













源代碼is all you need!7B代碼小模型同尺寸無敵,性能媲美ChatGPT和谷歌Gemini
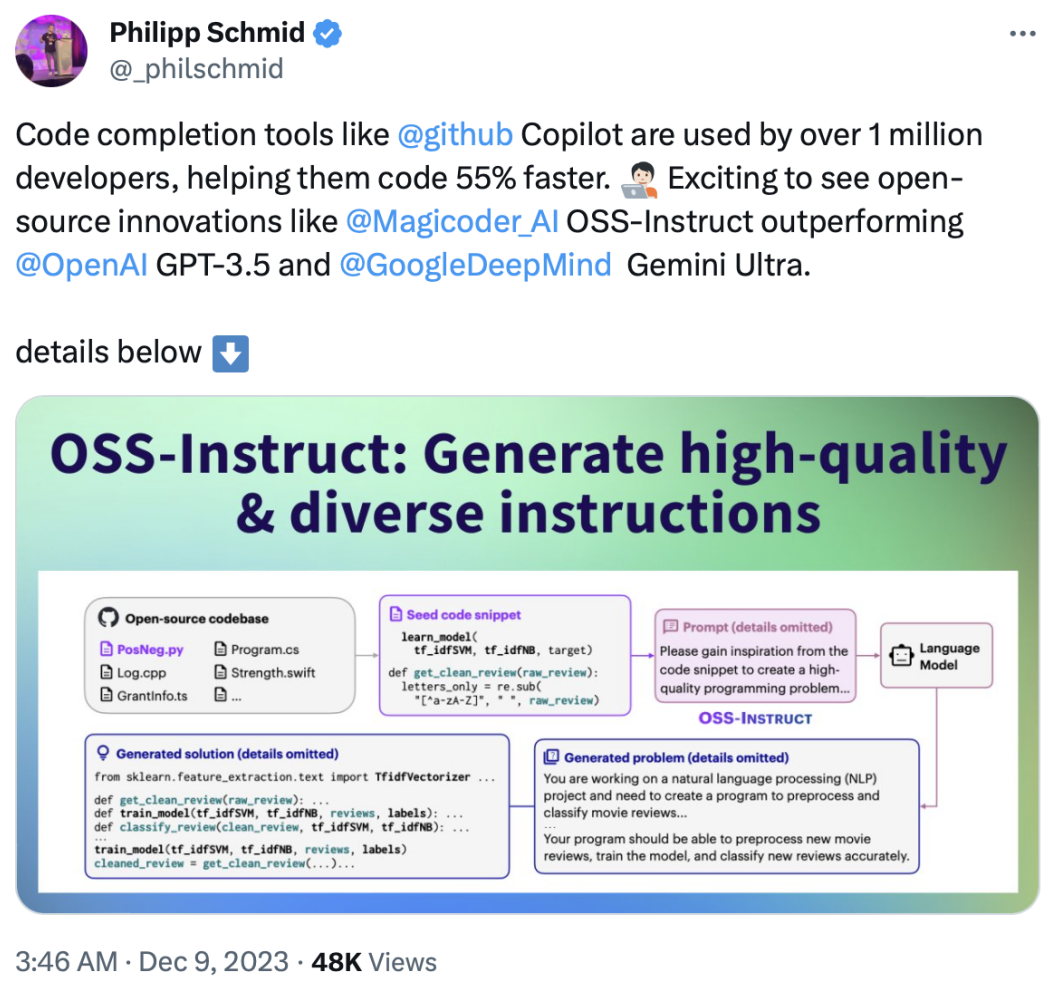
Hugging Face 技術負責人 Philipp Schmid 表示:“代碼自動補全工具,如 GitHub Copilot,已被超過一百萬開發者使用,幫助他們的編碼速度提高了 55%。看到像 Magicoder 和 OSS-INSTRUCT 這樣的開源創新超越了 OpenAI 的 GPT-3.5 和 Google DeepMind 的 Gemini Ultra,真是令人振奮。這些進步不僅展示了人工智能技術的快速發展,也突顯了開源社區在推動這一領域創新中的重要角色。”
代碼生成(也稱為程序合成)一直是計算機科學領域的挑戰性課題。在過去幾十年,大量的研究致力于符號方法的研究。最近,基于代碼訓練的大型語言模型(LLM)在生成準確滿足用戶意圖的代碼方面取得了顯著突破,并已被廣泛應用于幫助現實世界的軟件開發。
最初,閉源模型如 GPT-3.5 Turbo (即 ChatGPT) 和 GPT4 在各種代碼生成基準和排行榜中占據主導地位。為了進一步推動開源 LLM 在代碼生成領域的發展,SELF-INSTRUCT 被提出來引導 LLM 的指令遵循能力。在代碼領域,從業者通常使用更強大的教師模型(如 ChatGPT 和 GPT-4)設計合成編碼指令,然后用生成的數據微調更弱的學生模型(如 CODELLAMA)以從教師那里提煉知識。
