譯者 | 布加迪
審校 | 重樓
本文揭示了聚類分析在分割、分析和洞察相似數(shù)據(jù)組方面具有的潛力。
機(jī)器學(xué)習(xí)不僅僅涉及做預(yù)測(cè),還涉及其他無(wú)監(jiān)督過(guò)程,其中聚類尤為突出。本文介紹了聚類和聚類分析,著重表明了聚類分析在分割、分析和洞察相似數(shù)據(jù)組方面具有的潛力。
什么是聚類?
簡(jiǎn)單來(lái)說(shuō),聚類就是將相似的數(shù)據(jù)項(xiàng)分組在一起,這好比在雜貨店里將相似的水果蔬菜擺放在一起。
不妨進(jìn)一步闡述這個(gè)概念:聚類是一種無(wú)監(jiān)督學(xué)習(xí)任務(wù),涉及一系列廣泛的機(jī)器學(xué)習(xí)方法,假設(shè)數(shù)據(jù)未標(biāo)記或未先驗(yàn)分類,旨在發(fā)現(xiàn)其底層的模式或洞察力。具體來(lái)說(shuō),聚類的目的是發(fā)現(xiàn)有相似特征或?qū)傩缘臄?shù)據(jù)觀測(cè)組。
以下是聚類在眾多機(jī)器學(xué)習(xí)技術(shù)中所處的位置:
據(jù)-AI.x社區(qū)")
為了更好地理解聚類概念,不妨想想在超市中尋找有相似購(gòu)物行為的客戶群,或者將電子商務(wù)門戶網(wǎng)站中的大量產(chǎn)品分門別類,這些是涉及聚類方法的真實(shí)場(chǎng)景的常見(jiàn)例子。
常見(jiàn)的聚類技術(shù)
數(shù)據(jù)聚類的方法有好多種,最流行的三種方法如下:
- 迭代聚類:這些算法將數(shù)據(jù)點(diǎn)迭代分配(有時(shí)重新分配)給各自的聚類,直到它們收斂于一個(gè)“足夠好”的解決方案。最流行的迭代聚類算法是k-means,它通過(guò)將數(shù)據(jù)點(diǎn)分配給由代表性點(diǎn)(聚類中心)定義的聚類來(lái)進(jìn)行迭代,并逐漸更新聚類中心,直到實(shí)現(xiàn)收斂。
- 分層聚類:顧名思義,這種算法使用自上而下的方法(分割一組數(shù)據(jù)點(diǎn),直到擁有所需數(shù)量的子組)或自下而上的方法(將相似的數(shù)據(jù)點(diǎn)像氣泡一樣逐漸合并到越來(lái)越大的組中),構(gòu)建基于分層樹(shù)的結(jié)構(gòu)。AHC(聚合式分層聚類)是自下而上的分層聚類算法的常見(jiàn)例子。
- 基于密度的聚類:這些方法識(shí)別數(shù)據(jù)點(diǎn)的高密度區(qū)域以形成聚類。DBSCAN(基于密度的噪聲應(yīng)用空間聚類)是屬于這一類的一種流行算法。
聚類和聚類分析一樣嗎?
- 眼下最緊迫的問(wèn)題可能是:聚類和聚類分析指同一個(gè)概念嗎?
