如何使用Python工具分析風險數據
小安前言
隨著網絡安全信息數據大規模的增長,應用數據分析技術進行網絡安全分析成為業界研究熱點,小安在這次小講堂中帶大家用Python工具對風險數據作簡單分析,主要是分析蜜罐日志數據,來看看一般大家都使用代理ip干了一些啥事。
大家可能會問小安啥是蜜罐,網上一些黑客或技術人員經常做一些"事情"的時候,需要隱藏自己身份,這樣他們會使用代理IP來辦事。而蜜罐(Honeypot)是一種新型的主動防御的安全技術,它是一個專門為了被攻擊或入侵而設置的欺騙系統——既可以用于保護產品系統,又可用于搜集黑客信息,是一種配置靈活、形式多樣的網絡安全技術。
說得通俗一點就是提供大量代理IP,引誘一些不法分子來使用代理這些代理ip,從而搜集他們的信息。
數據分析工具介紹
工欲善其事,必先利其器,在此小安向大家介紹一些Python數據分析的“神兵利器“。
Python中著名的數據分析庫Panda Pandas庫是基于NumPy 的一種工具,該工具是為了解決數據分析任務而創建,也是圍繞著 Series 和 DataFrame 兩個核心數據結構展開的,其中Series 和 DataFrame 分別對應于一維的序列和二維的表結構。 Pandas提供了大量能使我們快速便捷地處理數據的函數和方法。這個庫優點很多,簡單易用,接口抽象得非常好,而且文檔支持實在感人。你很快就會發現,它是使Python成為強大而高效的數據分析環境的重要因素之一。
數據可視化采用Python上最常用的Matplotlib庫 Matplotlib是一個Python的圖形框架,也是Python最著名的繪圖庫,它提供了一整套和Matlab相似的命令API,十分適合交互式地進行制圖。
我們有了這些“神兵利器“在手,下面小安將帶大家用Python這些工具對蜜罐代理數據作一個走馬觀花式的分析介紹。
1、引入工具–加載數據分析包
啟動IPython notebook,加載運行環境:
%matplotlib inline
import pandas as pd
from datetime import timedelta, datetime
import matplotlib.pyplot as plt
import numpy as np
2、數據準備
俗話說: 巧婦難為無米之炊。小安分析的數據主要是用戶使用代理IP訪問日志記錄信息,要分析的原始數據以CSV的形式存儲。這里首先要介紹到pandas.read_csv這個常用的方法,它將數據讀入DataFrame
analysis_data = pd.read_csv('./honeypot_data.csv')
對的, 一行代碼就可以將全部數據讀到一個二維的表結構DataFrame變量,感覺很簡單有木有啊!!!當然了用Pandas提供的IO工具你也可以將大文件分塊讀取,再此小安測試了一下性能,完整加載約21530000萬條數據也大概只需要90秒左右,性能還是相當不錯。
3、數據管窺
一般來講,分析數據之前我們首先要對數據有一個大體上的了解,比如數據總量有多少,數據有哪些變量,數據變量的分布情況,數據重復情況,數據缺失情況,數據中異常值初步觀測等等。下面小安帶小伙伴們一起來管窺管窺這些數據。
使用shape方法查看數據行數及列數
analysis_data.shape
Out: (21524530, 22) #這是有22個維度,共計21524530條數據記的DataFrame
使用head()方法默認查看前5行數據,另外還有tail()方法是默認查看后5行,當然可以輸入參數來查看自定義行數
analysis_data.head(10)

