干貨 :基于用戶畫像的聚類分析
聚類(Clustering),顧名思義就是“物以類聚,人以群分”,其主要思想是按照特定標準把數據集聚合成不同的簇,使同一簇內的數據對象的相似性盡可能大,同時,使不在同一簇內的數據對象的差異性盡可能大。通俗地說,就是把相似的對象分到同一組。
聚類算法通常不使用訓練數據,只要計算對象間的相似度即可應用算法。這在機器學習領域中被稱為無監督學習。
某大型保險企業擁有海量投保客戶數據,由于大數據技術與相關人才的緊缺,企業尚未建立統一的數據倉庫與運營平臺,積累多年的數據無法發揮應有的價值。企業期望搭建用戶畫像,對客戶進行群體分析與個性化運營,以此激活老客戶,挖掘百億續費市場。眾安科技數據團隊對該企業數據進行建模,輸出用戶畫像并搭建智能營銷平臺。再基于用戶畫像數據進行客戶分群研究,制訂個性化運營策略。
本文重點介紹聚類算法的實踐。
Step 1 數據預處理
任何大數據項目中,前期數據準備都是一項繁瑣無趣卻又十分重要的工作。
首先,對數據進行標準化處理,處理異常值,補全缺失值,為了順利應用聚類算法,還需要使用戶畫像中的所有標簽以數值形式體現。
其次要對數值指標進行量綱縮放,使各指標具有相同的數量級,否則會使聚類結果產生偏差。
接下來要提取特征,即把最初的特征集降維,從中選擇有效特征放進聚類算法里跑。眾安科技為該保險公司定制的用戶畫像中,存在超過200個標簽,為不同的運營場景提供了豐富的多維度數據支持。但這么多標簽存在相關特征,假如存在兩個高度相關的特征,相當于將同一個特征的權重放大兩倍,會影響聚類結果。
我們可以通過關聯規則分析(Association Rules)發現并排除高度相關的特征,也可以通過主成分分析(Principal Components Analysis,簡稱PCA)進行降維。這里不詳細展開,有興趣的讀者可以自行了解。
Step 2 確定聚類個數
層次聚類是十分常用的聚類算法,是根據每兩個對象之間的距離,將距離最近的對象兩兩合并,合并后產生的新對象再進行兩兩合并,以此類推,直到所有對象合為一類。
Ward方法在實際應用中分類效果較好,應用較廣。它主要基于方差分析思想,理想情況下,同類對象之間的離差平方和盡可能小,不同類對象之間的離差平方和應該盡可能大。該方法要求樣品間的距離必須是歐氏距離。
值得注意的是,在R中,調用ward方法的名稱已經從“ward”更新為“ward.D”。
- library(proxy)
- Dist <- dist(data,method='euclidean') #歐式距離
- clusteModel <- hclust(Dist, method='ward.D')
- plot(clusteModel)
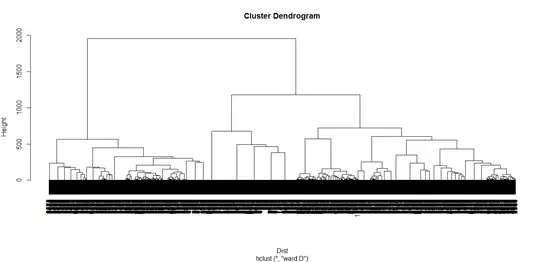
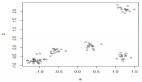
根據R繪制的層次聚類圖像,我們對該企業的客戶相似性有一個直觀了解,然而單憑肉眼,仍然難以判斷具體的聚類個數。這時我們通過輪廓系數法進一步確定聚類個數。
輪廓系數旨在對某個對象與同類對象的相似度和與不同類對象的相似度做對比。輪廓系數取值在-1到1之間,輪廓系數越大時,表示對應簇的數量下,聚類效果越好。
- library(fpc)
- K <- 3:8
- round <- 30 # 避免局部***
- rst <- sapply(K,function(i){
- print(paste("K=",i))
- mean(sapply(1:round,function(r){
- print(paste("Round",r))
- result<- kmeans(data, i)
- stats<- cluster.stats(dist(data), result$cluster)
- stats$avg.silwidth
- }))
- })
- plot(K,rst,type='l',main='輪廓系數與K的關系',ylab='輪廓系數')
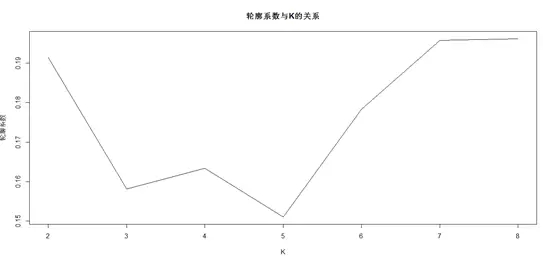
在輪廓系數的實際應用中,不能單純取輪廓系數***的K值,還需要考慮聚類結果的分布情況(避免出現超大群體),以及從商業角度是否易于理解與執行,據此綜合分析,探索合理的K值。
綜上,根據分析研究,確定K的取值為7。
Step 3 聚類
K-means是基于距離的聚類算法,十分經典,簡單而高效。其主要思想是選擇K個點作為初始聚類中心, 將每個對象分配到最近的中心形成K個簇,重新計算每個簇的中心,重復以上迭代步驟,直到簇不再變化或達到指定迭代次數為止。K-means算法缺省使用歐氏距離來計算。
- library(proxy)
- library(cluster)
- clusteModel <- kmeans(data, centers = 7, nstart =10)
- clusteModel$size
- result_df <- data.frame(data,clusteModel$cluster)
- write.csv(result_df, file ="clusteModel.csv", row.names = T, quote = T)
Step 4 聚類結果分析
對聚類結果(clusteModel.csv)進行數據分析,總結群體特征:
- cluster=1:當前價值低,未來價值高。(5.6%)
- cluster=2:當前價值中,未來價值高。(5.4%)
- cluster=3:當前價值高,未來價值高。(18%)
- cluster=4:當前價值高,未來價值中低。(13.6%)
- cluster=5:高價值,穩定群。(14%)
- cluster=6:當前價值低,未來價值未知(可能信息不全導致)。(2.1%)
- cluster=7:某一特征的客戶群體(該特征為業務重點發展方向)。(41.3%)
根據分析師與業務團隊的討論結果,將cluster=1與cluster=6進行合并,最終得到6個客戶群體,并針對客戶群體制訂運營策略。
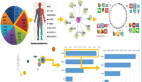
客戶分群與運營策略
(業務敏感信息打碼)