- 毫無(wú)疑問(wèn),兩者非常密切相關(guān),但不是一回事,兩者存在細(xì)微的差異。
- 聚類是對(duì)相似數(shù)據(jù)進(jìn)行分組的過(guò)程,以便同一組或聚類中的任何兩個(gè)對(duì)象比不同組中的任何兩個(gè)對(duì)象更相似。
- 聚類分析是一個(gè)更廣泛的術(shù)語(yǔ),不僅包括對(duì)數(shù)據(jù)進(jìn)行分組(聚類)的過(guò)程,還包括在特定領(lǐng)域上下文對(duì)獲得的聚類進(jìn)行分析、評(píng)價(jià)和解釋。
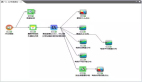
下圖表明了這兩個(gè)經(jīng)常混淆的術(shù)語(yǔ)之間的區(qū)別和關(guān)系。
據(jù)-AI.x社區(qū)")
實(shí)際例子
不妨現(xiàn)在開(kāi)始關(guān)注聚類分析,為此舉一個(gè)實(shí)際的例子:
- 分割一組數(shù)據(jù)。
- 分析得到的數(shù)據(jù)片段。
注意:本例中附帶的代碼,假設(shè)你熟悉Python語(yǔ)言的基礎(chǔ)知識(shí)和一些庫(kù),比如Sklearn(用于訓(xùn)練聚類模型)、Pandas(用于數(shù)據(jù)整理)和Matplotlib(用于數(shù)據(jù)可視化)。
我們將使用帕爾默群島企鵝(https://www.kaggle.com/datasets/parulpandey/palmer-archipelago-antarctica-penguin-data)數(shù)據(jù)集闡述聚類分析,該數(shù)據(jù)集含有對(duì)阿德利企鵝、巴布亞企鵝和帽帶企鵝三種不同物種的數(shù)據(jù)觀測(cè)。這個(gè)數(shù)據(jù)集在訓(xùn)練分類模型方面非常流行,但在尋找數(shù)據(jù)聚類方面也頗有用處。加載數(shù)據(jù)集文件后,我們要做的就是假設(shè)“species”類屬性是未知的。
import pandas as pd
penguins = pd.read_csv('penguins_size.csv').dropna()
X = penguins.drop('species', axis=1)我們還將從數(shù)據(jù)集中刪除描述企鵝性別和觀測(cè)到該物種所在島嶼的兩個(gè)類別特征,留下其余的數(shù)字特征。我們還將已知的標(biāo)簽(species)存儲(chǔ)在一個(gè)單獨(dú)的變量y中:它們便于稍后將獲得的聚類與數(shù)據(jù)集中實(shí)際的企鵝分類進(jìn)行比較。
X = X.drop(['island', 'sex'], axis=1)
y = penguins.species.astype("category").cat.codes使用下面幾行代碼,我們就可以運(yùn)用Sklearn庫(kù)中可用的k -means聚類算法,在我們的數(shù)據(jù)中找到k個(gè)聚類。我們只需指定我們想要找到的聚類的數(shù)量,在本文中,我們將數(shù)據(jù)分成k=3聚類:
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters = 3, n_init=100)
X["cluster"] = kmeans.fit_predict(X)上面最后一行代碼存儲(chǔ)了聚類結(jié)果,即分配給每個(gè)數(shù)據(jù)實(shí)例的聚類的id,存儲(chǔ)在名為“cluster”的新屬性中。
接下來(lái)可以生成聚類的一些可視化圖來(lái)分析和解釋它們了!下面的代碼片段有點(diǎn)長(zhǎng),但可以歸結(jié)為生成兩個(gè)數(shù)據(jù)可視化圖:第一個(gè)顯示了兩個(gè)數(shù)據(jù)特征(喙長(zhǎng)culmen length和前肢長(zhǎng)flipper length)周圍的散點(diǎn)圖以及每個(gè)觀測(cè)值所屬的聚類,第二個(gè)可視化圖顯示了每個(gè)數(shù)據(jù)點(diǎn)所屬的實(shí)際企鵝物種。
plt.figure (figsize=(12, 4.5))
# Visualize the clusters obtained for two of the data attributes: culmen
length and flipper length
plt.subplot(121)
plt.plot(X[X["cluster"]==0]["culmen_length_mm"],
X[X["cluster"]==0]["flipper_length_mm"], "mo", label="First cluster")
plt.plot(X[X["cluster"]==1]["culmen_length_mm"],
X[X["cluster"]==1]["flipper_length_mm"], "ro", label="Second cluster")
plt.plot(X[X["cluster"]==2]["culmen_length_mm"],
X[X["cluster"]==2]["flipper_length_mm"], "go", label="Third cluster")
plt.plot(kmeans.cluster_centers_[:,0], kmeans.cluster_centers_[:,2], "kD",