這里可以了解到我們數據記錄有用戶使用代理IP日期,代理header信息,代理訪問域名,代理方法,源ip以及蜜罐節點信息等等。在此小安一定一定要告訴你,小安每次做數據分析時必定使用的方法–describe方法。pandas的describe()函數能對數據進行快速統計匯總:
對于數值類型數據,它會計算出每個變量: 總個數,平均值,最大值,最小值,標準差,50%分位數等等;
非數值類型數據,該方法會給出變量的: 非空值數量、unique數量(等同于數據庫中distinct方法)、最大頻數變量和最大頻數。
由head()方法我們可以發現數據中包含了數值變量、非數值變量,我們首先可以利用dtypes方法查看DataFrame中各列的數據類型,用select_dtypes方法將數據按數據類型進行分類。然后,利用describe方法返回的統計值對數據有個初步的了解:
df.select_dtypes(include=['O']).describe()

df.select_dtypes(include=['float64']).describe()
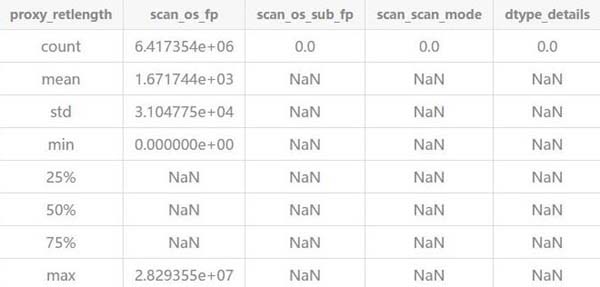
簡單的觀察上面變量每一維度統計結果,我們可以了解到大家獲取代理數據的長度平均1670個字節左右。同時,也能發現字段scanossubfp,scanscan_mode等存在空值等等信息。這樣我們能對數據整體上有了一個大概了解。
4、數據清洗
由于源數據通常包含一些空值甚至空列,會影響數據分析的時間和效率,在預覽了數據摘要后,需要對這些無效數據進行處理。
一般來說,移除一些空值數據可以使用dropna方法, 當你使用該方法后,檢查時發現 dropna() 之后幾乎移除了所有行的數據,一查Pandas用戶手冊,原來不加參數的情況下, dropna() 會移除所有包含空值的行。
如果你只想移除全部為空值的列,需要加上 axis 和 how 兩個參數:
analysis_data.dropna(axis=1, how='all')
另外,也可以通過dropna的參數subset移除指定列為空的數據,和設置thresh值取移除每非None數據個數小于thresh的行。
analysis_data.dropna(subset=['proxy_host', 'srcip'])
#移除proxy_host字段或srcip字段沒有值的行
analysis_data.dropna(thresh=10)
#移除所有行字段中有值屬性小于10的行
5、統計分析
再對數據中的一些信息有了初步了解過后,原始數據有22個變量。從分析目的出發,我將從原始數據中挑選出局部變量進行分析。這里就要給大家介紹pandas的數據切片方法loc。
loc([startrowindex:endrowindex,[‘timestampe’, ‘proxy_host’, ‘srcip’]])是pandas重要的切片方法,逗號前面是對行進行切片;逗號后的為列切片,也就是挑選要分析的變量。
如下,我這里選出日期,host和源IP字段——
analysis_data = analysis_data.loc([:, [‘timestampe’,'proxy_host','srcip']])
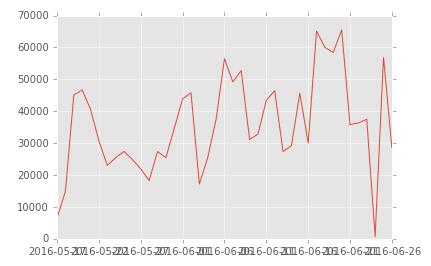
首先讓我們來看看蜜罐代理每日使用數據量,我們將數據按日統計,了解每日數據量PV,并將結果畫出趨勢圖。
daily_proxy_data = analysis_data[analysis_data.module=='proxy']
daily_proxy_visited_count = daily_proxy_data.timestamp.value_counts().sort_index()
daily_proxy_visited_count.plot()