我們以 Code Alpaca 為例,它包含了通過在 ChatGPT 上應用 SELF-INSTRUCT 生成的 20,000 個代碼指令,使用了 21 個種子任務。為了進一步增強 LLM 的編碼能力,Luo et al. 2023b 提出了 Code Evol-Instruct,該方法采用各種啟發式方法來增加種子代碼指令 (如 Code Alpaca) 的復雜性,在開源模型中取得了 SOTA 結果。
雖然這些數據生成方法能有效提高 LLM 的指令遵循能力,但它們在內部依賴于一系列狹義的預定義任務或啟發式方法。比如采用 SELF-INSTRUCT 的 Code Alpaca 僅依賴于 21 個種子任務,使用相同的提示模板生成新的代碼指令。而 Code Evol-Instruct 以 Code Alpaca 為種子,僅依賴于 5 個啟發式方法來演化數據集。如 Yu et al.,2023 和 Wang et al., 2023a 論文中所提到的,這樣的方法可能會明顯繼承 LLM 中固有的系統偏見以及預定義任務。
在本文中,來自伊利諾伊大學香檳分校(UIUC)的張令明老師團隊提出了 OSS-INSTRUCT,用以減少 LLM 的固有偏見并釋放它們通過直接從開源學習創造高質量和創造性代碼指令的潛力。