label="Cluster centroid")
plt.xlabel("Culmen length (mm)", fontsize=14)
plt.ylabel("Flipper length (mm)", fontsize=14)
plt.legend(fontsize=10)
# Compare against the actual ground-truth class labels (real penguin
species)
plt.subplot(122)
plt.plot(X[y==0]["culmen_length_mm"], X[y==0]["flipper_length_mm"], "mo",
label="Adelie")
plt.plot(X[y==1]["culmen_length_mm"], X[y==1]["flipper_length_mm"], "ro",
label="Chinstrap")
plt.plot(X[y==2]["culmen_length_mm"], X[y==2]["flipper_length_mm"], "go",
label="Gentoo")
plt.xlabel("Culmen length (mm)", fontsize=14)
plt.ylabel("Flipper length (mm)", fontsize=14)
plt.legend(fontsize=12)
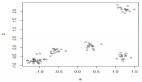
plt.show以下是可視化圖:
據(jù)-AI.x社區(qū)")
通過(guò)觀測(cè)這些聚類,我們可以得出第一個(gè)結(jié)論:
- 在分配給不同聚類的數(shù)據(jù)點(diǎn)(企鵝)之間有一種微妙的,但不是很清楚的分離,發(fā)現(xiàn)的子組之間有一些輕微的重疊。這不一定會(huì)讓我們得出聚類結(jié)果是好還是壞的結(jié)論:我們已經(jīng)對(duì)數(shù)據(jù)集的幾個(gè)屬性運(yùn)用了k-means算法,但這個(gè)可視化圖顯示了聚類上的數(shù)據(jù)點(diǎn)如何僅根據(jù)兩個(gè)屬性“culmen length”和“flipper length”來(lái)定位。可能存在其他屬性對(duì),根據(jù)這些屬性對(duì),聚類在可視化圖上被表示為更清晰地彼此分開(kāi)。
這就引出了一個(gè)問(wèn)題:如果我們嘗試根據(jù)用于訓(xùn)練模型的任何其他兩個(gè)變量可視化我們的聚類會(huì)怎么樣?
不妨可視化企鵝的體重(克)和喙長(zhǎng)(毫米)。
plt.plot(X[X["cluster"]==0]["body_mass_g"],
X[X["cluster"]==0]["culmen_length_mm"], "mo", label="First cluster")
plt.plot(X[X["cluster"]==1]["body_mass_g"],
X[X["cluster"]==1]["culmen_length_mm"], "ro", label="Second cluster")
plt.plot(X[X["cluster"]==2]["body_mass_g"],
X[X["cluster"]==2]["culmen_length_mm"], "go", label="Third cluster")
plt.plot(kmeans.cluster_centers_[:,3], kmeans.cluster_centers_[:,0], "kD",
label="Cluster centroid")
plt.xlabel("Body mass (g)", fontsize=14)
plt.ylabel("Culmen length (mm)", fontsize=14)
plt.legend(fontsize=10)
plt.show據(jù)-AI.x社區(qū)")
這個(gè)似乎非常清楚!現(xiàn)在我們把數(shù)據(jù)分成了易于辨別的三組。進(jìn)一步分析我們的可視化圖,我們可以從中獲得更多的發(fā)現(xiàn):
- 發(fā)現(xiàn)的聚類與“體重”和“喙長(zhǎng)”屬性的值之間存在密切的關(guān)系。從圖的左下角到右上角,第一組企鵝的特點(diǎn)是體型小,因?yàn)樗鼈兊摹绑w重”值低,但喙長(zhǎng)變化很大。第二組企鵝體型中等,喙長(zhǎng)中偏高。最后,第三組企鵝的特點(diǎn)是體型更大,喙更長(zhǎng)。
- 還可以觀測(cè)到有少數(shù)異常值,即非典型值偏離大多數(shù)對(duì)象的數(shù)據(jù)觀測(cè)。這一點(diǎn)在可視化區(qū)域最上方的點(diǎn)上體現(xiàn)得尤為明顯,這表明在所有三組中,一些觀測(cè)到的企鵝的喙都過(guò)長(zhǎng)。
結(jié)語(yǔ)
本文闡述了聚類分析的概念和實(shí)際應(yīng)用,即在數(shù)據(jù)中找到有相似特征或?qū)傩缘脑刈咏M,并分析這些子組從中獲取有價(jià)值或可操作的洞察力。從市場(chǎng)營(yíng)銷、電子商務(wù)到生態(tài)項(xiàng)目,聚類分析被廣泛應(yīng)用于眾多實(shí)際領(lǐng)域。
原文標(biāo)題:Using Cluster Analysis to Segment Your Data,作者:Ivan Palomares Carrascosa