對數據列的丟棄,除無效值和需求規定之外,一些表自身的冗余列也需要在這個環節清理,比如說DataFrame中的index號、類型描述等,通過對這些數據的丟棄,從而生成新的數據,能使數據容量得到有效的縮減,進而提高計算效率。
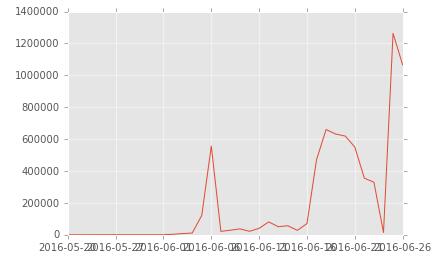
由上圖分析可知蜜罐代理使用量在6月5號,19-22號和25號這幾天呈爆炸式增長。那么這幾天數據有情況,不正常,具體是神馬情況,不急,后面小安帶大家一起來慢慢揪出來到底是那些人(源ip) 干了什么“壞事”。
進一步分析, 數據有異常后,再讓我們來看看每天去重IP數據后量及其增長量。可以按天groupby后通過nunique()方法直接算出來每日去重IP數據量。
daily_proxy_data = analysis_data[analysis_data.module=='proxy']
daily_proxy_visited_count = daily_proxy_data.groupby(['proxy_host']).srcip.nunique()
daily_proxy_visited_count.plot()
究竟大部分人(源ip)在干神馬?干神馬?干神馬?讓我們來看看被訪問次數最多host的哪些,即同一個host關聯的IP個數,為了方便我們只查看前10名熱門host。
先選出host和ip字段,能過groupby方法來group 每個域名(host),再對每個域名的ip訪問里unique統計。
host_associate_ip = proxy_data.loc[:, ['proxy_host', 'srcip']]
grouped_host_ip = host_associate_ip.groupby(['proxy_host']).srcip.nunique()
print(grouped_host_ip.sort_values(ascending=False).head(10))
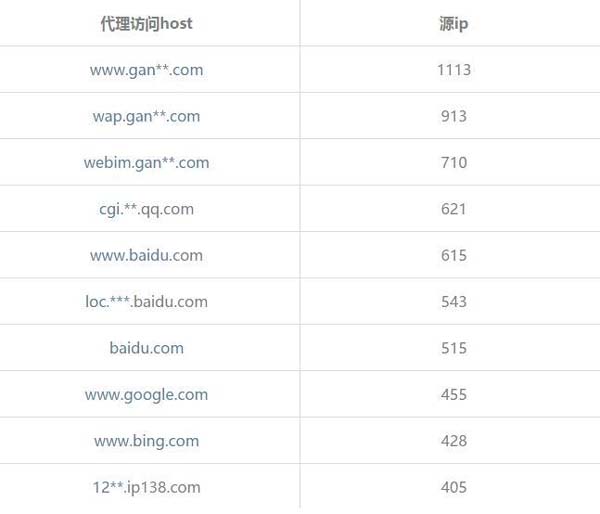
再細細去看大家到底做了啥——查看日志數據發現原來在收集像二手車價格,工人招聘等等信息。從熱門host來看,總得來說大家使用代理主要還是獲取百度,qq,Google,Bing這類婦孺皆知網站的信息。
下面再讓我們來看看是誰用代理IP“干事”最多,也就是看看誰的IP訪問不同host的個數最多。
host_associate_ip = proxy_data.loc[:, ['proxy_host', 'srcip']]
grouped_host_ip = host_associate_ip.groupby(['srcip'_host']).proxy_host.nunique()
print(grouped_host_ip.sort_values(ascending=False).head(10))
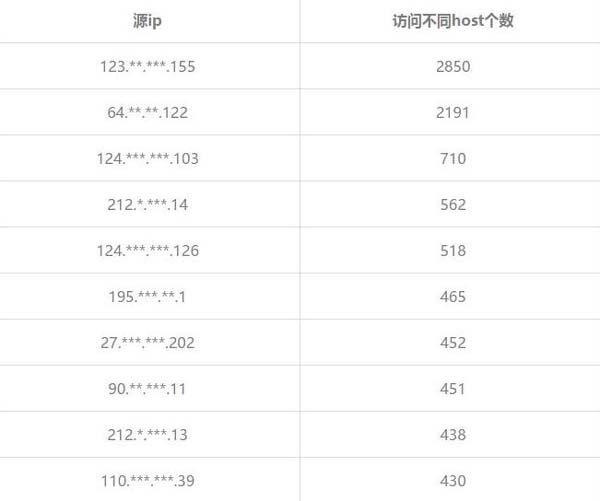
哦,發現目標IP為123..*.155的小伙子有大量訪問記錄, 進而查看日志,原來他在大量收集酒店信息。 好了,這樣我們就大概能知道誰在干什么了,再讓我們來看看他們使用proxy持續時長,誰在長時間里使用proxy。 代碼如下——
這里不給大家細說代碼了,只給出如下偽代碼。
date_ip = analysis_data.loc[:,['timestamp','srcip']]
grouped_date_ip = date_ip.groupby(['timestamp', 'srcip'])
#計算每個源ip(srcip)的訪問日期
all_srcip_duration_times = ...