- 論文地址:https://arxiv.org/pdf/2312.02120.pdf
- 項目地址:https://github.com/ise-uiuc/magicoder
- 試玩鏈接:https://huggingface.co/spaces/ise-uiuc/Magicoder-S-DS-6.7B (貪吃蛇 / 奧賽羅 /…)
如下圖 1 所示,OSS-INSTRUCT 利用強大的 LLM,通過從開源環境收集的任意隨機代碼片段中汲取靈感,自動生成新的編碼問題。在這個例子中,LLM 受到來自不同函數的兩個不完整代碼片段的啟發,成功地將它們關聯起來并創造出了逼真的機器學習問題。
由于現實世界近乎無限的開源代碼,OSS-INSTRUCT 可以通過提供不同的種子代碼片段直接產生多樣化、逼真且可控的代碼指令。研究者最終生成了 75,000 條合成數據來微調 CODELLAMA-PYTHON-7B,得到 Magicoder-CL。OSS-INSTRUCT 雖然簡單但有效,與現有的數據生成方法正交,并可以結合使用以進一步拓展模型編碼能力的邊界。因此,他們持續在一個包含 110,000 個條目的開源 Evol-Instruct 上微調 Magicoder-CL,產生了 MagicoderS-CL。

研究者在廣泛的編程任務中對 Magicoder 和 MagicoderS 進行評估,包括 Python 文本到代碼生成的 HumanEval 和 MBPP、多語言代碼生成的 MultiPL-E,以及解決數據科學問題的 DS-1000。他們進一步采用了 EvalPlus,包括增強的 HumanEval+ 和 MBPP + 數據集,用于更嚴格的模型評估。據實驗證實,在 EvalPlus 增強的測試下,ChatGPT 和 GPT-4 等代碼大模型的實際準確率比在之前在 HumanEval 和 MBPP 等廣泛使用數據集上的評估平均下降將近 15%。有趣的是,EvalPlus 同樣也是張令明老師團隊的近期工作,短短半年的時間已經被業界廣泛采納、并已經在 GitHub 上擁有 500 Star。更多模型在 EvalPlus 上的評估可以參考 EvalPlus 排行榜:https://evalplus.github.io/。
結果顯示,Magicoder-CL 和 MagicoderS-CL 都顯著提升基礎的 CODELLAMA-PYTHON-7B。此外,Magicoder-CL 在所有測試基準上都超過了 WizardCoder-CL-7B、WizardCoder-SC-15B 和所有研究過的參數小于或等于 16B 的 SOTA LLM。增強后的 MagicoderS-CL 在 HumanEval 上的 pass@1 結果與 ChatGPT 持平(70.7 vs. 72.6),并在更嚴格的 HumanEval + 上超過了它(66.5 vs. 65.9),表明 MagicoderS-CL 能夠生成更穩健的代碼。MagicoderS-CL 還在相同規模的所有代碼模型中取得了 SOTA 結果。
DeepSeek-Coder 系列模型在最近表現出卓越的編碼性能。由于目前披露的技術細節有限,研究者在第 4.4 節中簡要討論它們。盡管如此,他們在 DeepSeek-Coder-Base 6.7B 上應用了 OSS-INSTRUCT,創建了 Magicoder-DS 和 MagicoderS-DS。
除了與之前以 CODELLAMA-PYTHON-7B 為基礎模型的結果保持一致外,Magicoder-DS 和 MagicoderS-DS 還受益于更強大的 DeepSeek-Coder-Base-6.7B。這一優勢由 MagicoderS-DS 展示,其在 HumanEval 上取得了顯著的 76.8 pass@1。MagicoderS-DS 在 HumanEval、HumanEval+、MBPP 和 MBPP+ 上的表現同樣優于 DeepSeek-Coder-Instruct 6.7B,盡管微調 token 減少為 1/8。
OSS-INSTRUCT: 基于開源進行指令調優
從高層次來看,如上圖 1 所示,OSS-INSTRUCT 的工作方式是通過為一個 LLM(比如 ChatGPT)輸入提示,從而根據從開源環境中收集到的一些種子代碼片段(例如來自 GitHub)生成編碼問題及其解決方案。種子片段提供了生成的可控性,并鼓勵 LLM 創建能夠反映真實編程場景的多樣化編碼問題。
生成代碼問題
OSS-INSTRUCT 利用可以輕松從開源環境獲取的種子代碼片段。本文研究者直接采用 StarCoderData 作為種子語料庫,這是用于 StarCoder 訓練的 The Stack 數據集的過濾版本,包含以各種編程語言編寫的許可證允許的源代碼文檔。選擇 StarCoderData 的原因在于它被廣泛采用,包含了大量高質量的代碼片段,甚至經過了數據凈化的后處理。
對于語料庫中的每個代碼文檔,研究者隨機提取 1–15 個連續行作為模型獲得靈感并生成編碼問題的種子片段。最終共從 80,000 個代碼文檔中收集 80,000 個初始種子片段,其中 40,000 個來自 Python,還有 40,000 個分別平均來自 C++、Java、TypeScript、Shell、C#、Rust、PHP 和 Swift。然后,每個收集到的種子代碼片段都應用于下圖 2 所示的提示模板,該模板由教師模型作為輸入,并輸出編碼問題及其解決方案。

數據清理和凈化
研究者在數據清理時,排除了共享相同種子代碼片段的樣本。雖然在生成的數據中存在其他類型的噪聲(比如解決方案不完整),但受到了 Honovich et al. [2023] 的啟發,這些噪聲并未被移除,它們被認為仍然包含 LLM 可以學習的有價值信息。
最后,研究者采用與 StarCoder Li et al.,2023 相同的邏輯,通過刪除包含 HumanEval 和 MBPP 中的文檔字符串或解決方案、APPS 中的文檔字符串、DS-1000 中的提示或 GSM8K 中問題的編碼問題,對訓練數據進行凈化處理。事實上,凈化過程僅過濾掉了額外的 9 個樣本。由于種子語料庫 StarCoderData 已經經過嚴格的數據凈化,這一觀察結果表明 OSS-INSTRUCT 不太可能引入除種子之外的額外數據泄漏。最終的 OSS-INSTRUCT 數據集包含約 75,000 個條目。
OSS-INSTRUCT 的定性示例
下圖 3 的一些定性示例展示了:OSS-INSTRUCT 如何幫助 LLM 從種子代碼片段獲取靈感以創建新的編碼問題和解決方案。例如,Shell 腳本示例顯示了 LLM 如何利用一行 Shell 腳本創作一個 Python 編碼問題。庫導入示例演示了 LLM 如何使用幾個導入語句創建一個現實的機器學習問題。
與此同時,類簽名示例說明了 LLM 從具有 SpringBootApplication 等注釋和 bank 等關鍵詞的不完整類定義中獲取靈感的能力。基于此,LLM 生成了一個要求基于 Spring Boot 實現完整銀行系統的問題。
總體而言,OSS-INSTRUCT 可以激發 LLM 以不同的代碼結構和語義來創建各種編碼任務,包括算法挑戰、現實問題、單函數代碼生成、基于庫的程序補全、整個程序開發,甚至整個應用程序構建。
 為了研究 OSS-INSTRUCT 生成的數據的類別,研究者使用了 INSTRUCTOR,這是 SOTA embedding 模型之一,可以根據任務指令生成不同的文本 embedding。受到了 OctoPack 和 GitHub 上主題標簽的啟發,研究者手動設計了 10 個與編碼相關的特定類別。如下圖 4 所示,他們計算了 OSS-INSTRUCT 中每個樣本的 embedding 與這 10 個類別的 embedding 之間的余弦相似度,以獲取類別分布。總體而言,OSS-INSTRUCT 在同類別之間表現出多樣性和平衡。
為了研究 OSS-INSTRUCT 生成的數據的類別,研究者使用了 INSTRUCTOR,這是 SOTA embedding 模型之一,可以根據任務指令生成不同的文本 embedding。受到了 OctoPack 和 GitHub 上主題標簽的啟發,研究者手動設計了 10 個與編碼相關的特定類別。如下圖 4 所示,他們計算了 OSS-INSTRUCT 中每個樣本的 embedding 與這 10 個類別的 embedding 之間的余弦相似度,以獲取類別分布。總體而言,OSS-INSTRUCT 在同類別之間表現出多樣性和平衡。

下圖 5 中展示了生成的問題和解決方案的長度分布。橫軸表示每個問題 / 解決方案中的 token 數量,縱軸表示相應的樣本數量。

為了研究數據生成過程是否產生更多的類 HumanEval 問題或解決方案,研究者將 75,000 個數據集中的每個樣本與 164 個 HumanEval 樣本中的每個樣本配對,并使用 TF-IDF embedding 計算它們的余弦相似度,然后將每個 OSS-INSTRUCT 樣本與具有最高相似度分數的 HumanEval 樣本關聯。
研究者還分別將數據集與 Code Alpaca 和 evol-codealpaca-v1 進行比較 ,前者是一個在代碼任務上應用 SELF-INSTRUCT 的 20K 數據集,后者是 Evol-Instruct 的一個包含 110K 編碼指令的開源實現。由于官方的 Code Evol-Instruct 數據集尚未發布,研究者使用開源實現。他們還使用了與第 2.2 節中討論的相同方式對所有數據集進行凈化。
下圖 6 結果顯示,OSS-INSTRUCT 在所有研究的數據生成技術中表現出最低的平均相似性,而 SELF-INSTRUCT 顯示出最高的平均相似性。這一發現表明,OSS-INSTRUCT 的改進并不僅僅是由于包含了來自相同分布的數據。

