













在我們為面向客戶的聊天應用制作大語言模型 (LLM)時,預訓練模型往往是很好的起點,但隨著時間的推移,您可能希望去控制該模型聊天的整體行為和給客戶帶去的“感覺”,而不僅僅由基本模型所能提供。對此,我們雖然可以通過提示工程(prompt engineering)來實現,但是它會嚴重限制聊天輸入的長度,而且每次推理調用的成本都會增加。目前,另一種更有效的方法是在數據集上對模型進行微調,并在模型中灌輸新的行為模式。

微調Mistral 7B模型
下面,我們將引導您微調Mistral7B的開源LLM。為此,我們會調用MindsDB與模型進行交互,并使用Anyscale Endpoints對其進行托管。如果您需要微調其他模型的話,其過程將十分類似。
什么是MindsDB?
作為一個面向開發人員的開源人工智能(AI)平臺,MindsDB可以將AI/ML模型與實時數據相連接。由其提供的工具和自動化功能,可輕松地構建和維護個性化AI方案。MindsDB提供了數百種與各種數據源、API和ML框架的集成。借助該平臺,您可以將最先進的AI模型(如OpenAI、LLama2、Cohere、Mistral等)與數百種數據源(包括企業級數據庫,以及PostgreSQL、MongoDB、Snowflake、Slack、Shopify等第三方應用)整合在一起。
什么是Anyscale?
Anyscale是支持ChatGPT等世界頂尖AI產品的Ray框架的創建者。由其提供的Anyscale Endpoints可以輕松地以快度、低成本的方式,優化訪問Mistral 7B等開源LLM。
微調模型
下面,我們會把微調后的模型與其原始版本進行比較,檢查其輸出行為上的差異,并解釋其背后原因。
步驟 1:準備好先決條件
- 請在您的機器上本地部署MindsDB。
- 請確保安裝了Anyscale Endpoints集成。
- 此外,您還需要注冊Anyscale Endpoints。
步驟 2:加載數據
我們將使用由鏈接--https://huggingface.co/datasets/b-mc2/sql-create-context?ref=hackernoon.com提供的數據集。其中包含了“上下文-問題-答案”三元組。它們將針對SQL表的原始查詢,與用戶提出的自然語言問題,以及返回該用戶所需信息的基本答案聯系起來。
盡管該數據集包含了7萬多個示例,但是我們在此只考慮前300個。我們會將數據重新排列成“長”格式,并將“對話/聊天”垂直堆疊成行。也就是說,每一行都有一條“內容”信息和一個“角色”。此處的角色可以是“系統”、“助手”(我們的模型)或“用戶”。
那么在每個“系統”行的內容中,我們都定義了如下內容:
- 其任務是將問題轉化為SQL查詢
- 相關的SQL表會創建參考語句
據此,輸入以下內容即可輕松地檢查到相關數據:
SELECT * FROM example_db.demo_data.anyscale_endpoints_ft_sample_data LIMIT 10;下圖展示的是從Postgres數據庫示例中檢索到的一個樣本:
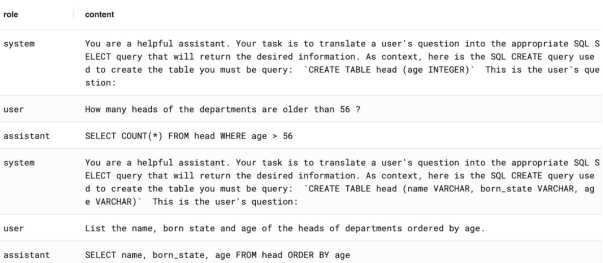
請注意,助手的回答就是詢問,沒有任何附帶解釋。這就是我們希望觀察到的原始基礎模型的主要效果。下面,讓我們來設置一下。
步驟 3:設置基本模型
1.在MindsDB項目中創建一個Anyscale集成的實例:
CREATE ML_ENGINE anyscale_endpoints FROM anyscale_endpoints;2.用它創建一個初始的Mistral 7B模型(這里使用的具體模型名稱是mistralai/Mistral-7B-Instruct-v0.1):
CREATE MODEL ft_sql
PREDICT answer
USING
engine = 'anyscale_endpoints',
model_name = 'mistralai/Mistral-7B-Instruct-v0.1',
prompt_template = '{{content}}',
api_key = 'your-api-key-here';3.您可以通過如下語句,查詢模型并從中得到答案:
SELECT answer FROM ft_sql WHERE content = 'hi!';4.讓我們以如下方式提問,從原始數據集的諸多示例中獲取一個:
SELECT answer FROM ft_sql WHERE content = 'Hi! I have created a SQL table with this command: “CREATE TABLE employees (country VARCHAR)”. How should I query my database to know how many employees are living in Canada?';您應該得到如下回復:

雖然上述答案是正確的,但是有些冗長。如果要在更廣泛的軟件應用(如代碼協同引導程序)中部署該模型,則需要有更簡潔的輸出。
在此,我們需要強調的是,雖然取決于多種變量,但是在預先訓練好的大語言模型上執行微調的主要效果,就是要影響模型的整體行為和排列,而不是完美地記憶新示例中包含的所有事實信息。相反,如果您需要提取存儲在其他地方的特定真實數據,那么您最好使用RAG設置。這兩種技術并不互斥,您完全可以同時使用兩者。
步驟 4:微調模型
5.有了現成的數據集,再加上MindsDB和Anyscale Endpoint的簡易性,我們只需如下一條SQL命令就能對Mistral 7B模型進行微調了:
FINETUNE ft_sql FROM example_db (
SELECT * FROM demo_data.anyscale_endpoints_ft_sample_data LIMIT 300
);6.該命令將觸發Anyscale Endpoints平臺上的微調運行。由于模型有70億個參數,而數據集較小,因此該過程可能需要15分鐘左右的時間。
如下圖所示,您將會在注冊Anyscale Endpoints時使用過的電子郵箱中收到通知。之后MindsDB模型也會顯示為已準備就緒的狀態。
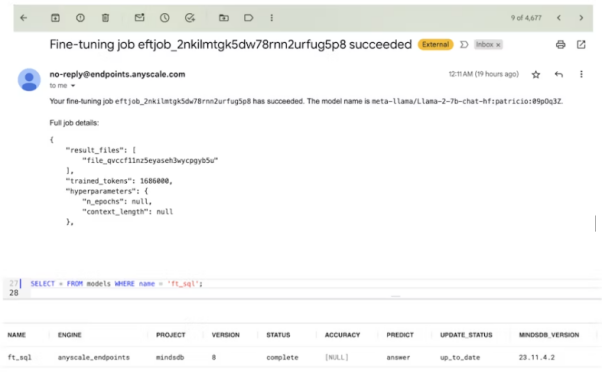
下圖展示了由其建立的可視化管道:

由于Mistral 7B是一個基于“transformer”架構的大型神經網絡,因此對其進行“監督微調”可以被理解為:對預先訓練好的基礎模型的某些權重稍作修改。具體做法是:在部分新的數據上最小化誤差指標,同時兼顧較低的學習率等因素。
而且,與基礎預訓練階段相比,其根本的區別就在于數據是有標簽的,而不是無標簽的(標簽提供了“監督”)。從上述步驟可知,我們提供了一個理想“助手”的預期回答,這將為訓練過程提供參考信息,以獲得一個比原始模型更善于生成答案的模型。
接著,我們來試著對模型提出如下問題:
SELECT answer FROM ft_sql WHERE content = 'Hi! I have created a SQL table with this command: “CREATE TABLE employees (country VARCHAR)”. How should I query my database to know how many employees are living in Canada?';與之相對應的答案(answer)列輸出會顯示為:SELECT COUNT(*) FROM employees WHERE country = "Canada"。顯然,這要簡潔得多。
由于MindsDB具有自動模型版本控制功能,因此您可以通過MODEL_NAME.VERSION訪問以前的模型版本。下面是我們針對.1版本通過重新輸入來觸發。它將給出與第3.d節類似的答案。
SELECT answer FROM ft_sql.1 WHERE content = 'Hi! I have created a SQL table with this command: “CREATE TABLE employees (country VARCHAR)”. How should I query my database to know how many employees are living in Canada?' USING max_tokens=1000;需要進一步說明的是,雖然微調后的模型確實表現出了較大的不同,但是我們仍有必要根據經驗來檢查準確度指標,畢竟眾所周知,LLM需要通過“空間(space)”來產生更好的答案。此處的空間是以詞塊來衡量的,它直接會導致更長的回答。這就意味著,根據任務的不同,冗長的答案可能會更難解析。不過,這實際上可能是提高下游任務準確性的一種理想特性。
步驟 5:提示工程
此處還有一個有趣的現象。正如OpenAI在發布GPT-2時所展示的那樣,大語言模型可以有效地在“上下文”中學習,也就是所謂的“提示”。這正是為什么提示工程在建立LLM管道時,被描述為絕對關鍵的原因。事實表明,一個精心挑選的上下文實例所產生的影響,可能不亞于數十或數百個對模型進行微調的特定實例。
下面,讓我們再次使用基本模型,并修改為“提示”方式,使得讀取方式略有不同:
CREATE MODEL ft_sql_succinct
PREDICT answer
USING
engine = 'anyscale_endpoints',
model_name = 'mistralai/Mistral-7B-Instruct-v0.1',
prompt_template = 'Answer with the correct SQL query only, no explanations whatsoever. Here is the question: {{content}}';顯然,如果使用相同的內容輸入去查詢該模型,就會得到“SELECT COUNT(*) FROM employees WHERE country = 'Canada';”這正是我們想要的效果,也說明了:對于簡單的情況,良好的提示模板可以起到顯著的作用。
什么時候使用提示工程?
大多數LLM提供者都會建議我們在進行任何微調之前,先進行提示工程的設計。而真正在進行微調時,您可以在某處生成一組新的模型。上文演示的MindsDB+Anyscale 技術棧雖然能夠處理基礎架構的開銷,但與推理時可用于基礎模型的單個靈活提示相比,則會引入額外的訓練和服務問題等更高的運行成本。
反過來說,如果您有大量的數據需要微調,或者由于某種行為限制,使得提示工程無法滿足您的要求的話,那么微調就會成為一種更有吸引力的選擇。例如,您的基本模型可能有一個特別短的token限制(如:總共只有2K的token)。
當然,如前所述,如果您需要模型能夠回憶各種事實情況,那么RAG則是必要的補充。它將能極大地幫助模型避免編造信息。
小結
在上文中,我們討論了MindsDB和Anyscale Endpoints是如何以一種經濟高效且簡單的方式,將開源大模型與數據進行微調。同時,我們也探討了微調對模型行為的影響,以及微調與提示工程的關系。希望上述內容對您有所幫助,祝您的項目取得成功。
原文標題:Fine-Tuning Mistral 7B: Enhance Open-Source Language Models with MindsDB and Anyscale Endpoints,作者: Jorge Torres






