#算出最長連續日期天數
duration_date_cnt = count_date(all_srcip_duration_times)
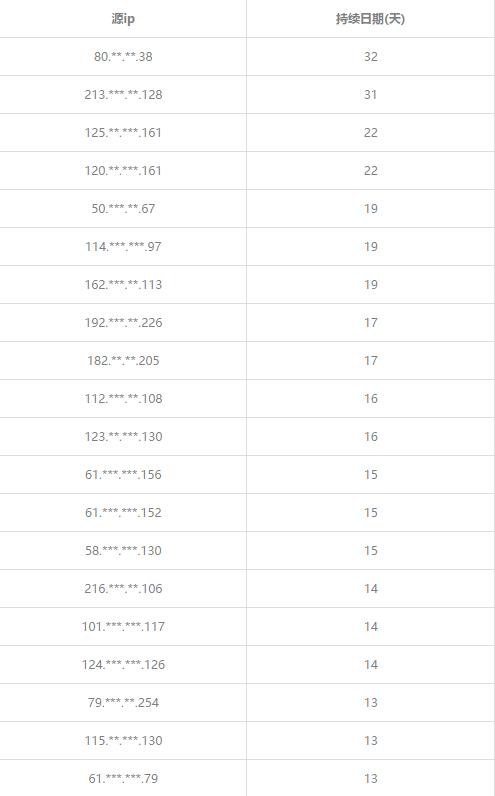
好了,到此我也就初略的知道那些人做什么,誰用代理時長最長等等問題額。取出ip = 80...38的用戶使用代理ip訪問數據日志,發現原來這個小伙子在長時間獲取搜狐images。
蜜罐在全國各地部署多個節點,再讓我們來看看每個源ip掃描蜜罐節點總個數,了解IP掃描節點覆蓋率。結果見如下:
# 每個IP掃描的IP掃描節點總個數
node = df[df.module=='scan']
node = node.loc[:,['srcip','origin_details']]
grouped_node_count = node.groupby(['srcip']).count()
print grouped_node_count.sort_values(['origin_details'], ascending=False).head(10)
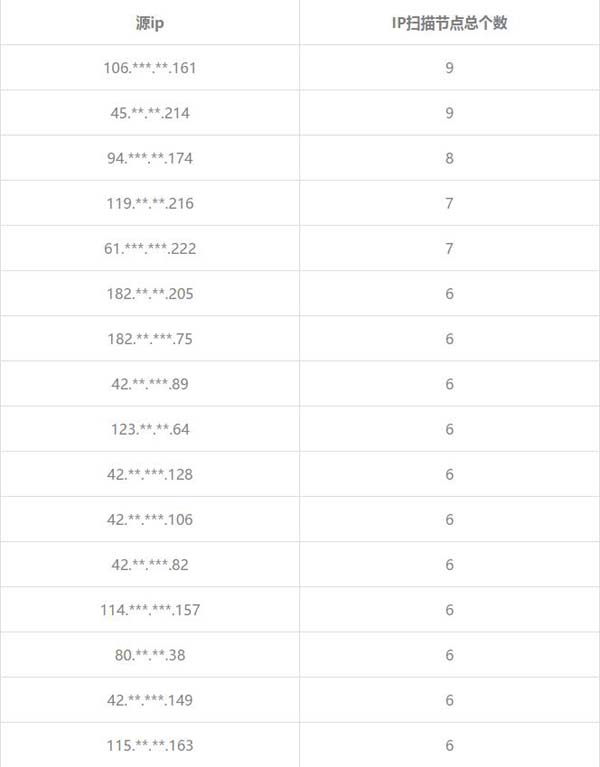
由上述兩表初步可知,一些結論:如源ip為182...205的用戶長時間對蜜罐節點進行掃描,mark危險用戶等等。
結語
小安在這里給大家簡單介紹的用python工具,主要是pandas庫來分析數據,當然這個庫的功能非常強大,小安也只是帶大家一起來走馬觀花的領略一番,更多的還是要大家自己去使用和探索。