評估
Python 文本到代碼生成
下表 1 展示了不同基準測試上,不同 LLM 在 pass@1 上的結果。從結果中首先可以觀察到,Magicoder-CL 相較基礎 CODELLAMA-PYTHON7B 有明顯的改進,并且除了 CODELLAMA-PYTHON-34B 和 WizardCoder-CL-34B,在 HumanEval 和 HumanEval + 上優于所有其他研究過的開源模型。
值得注意的是,Magicoder-CL 超過了 WizardCoder-SC-15B,并且在 HumanEval 和 HumanEval+ 上相對于 CODELLAMA-PYTHON-34B 有了明顯的提升。通過使用正交的 Evol-Instruct 方法進行訓練,MagicoderS-CL 進一步實現改進。MagicoderS-CL 在 HumanEval + 上優于 ChatGPT 和所有其他開源模型。
此外,雖然在 HumanEval 上分數略低于 WizardCoder-CL-34B 和 ChatGPT,但在更嚴格的 HumanEval + 數據集上超過了它們,表明 MagicoderS-CL 可能生成更為穩健的代碼。

多語言代碼生成
除了 Python 外,研究者在下表 2 中對 Java、JavaScript、C++、PHP、Swift 和 Rust 等 6 種廣泛使用的編程語言進行了全面評估,使用的基準測試是 MultiPL-E。

結果表明,在所有研究的編程語言中,Magicoder-CL 相對于基礎的 CODELLAMA-PYTHON-7B 有著明顯的改進。此外,Magicoder-CL 在半數以上的編程語言上也取得了比 SOTA 15B WizardCoder-SC 更好的結果。此外,MagicoderS-CL 在所有編程語言上進一步提高了性能,在只有 7B 參數的情況下實現了媲美 WizardCoder-CL-34B 的性能。
值得注意的是,Magicoder-CL 僅使用了非常有限的多語言數據,但仍然優于其他具有相似或更大規模的 LLM。此外,盡管評估框架以補全格式評估模型,但 Magicoders 仍然表現出明顯的改進,盡管它們只進行了指令微調。這表明 LLM 可以從其格式之外的數據中學習知識。
用于數據科學的代碼生成
DS-1000 數據集包含來自 Python 中 7 個流行數據科學庫的 1,000 個不同的數據科學編碼問題,并為驗證每個問題提供單元測試。DS-1000 具有補全和插入兩種模式,但在這里僅評估補全,因為基礎 CODELLAMA-PYTHON 不支持插入。
下表 3 顯示了評估結果,其中包括了最近的 INCODER、CodeGen、Code-Cushman-001、StarCoder、CODELLAMA-PYTHON 和 WizardCoder。
結果表明,Magicoder-CL-7B 優于評估的所有基線,包括最先進的 WizardCoder-CL-7B 和 WizardCoder-SC-15B。MagicoderS-CL-7B 通過在 WizardCoder-SC-15B 的基礎上引入 8.3 個百分點的絕對改進,進一步突破了極限。

與 DeepSeek-Coder 的比較
DeepSeek-Coder 是最近發布的一系列模型,展示了卓越的編碼性能。由于在撰寫時其技術細節和指令數據尚未公開,因此這里簡要討論它。研究者在 DeepSeek-Coder-Base-6.7B 上采用了與在 CODELLAMA-PYTHON-7B 上執行的相同微調策略,得到了 Magicoder-DS 和 MagicoderS-DS。
下表 4 顯示了與表 1 相似的趨勢,即在應用 OSS-INSTRUCT 后,基礎模型可以顯著改進。值得注意的是,MagicoderS-DS 變體在所有基準上均超過 DeepSeek-Coder-Instruct-6.7B,而且訓練 token 數量減少至 1/8,它還在這些數據集上與 DeepSeek-Coder-Instruct-33B 表現相當。

更多技術細節和實驗結果請參閱原論文。
團隊介紹
這篇論文的作者均來自伊利諾伊大學香檳分校(UIUC)張令明老師團隊,包括:魏宇翔,二年級博士生,研究方向是基于 AI 大模型的代碼生成;王者,科研實習生,目前為清華大學大四學生,研究方向是機器學習和自然語言處理;劉佳偉,三年級博士生,研究方向是編程系統和機器學習;丁一峰,二年級博士生,研究方向是基于 AI 大模型的自動軟件調試。張令明老師現任 UIUC 計算機系副教授,主要從事軟件工程、機器學習、代碼大模型的相關研究,更多詳細信息請見張老師的個人主頁:https://lingming.cs.illinois.edu/。




























