特征volume 。激光雷達和環視雷達生成的3D點云也被輸入到3D主干中,以生成多尺度局部3D特征量和全局BEV特征。每個級別的動態融合3D/2D模塊融合了相機和激光雷達/雷達的功能。在此之后,將每個級別的合并的全局BEV特征和局部3D特征volume 饋送到全局-局部注意力融合中,以生成每個尺度的最終3D volume 。最后,對每個級別的3D volume 進行上采樣,并在采用多尺度監督機制的情況下進行skip連接。

實驗對比分析
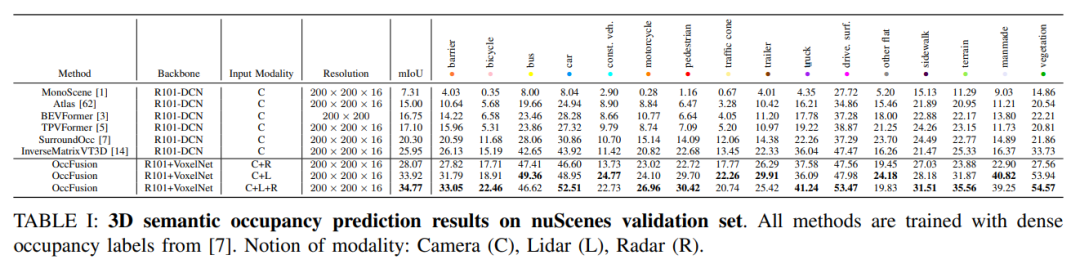
nuScenes驗證集上的3D語義占用預測結果。所有方法都使用密集占用標簽進行訓練。模態概念:相機(C)、激光雷達(L)、雷達(R)。
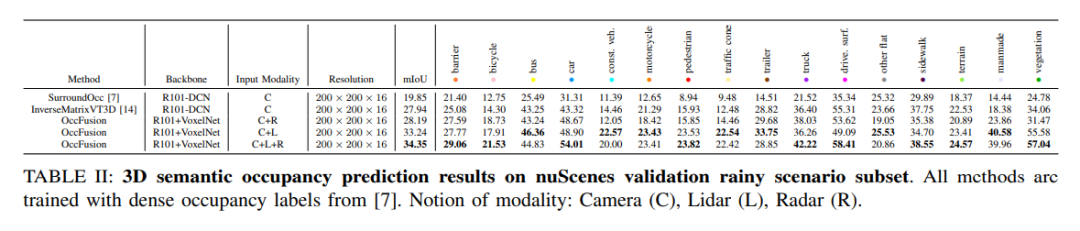
nuScenes驗證雨天場景子集上的3D語義占用預測結果。所有方法都使用密集占用標簽進行訓練。模態概念:相機(C)、激光雷達(L)、雷達(R)。
nuScenes驗證夜間場景子集的3D語義占用預測結果。所有方法都使用密集占用標簽進行訓練。模態概念:相機(C)、激光雷達(L)、雷達(R)。

性能變化趨勢。(a) 整個nuScenes驗證集的性能變化趨勢,(b)nuScenes驗證夜間場景子集,以及(c)nuScene驗證雨天場景子集的性能變化趨勢。

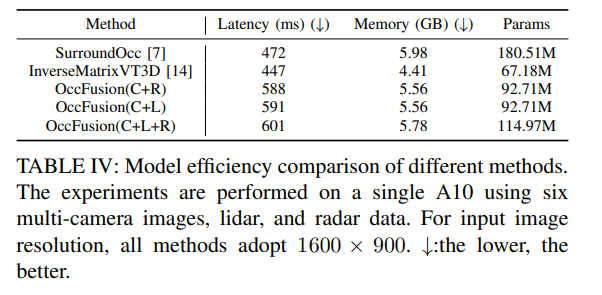
表四:不同方法的模型效率比較。實驗是在一臺A10上使用六幅多攝像頭圖像、激光雷達和雷達數據進行的。對于輸入圖像分辨率,所有方法均采用1600×900。↓:越低越好。
更多消融實驗: